In praise of “boring” technology
In this article I will explain how Spotify uses different mature and proven technologies in our backend service eco-system and architecture, and why we do so. In addition, this article will also attempt to explain when Spotify has chosen not to use certain proven technologies, the reasons why and the associated pitfalls associated with each.
More often than not, the right tool for the job is piece of software that has been around for some time, with proven success. One example would be writing a backend service in Java or Python instead of Go or Node.JS. Another example would be storing data in MySQL or PostgreSQL instead of MongoDB or Riak.
Mature technology
Most people reading this article will probably have an intuitive feel for what “mature technology” means given the above example, but I’d like to be more explicit, especially for what mature technology means in the context of selecting “the right tool”.
A good rule of thumb of a mature technology is how well it can work as a black box for your specific use case. If you constantly have to fiddle around with the code, then we can say that the project is not as mature as a project where you rarely, if ever have to patch the software.
This is important because “the right tool for the job” has an economic and temporal aspect: for example, one storage solution may make sense for your current load and the resources you have for configuring and tweaking it, whereas a different storage solution may be the right tool in the future when you have more users and higher load.
DNS and Bind
At Spotify we use DNS heavily. When most people think of DNS they think of A records, used to map a hostname to an IPv4 address. However, DNS can be so much more than a “phone book”. It is actually better to think of DNS as a distributed, replicated database tailored for read-heavy loads.
DNS for service discovery
Service discovery is a fairly large subject but in essence it boils down to answering the question: what servers run this service (given some description or name of a service)?
At Spotify we have solved this problem with DNS for a long time. Specifically, we use so called SRV records. A DNS SRV record is a canonical name, typically of the form _name._protocol.site, mapped to a list of hostnames with weight, priority and port number.
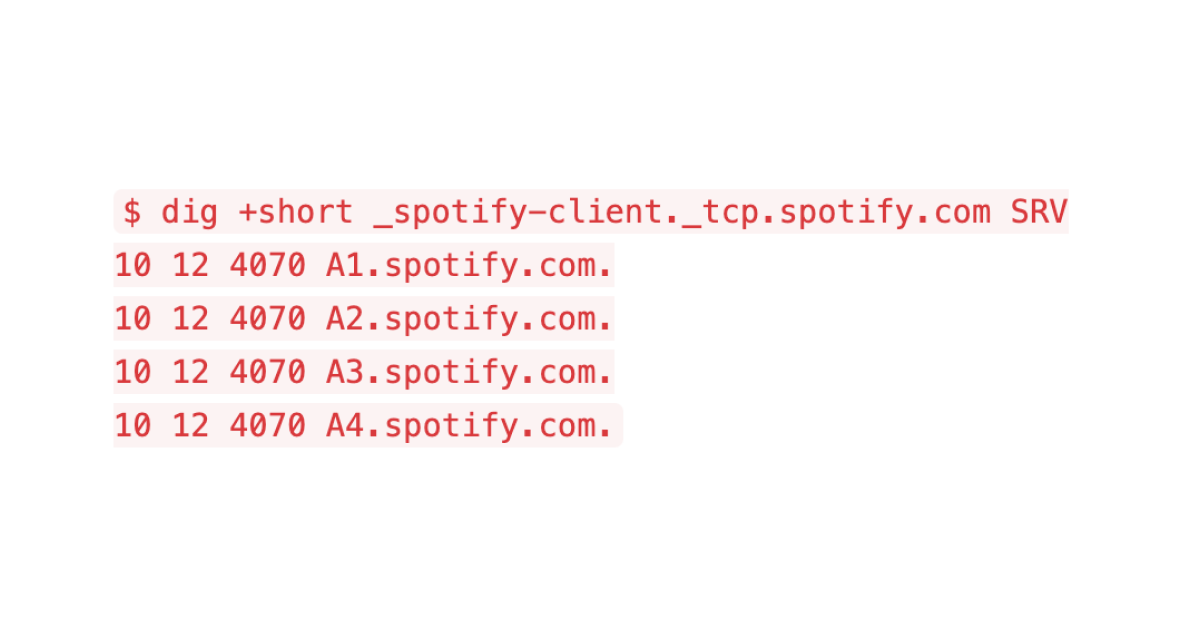
For example, when the Spotify client connects to the Access Point (which is the client’s connection to the Spotify backend) it looks up the SRV record _spotify-client._tcp.spotify.com. The APs do something similar for each backend service the AP will send requests to.
$ dig +short _spotify-client._tcp.spotify.com SRV
10 12 4070 A1.spotify.com.
10 12 4070 A2.spotify.com.
10 12 4070 A3.spotify.com.
10 12 4070 A4.spotify.com.The fields given above are, in order, the priority, the weight, the port number and the host. The user of a service should pick servers proportional to the weight, in the group of servers with the highest priority. Only when all servers are down should requests be sent to the servers with lower priority.
In the example above, all four hostnames have the same priority (10) and the same weight (12) so in a correctly configured environment they will get roughly 25% of all traffic, each.
All backend services powering Spotify can be discovered by asking for the correct SRV record, and this is how the services find each other. For cases when DNS is not appropriate, such as externally visible web services, we have developed HTTP facades in front of DNS. For instance, some clients will send a HTTP request to figure out which Access Point to connect to.
In some (rare) cases, Spotify also use CNAME and PTR records in addition to SRV records. This is typically when a single server has some particular purpose. For example, we use a PTR record to locate the write master in one of our database clusters.
For administrative purposes, many tools and other infrastructural projects have been developed. One example is command line utilities that make SRV lookups easier. We also have a web service that works as a DNS cache that has some interesting features, such as reverse lookups (mapping a hostname to a service name).
Configuration management
As DNS is a high performance distributed database, we also use it for storing some service configuration data. In particular, we store DHT ring information in TXT records.
$ dig +short +tcp _spotify-tracker-internal._hm.lon.spotify.net SRV | sort | head -n 4
5000 5000 4301 lon2-tracker-a1.lon.spotify.net.
5000 5000 4301 lon2-tracker-a2.lon.spotify.net.
5000 5000 4301 lon2-tracker-a3.lon.spotify.net.
5000 5000 4302 lon2-tracker-a1.lon.spotify.net.$ dig +short +tcp config._spotify-tracker-internal._hm.lon.spotify.net TXT
"slaves=:0" "hash=sha1"$ dig +short +tcp tokens.4301.lon2-tracker-a1.lon.spotify.net. TXT
"0555555555555555555555555555555555555555"
"8555555555555555555555555555555555555555"The data in these services has a particular key that, when hashed, exists at some point in a ring which size is governed by the number of bits in the hash used. The servers in the ring are responsible for certain segments of the ring. In our case, the server owns the data from the “token” given, and (typically) counterclockwise up to the next token.
When there are multiple replicas, a function is used to find which server owns the replica. A simple function would be that the first replica is at the next segment of the ring. To get a more consistent hash, we sometimes use the power hash function H^n(key), where H is the hash function and n is the replica number (so the first replica lives in the server owning the token hash(hash(key))).
Infrastructural support and administration
To support our DNS infrastructure we use a few different open source projects, including dnspython, dnsjava and c-ares which are DNS resolvers (clients) for Python, Java and C respectively.
Our DNS servers run Bind and many of the backend services run Unbound which is also a DNS server. The use of Unbound is to improve performance and reduce load of the main DNS servers.
We have a git (previously subversion) repository where we maintain the DNS zone files. We have a small Makefile we run on the DNS master to deploy the changes from the git repository. The deploy will push the changes to the DNS slaves running in our different data centers.
This setup has been mostly unchanged since the initial beta launch in 2007. And it has scaled surprisingly well, handling thousands of servers, dozens of services and tens of millions of users.
Corollary: Zookeeper
It is only recently that Spotify has started to outgrow DNS for service discovery. There are several reasons for this, and again service discovery is a large subject and will likely be discussed in more detail in a later blog post. To get an idea, here are some problems:
The administrative overhead of managing DNS zone files during new hardware provisioning is fairly high.
DNS provides a static view of the world (“these are the servers that are supposed to be running”). As our server park gets larger, having a dynamic registry becomes increasingly more useful and important (“these are the servers that are actually, up and running, right now”).
We have not yet (as of January 2013) started implementing a replacement. We are looking into using Zookeeper as an authoritative source for a static and dynamic service registry, likely with a DNS facade.
PostgreSQL
Historically, Spotify has been a heavy user of PostgreSQL. Since the very first versions of the Spotify backend it has been our go-to relational database and the default choice for persistent storage – when it works.
PostgreSQL is a very good example of highly mature technology. Unless you overload Postgres, It “just works”, without having to mess around with, or even understand the source code. The PostgreSQL Handbook is one of the finest examples of documentation of an open source project in the world.
In the beginning of Spotify, when load was lower, PostgreSQL was definitely the right tool for the job.
Replication and failure handling
In the beginning Spotify used PostgreSQL version 8. To handle server failures, we of course used the replication features of the database. Back then this meant having a warm standby that ingested WAL segments. In case the database machine died, we could fail over to the warm standby.
To make this process easier, we developed a command line utility, pgws, that makes it easy to set up the primary server, standby and do operations on them, such as promoting the standby to primary.
Later came Postgres 9 and with it the excellent streaming replication and hot standby functionality. One of the most important database clusters at Spotify, the cluster that stores user credentials (for login), is a Postgres 9 cluster. We have one master server responsible for writes, and several hot standbys that take all the read requests.
To manage these machines, we adapted pgws, so now we have a utility called pghs instead. We have also written infrastructure libraries that can decide which database slave to use in an intelligent fashion – the library keeps track of node health, will pick up new nodes from DNS and stop sending requests to servers that have been removed from DNS (or have too low health).
Infrastructure
As goes with mature technology, surrounding technologies are mature as well. Spotify is a heavy user of the excellent psycopg2 library for Python. We used to have services using sqlalchemy and similar projects, but we quickly started writing our own SQL to psycopg2 to get a better control and understanding of our environment.
To reduce the number of connections to our PostgreSQL servers we have recently started using pgbouncer, which is a connection pooler. The architecture of Postgres is to fork a new process for each connection, so having a connection pooler help reduced server resource usage.
Danger zone: running out of IOPS
By 2009, Spotify had grown to the point where server load was increasingly problematic and as with any storage solutions and disk subsystem, poor performance can have a significant impact. Good load balancing and replication is crucial for scalability. You can scale up Postgres 9 using the hot standby functionality for example, and you can also deploy different storage solutions.
Corollary: Cassandra
The reason we use Cassandra is not that it is hip new technology, it’s because we found it to be the right tool for us, both economically and temporary tactical solution (as described above).
We have one person that works full time hacking Cassandra to adapt it to our use case. As Cassandra is not as mature as PostgreSQL, and is not as much of a black box, this is required for successful Cassandra deployments in a production environment.
What we gain from this is a setup that behaves better in some specific use cases, which is important as we deploy on more data centers and more servers.
A properly administered Cassandra cluster has better replication (especially writes).
A properly administered Cassandra cluster behaves better in the presence of networking issues and failures, such as partitions or intermittent glitches.
In general, Cassandra behaves better in certain classes of failures (server dies, network links goes down etc) from an operational perspective, than a PostgreSQL cluster.
Note that these are relatively new problem for Spotify and a lot of these issue did not exist a just a couple of years ago. Using Cassandra back then for example would have been the wrong tool for the job.
Summary
In this article we have looked at DNS and PostgreSQL, two excellent technologies that have been, and continue to be, integral to the Spotify backend eco-system. We also briefly touched on more recent projects – Zookeeper and Cassandra – which we are now using with great success.
If you find this blog article interesting, Spotify is hiring.
SHARE THIS ARTICLE



