Shaving off 50% waiting time from the iOS Edit-Build-Test cycle
For the impatient
If you don’t want/don’t have time to read the full story, you should at least consider using the following build settings during your iOS development cycle (i.e. for non-release builds):
Use plain “DWARF” instead of “DWARF with dSYM File” as your “Debug Information Format”.
Don’t compile your project code or use static libraries compiled with -O4 since it tells Clang to enable Link Time Optimizations (LTO) making the linking stage much slower. Use -O3 at most.
These changes were recently incorporated to our iOS codebase and made quite a big difference.
The problem
Last week I attended Spotify’s internal mobile bootcamp, a week-long introduction to the development of our mobile clients. The purpose of this bootcamp is to get its attendees up to speed with our apps, so that every developer, with or without prior mobile experience, can make their way changing code or adding new features. I took part in the iOS variant of the course.
The bootcamp was particularly interesting for a developer like me, with virtually no iOS development experience. However, during the course of the week I often got frustrated while waiting for XCode to finish building. Everytime I pressed
 to test my changes I couldn’t help getting frustrated by what seemed like an endless waiting loop. For non-experts like me, who often need to resort to trial-and-error, the situation was particularly bad.
to test my changes I couldn’t help getting frustrated by what seemed like an endless waiting loop. For non-experts like me, who often need to resort to trial-and-error, the situation was particularly bad.
Reducing the build time seemed like an interesting problem to tackle and a good opportunity to learn a bit about OSX internals. So, I decided to give it a go and, fortunately, I came up with a noticeable improvement: I reduced the waiting time by 50%.
The solution
My development use-case (and the most common one out there) is:
Change a few source files.
Press
 in XCode.
in XCode.Observe the result in phone/simulator (the simulator in my case).
Goto 1
 in XCode.
in XCode.After modifying a rather small Objective C source file from Spotify’s iOS client, I measured how long it took to get from step (2) to step (3), until I could see the application loaded in the simulator: 82 seconds (on average) in my (admittedly old) iMac at home.
From my interactive sessions with XCode I sensed that most of the time was spent in the “Linking” and ”Generating dSYM file” stages.


Making some measurements in the command line confirmed it. On average:
Linking took 29 seconds.
dSYM generation took 25 seconds.
The two stages entail (29 + 25) / 82 * 100 = 62 % of the waiting time. But, after all, Spotify’s iOS client codebase is quite big (the linker has to put around 2000 object files together) so, it was probably justified.
Well, not quite …
dSYM file generation
I must admit I didn’t know much about dSYM bundles, only that they contain debugging information. I was surprised to learn that dSYM started as a “cheap workaround” from Apple. The story is that, at the early stages of OSX, Apple didn’t wan’t to go through the hassle of introducing DWARF support in their linker. They created a separate linker for that purpose (dsymutil), which takes debugging information from object files and puts it in a common place: a dSYM bundle.
While dSYM bundles are useful for release builds, they are not needed during development. The debugger can obtain its debug information from the intermediate object files which are still hanging around after building.
XCode honours that possibility, allowing developers to set the “Debug Information Format” of your build to “DWARF” instead of “DWARF with dSYM File”.

Thus, simply changing one option in XCode reduced the waiting time in 25 seconds: nice!
Linking
Unfortunately, there is no magical option to skip linking. Well, you could skip it, but you would end up with a bunch of useless object files ?
Initially, I thought the only way I could reduce the 30 seconds (an eternity!) of linking time was to dig into Apple’s linker, Id64, and implement incremental linking. That task is not trivial so I first decided to profile Id64’s execution to look for low hanging fruit.
Apple provides the C++ source code of ld64, albeit a rather outdated version. I gave it a go, hoping there wouldn’t be fundamental differences with the latest version included in XCode. The sources don’t compile out-of the box, but with some help from Macports I could make a quick profile run with Instruments.
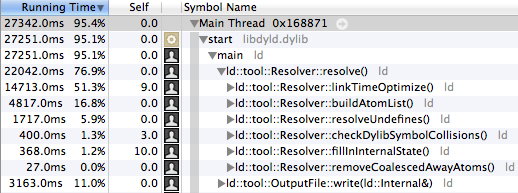
The screenshot excerpt above might not tell you much at first sight, but if you read ld64’s documentation, you will quickly conclude that ld::tool::Resolver::resolve() corresponds to the Resolving stage of ld64’s pipeline. In simple terms, this stage is in charge of putting the graph representation of each object file into a larger, global graph.
Loading the individual graphs for each object file happens at an earlier stage, so, in principle, there is no reason for resolving to be very costly and it certainly shouldn’t dominate execution (76.9% of it). That said, if you take a closer look, you can see see that ld::tool::Resolver::linkTimeOptimize() takes 51.3% of the linking time.
linkTimeOptimize() performs Link Time Optimizations (LTO). In the Clang/LLVM world, this implies that the linker is provided with LLVM bitcode files, not the usual object file. This bitcode represents programs at a higher abstraction level, allowing for LTO but, as a downside, it still needs to be translated to native code, requiring extra processing time at link time.
After adding some logging to ld64 and doing some further uninteresting digging, I managed to locate the offending bitcode files. They were part of a static library which, out of good will, had a -O4 compilation setting. Quoting Clang’s manual page:
-O4 enables link-time optimization; object files are stored in the LLVM bitcode file format and whole program optimization is done at link time.
I lowered the optimization flag to -O3 and voilà, the linker was 51% faster, saving around 15 seconds in each cycle.
Profit
With my old hardware I obtained an improvement of about 25 + 15 = 40 seconds per cycle (40 / 82 * 100 = 49 % of the waiting time). Let’s make a bold estimation of how much that saves.
Assuming:
A 2x improvement due to more recent hardware.
An Edit-Build-Test cycle every 10 minutes, per developer.
5 hours of development work per day, per developer.
This would save 40 seconds / 2 * (5 * 60 / 10) = 600 seconds = 10 minutes per developer/day.
In a big iOS shop like Spotify, for every 10 iOS developers, this saves around 1 hour and 40 minutes per day, completely for free (well, I spent a few hours figuring this out but that’s negligible).
These are just bold numbers, so take them with a grain of salt. I didn’t mean to make a rigorous benchmark.
Conclusion
Optimizing your building process truly pays off. It only requires spending some time on it once in a while, ideally only costing a few hours every few months. It saves a considerable amount of time and money. But, most importantly, it will make developers happier.
Future work
Optimizing the linking stage further is a hard problem since, unlike compiling multiple source files, it’s not inherently parallelizable. But, as I mentioned earlier, incremental linking is a well known approach. Google’s Gold linker supports incremental linking and it’s well documented (see this video for instance), but unfortunately it doesn’t support Mach-O and most probably never will. I may spend our next internal hack-week working on incremental linking for ld64, assuming Apple releases the latest source code by then.
It would also make sense to improve other work flows than Edit-Build-Test. Some developers change branches often, requiring a full build every time. Unfortunately, Apple removed support for distributed builds in XCode 4.3. I’ve already had some conversations about creating a binary version of Cocoa Pods, or even an source to object/library storage taking advantage of git hashes, but we’ll see.
Last, but no least, it would be interesting to look at our Android building flow.
SHARE THIS ARTICLE



