Incident Management at Spotify
A few weeks ago Spotify had one of the biggest incidents in the last few years. It caused a major outage for a big chunk of our European users. For a few hours the music playback experience was damaged. Our users would see high latency when playing music and some of them were unable to log in.
At Spotify we take these types of incidents seriously. Our mission when dealing with outages is to avoid having the same incident twice. We want to be able to learn something new with each incident. However, sometimes we fail.
First symptoms: two months before the outage
Two months before the big outage we had an incident connected with one of our smallest backend services: Popcount. Popcount (this is our internal name) is the service that takes care of storing the list of subscribers for each of our more than 1 billion playlists.
All our backend services and clients that communicate with Popcount are designed to fail fast in the event that the service is not available or too slow. Failing fast is key to scaling. We try to build our systems in such a way that partial failures are handled gracefully. For instance, it is better not to display the list of playlist subscribers for a while than to delay showing playlist data for a long time, completely damaging the user experience.
However, there was a piece of legacy code in our desktop client that did not honor that requirement. That particular code caused our clients to retry fetching Popcount information for every request that timed out. To make matters worse, the legacy implementation had no backoff logic at all. This put a lot of pressure on the Popcount service and made it reach a state where servers were overwhelmed in such a way that recovery was almost impossible: the slower the service became, the more requests it started receiving. Turning it off wouldn’t have helped either: the amount of pending requests coming from our clients was too big to be served without damaging the service again.
The Popcount developers quickly deployed a fix: in the event that the service became slow, we would fast fail and return an empty list of subscribers. With that fix in place, our Popcount system started making forward progress and very soon our clients went back to normal.
Remediations: why are they important?
For every incident we hold a post-mortem meeting. The goal of this meeting is producing a list of remediations that we need to put in place in order to prevent that incident from happening again and assign an urgency to each of them. We invite all the teams that are connected with a system involved in the given incident. If the severity of an incident is minor or it is connected with a very isolated part of our infrastructure, the post-mortem meetings are limited to a few key engineers. Post-mortem meetings are not about blame, they are about improving our systems and our processes!
One of the remediations for the Popcount incident was fixing the faulty retry behavior in our desktop client when fetching data from the Popcount system.
Distributed systems are hard, prioritizing bugs and assigning the right urgency is often non-obvious. There are many challenges we face when we release software to millions of users, and sometimes assessing the relative urgency of a fix is not easy. In this particular case, we focussed in the mitigations (fast fail behavior in Popcount) instead of in the root cause (the client bug).
We did not set the proper priority for the bugfix, and, guess what…
The night of April 27th
It was a rainy Saturday night in Stockholm. Some of our engineers were online on IRC, and discovered that Popcount was unhealthy again. We thought the fast fail logic we introduced in Popcount a few weeks before would prevent Popcount from dying again.

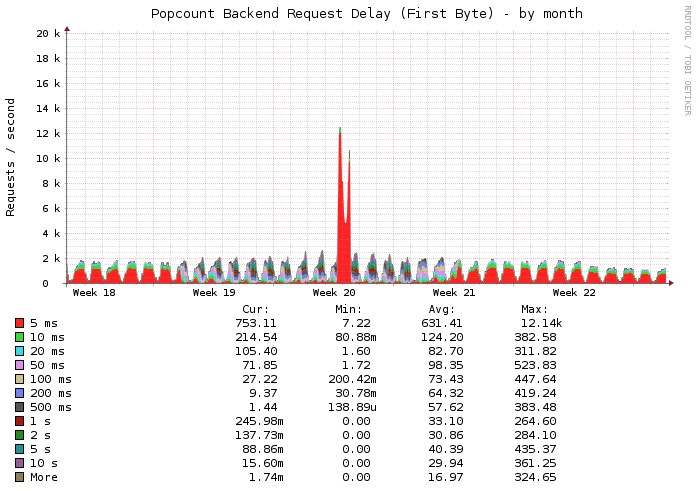
Request delay for Popcount in one of our Datacenters
What happened? Why was Popcount being hammered with requests again? A few days earlier we started rolling out our new cool Discovery feature to a percentage of our users. We had unknowingly added a dependency between our Discovery service (Bartender is our internal name) and Popcount. Some of the content we display in our discovery page display playlist counts, hence the Bartender service was fetching data directly from Popcount. The fast fail logic we introduced before did not help much: the service was getting more requests than it could handle. We realized too late that Popcount was underprovisioned.
Our Site Reliability and Infrastructure teams thought that removing that dependency via a hotfix would solve the problem. But we were wrong.
By the time we applied the fix, the Popcount request queues in our Accesspoints (the servers our clients connect to) had built up and some excessive logging in the Accesspoints making them die like flies. We intentionally had added more verbose logging of errors for debugging purposes, and we managed to shoot ourselves in the foot with it. Their I/O responsiveness was nonexistent and the wrong retry behavior in our desktop clients was making things worse and worse. Saturday night is usually a very busy night for our servers, and that did not help either.
By that time our service was notably degraded and we were in a situation where most of our Accesspoints were unreachable or responding extremely slowly. It was time for drastic measures.
We needed to do something to allow them to start breathing and the only possible solution was firewalling them off. Some of them were so unresponsive that we had to perform a hard reset before applying the necessary firewall rules. A few minutes later, things were responsive again. We removed the firewall blocks and the service started working smoothly as usual.
Why did that help? Well, our clients have a nice retry behavior when they are disconnected from the Accesspoints. They have an exponential backoff logic and offlining those servers for a while triggered the backoff that helped us make forward progress.
Lessons learned
We should have prioritized fixing the backoff bug in the client after the first Popcount incident, we did not assign the right severity. We thought having the fast fail mechanism in place would be enough to keep the service up in case we experienced high latencies.
Logging is nice, but logging too much can be damaging when many error messages or warnings are produced.
We should spend more time testing extreme cases (high latency, low bandwidth) for our backend systems
Sometimes, things you do to try to understand problems better (adding extra logging, to name one) can really come back to bite you.
Remediations in place after the second incident
After the outage (infamously known as OPS-6000 in our incident tracking system), we held a post-mortem meeting where we invited the entire Technology and Product departments. Many people had the opportunity to attend a post-mortem meeting for the first time.
We came up with a list of remediations, all of them are in place now. Some of them:
All the data served by our discovery service should be statically cached with a TTL.
Fix the faulty retry behavior for Popcount in our desktop client.
Move valuable Accesspoint log messages into a separate log. In case we hit a similar IO problem in the future, we can easily discard non important messages. We also introduced rate limiting for those messages.
Implement some syslog fixes to prevent too frequent flushes to disk.
Educating the company on why and how we failed is just as important as the fixes (it was even a remediation for this incident).
SHARE THIS ARTICLE



