Date-Tiered Compaction in Apache Cassandra

For my master’s thesis, I developed and benchmarked an Apache Cassandra compaction strategy optimized for time series. The result, the Date-Tiered Compaction Strategy (DTCS), has recently been included in upstream Cassandra. We now use it in production at Spotify.
Marcus Eriksson has written another blog post about this feature on the DataStax Developer Blog.
What is a compaction strategy?
The data files that Cassandra nodes store on disk are called sorted string tables (SSTables). They are essentially plain sorted arrays of data. Cassandra’s superior performance lies in its log-structured storage; it recognizes just how much more expensive random seeks are compared to sequential operations on modern hardware. Granted, this difference is larger on hard disk drives than on solid-state drives. Still, keeping data from fragmenting holds fundamental importance to Cassandra’s overall performance.
A sorted array may seem like a primitive data structure, but it allows single-seek range queries. Since Cassandra is not interested in doing small writes to disk, the terrible cost of insertions into sorted arrays is no loss; Cassandra wouldn’t do those anyway. Apart from the commit log which optimizes against disk seeks in ways that lie outside the scope of this post, the only kind of write to disk that Cassandra does is a big sequential write of data: the dumping of an in-memory Memtable in the form of a new SSTable. As most writes only touch memory, updating the Memtable (or, as of 2.0, a skip list) makes the amortized cost of a write request very low. Only when a Memtable is large enough, is it dumped to disk.
For a read request on a Cassandra node, the story of performance is not so simple. Performance is strongly correlated to the number of disk seeks needed to find the right value. The primary key that values are stored with consists of:
The partition key, which determines which node data is stored on. Partition keys are hashed.
One or more clustering keys that determine clustering. The SSTables are sorted based on the clustering keys.
Cassandra stores per-SSTable indexes in memory, so there’s no need for actual on-disk binary searching to find the right spot in an SSTable. Instead, the problem is finding the right SSTable. Remember that new SSTables are periodically dumped to disk; eventually thousands of SSTables will have been written.
How does Cassandra avoid performing thousands of disk seeks on every read request? Cassandra has ways of filtering some away. These are per-SSTable, and include:
Bloom filters, which can tell when a partition key is not in an SSTable.
Minimum & maximum clustering keys, which can help rule out a number of SSTables.
Minimum & maximum timestamps, which lets Cassandra reason about whether updates or deletes of values could have come after a particular value was written.
(Hashed) partition key ranges, which in case Leveled Compaction Strategy is used, significantly reduces the number of potential SSTables to look in.
But these optimizations don’t help too much if these SSTables are just left untouched. The optimization that does do something about that is compaction. The SSTables are immutable, but they can be compacted, i.e. merged into larger SSTables which when finished lets the original SSTables be garbage collected. This, of course, is yet another sequential disk operation. In short, compaction serves these purposes:
Ensures that Cassandra has to look in as few SSTables as possible on a read request, after applying the list of optimizations mentioned above.
Puts ranges of contiguous clustering keys clustered on disk, so that a given range of clustering keys within a single partition lies in as few files as possible.
Evicts tombstones and TTL expired data. A tombstone is as “logical delete”; a write with a special “delete this” value.
Which SSTables to choose and when to compact
Until version 2.0.10 and 2.1.0, Cassandra shipped with two compaction strategies: Size-Tiered Compaction Strategy (STCS) and Leveled Compaction Strategy (LCS). These strategies for choosing what to compact and when and how are as different in approach as one can imagine. Before talking about them, one thing worth noting is that a compaction operation is not at all free. It takes time and space proportional to the combined size of the participating SSTables. And while multiple compactions can run in parallel, incoming requests become slower the more compactions that are running.
STCS has one simple goal: make it so there are as few SSTables on disk as possible at any given time. It does so in an asymptotically optimal way that only compacts SSTables that are close enough in size. On average and in the worst case, the number of SSTables on disk is logarithmic to the total data size on disk.
LCS takes a radically different approach. It not only merges SSTables, but it also splits them to make only a certain range of partition keys live in one SSTable. It then keeps these ranges apart in a smart way that means a partition key can only exist in a small number of files, logarithmic to the total data size on disk. When compared to STCS, it tends to result in fewer seeks per read request, but performs a higher number of compactions with a higher number of SSTables involved in each operation.
Time Series
One of Cassandra’s most common use-cases is for time series. A time series in Cassandra uses the time of a data point as the clustering key. This kind of use case has a number of useful properties that neither of the two aforementioned compaction strategies take advantage of:
Clustering key and timestamp (Cassandra write time) are directly correlated.
Data tends to be sent to Cassandra in time order. Out-of-order writes only happen on a small scale (in a matter of seconds, typically).
The only kinds of deletes used are by TTL or entire partitions at once.
The rate at which data is written is nearly constant.
A query on a time series is usually a slice query (range query) on a given partition. Perhaps, the most common query is something like “values from the last hour/day/week”.
Since Cassandra holds in-memory metadata about maximum and minimum clustering keys per SSTable, range queries can immediately rule out SSTables that have a range that lies outside the range of the query. But STCS and LCS pay no attention to this. The result after running Size-Tiered Compaction Strategy on a time series is that nearly all SSTables have some old data and some new data in them. Even if just one value is much older or newer than the rest, that changes the minimum/maximum timestamp, and as a result Cassandra sees that the SSTable covers a much larger range of clustering keys. Below is a diagram showing an example run of continuously writing to a new time series with STCS:
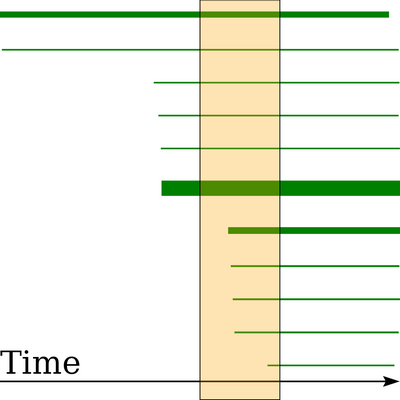
The horizontal axis in this diagram represents timestamps from the start of the example run on the left to the end on the right. Compactions were let finish before generating this image. Each rectangle is an SSTable (a total of 11 in this case). The left edge of each rectangle marks its minimum timestamp, the right edge marks the maximum timestamp. While the vertical axis bears no significance, the area of each rectangle represents the size of the data file. The vertical bar represents a slice query. This query asks for all data points, in a given partition, within a certain time span.
In this example, parts of all 11 SSTables need to be read, which results in 11 disk seeks. What we see here is variously sized SSTables covering more or less the full range of clustering keys. Size and age follow no pattern.
Date-Tiered Compaction
Before getting into details of the new Date-Tiered Compaction Strategy (DTCS), with the previous image fresh in mind, let’s see what DTCS produces in the same scenario:
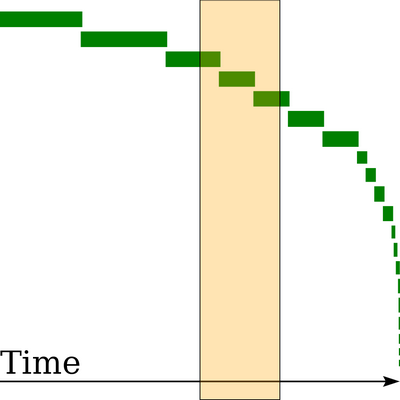
In this image, you can see 20 SSTables which are spread out much more nicely over the timeline. The number of SSTables is higher, but that is mostly because of a low base_time_seconds setting. That setting determines how old an SSTable has to be to not immediately enter compaction. The slice query now hits only 3 SSTables, which is great, considering the size of the slice in this example covers 20% of the time line. Also, note that all rectangles have nearly the same height. This demonstrates the correlation between size and age of DTCS-compacted SSTables in a dataset where writes are done at a constant pace. The SSTables are not only date-tiered, they are size-tiered too!
You can immediately see how most queries would require Cassandra to look in every SSTable in the STCS case. In the above STCS example, the only somewhat efficient range to query is right at the start of the time span, typically the least important section. In the DTCS case, the SSTables lie in sequence, and only some of the SSTables have to be touched in slice queries. In a single key query or narrow slice query, most of the time only one SSTable has to be touched. A “last hour” query is still less efficient than a query for an earlier hour, but DTCS does the best it can, given the constant influx of SSTables. In practice, the newest SSTables are likely to be disk cached.
When to use DTCS (and when to avoid it)
It’s obvious that DTCS is great at handling time series. That’s what it was designed for. As has been shown here, DTCS also challenges STCS on any dataset that gets writes at a steady rate. This accounts for a high percentage of Cassandra use cases. DTCS is not allergic to more sporadic write patterns either. But something that works against the efforts of the strategy is writes with highly out-of-order timestamps. If an SSTable contains timestamps that don’t match the time when it was actually written to disk, it violates the size-to-age correspondence that DTCS tries to maintain. Such SSTables do appear organically in Cassandra as a result of repairs. The problem is that small SSTables end up in windows dedicated to large SSTables, and merging large files with small files is inefficient. Consider turning off read repairs. Anti-entropy repairs and hinted handoff don’t incur as much additional work for DTCS and may be used like usual.
Also, make sure that all writes use the same timestamp format. Whether it’s microseconds or milliseconds, a mix will behave as extremely out-of-order. As always, make sure that client clocks are synced. It’s the clients, not the servers that set the timestamps. Even DTCS’s idea of “current time” is governed by client timestamps.
Great at removing data
Cassandra’s log-structured storage has a hard time dealing with deletes. Tombstones are used to represent a delete or expired TTL. Cassandra manages to delete associated values during compactions at a good rate. But existing compaction strategies have a hard time deleting the tombstones themselves, and that can actually become a problem. DTCS helps a lot in purging tombstones, because when they reach the oldest SSTable, Cassandra simply removes any tombstone that is older than GC grace period. An SSTable that is older than all the others have no reason to hold tombstones beyond the grace period.
This is particularly useful for all-TTL datasets, where Cassandra is even able to delete entire SSTables once they have fully expired. DTCS helps keep new and old data separate, so that optimization can kick in considerably more often. This means that an all-TTL dataset with DTCS can be trusted to stay constant in size in the long run, and in an efficient manner.
Sub-properties
To used DTCS, the user specifies the compaction strategy as DateTieredCompactionStrategy, which is accompanied by a number of sub-properties. The options with the biggest effect on how DTCS behaves are (these properties and default values are subject to change):
timestamp_resolution (default = “MICROSECONDS”): make sure that this is set to the same format that your clients use when writing timestamps (CQL uses microseconds by default).
base_time_seconds (default = 3600 (1 hour)): this sets the initial window size which dictates how much of the most newly written data should be eagerly compacted together. All data older than base_time_seconds will subsequently be grouped together with other data about the same age, at which point further compactions will start happening increasingly (exponentially) less frequently. This option is similar to the min_sstable_size subproperty in SizeTieredCompactionStrategy.
min_threshold (default = 4): for data not in the current window of newest data, min_threshold dictates how many of these previously compacted windows of the same (time span) size should be created before merging them into one time window min_threshold as large. Windows of the same size are of course adjacent to each other, and there are never more than min_threshold windows of one size (unless min_threshold = 1, of course).
max_sstable_age_days (default = 365): stop compacting SSTables only having data older than than this number of days. Setting this low, reduces the total number of times the same value is rewritten to disk. Since it prevents compaction of the largest SSTables, it can also be used to limit the amount of free disk space needed for compaction.
How DTCS works
The idea is to act similarly to STCS, but instead of compacting based on SSTable size, compact based on SSTable age. The measurement of age used is the minimum timestamp of the SSTable, subtracted from the maximum timestamp globally. Assuming that writes come at a somewhat steady rate, and that timestamps roughly reflect the time of arrival to Cassandra (two properties that are held for much more than just time series), the size of an SSTable is upper bounded by its age. Furthermore, if SSTables are always merged with similarly aged SSTables, the old ones will be large and the new ones will be small. In other words, while DTCS compacts based on age, this correlation between age and size means that it gets the same asymptotic performance characteristics as STCS, while keeping data grouped by timestamps, as seen in the diagram above.
One way to implement this would be to fully mimic the behavior of STCS and compact SSTables with a relative age difference less than a constant factor. But there is one important property that differs between the size and the age of an SSTable: the size is constant, but the age rises over time. So SSTables that didn’t have ages within that constant factor a moment ago might suddenly have. This is a complication that we want to avoid. It also becomes difficult to reason about the efficiency of such an approach.
The approach that was chosen, instead uses the current time to compute time windows between Unix epoch and now. These windows don’t slide with the passage of time. Instead, as time passes, new time windows appear and old ones get merged into larger windows. The time that needs to pass before creating a new time window is specified by the base_time_seconds subproperty. The number of windows of one size that need to be accumulated before merging them into a bigger one is specified by the min_threshold subproperty. For example, with base_time_seconds=3600 (an hour) and min_threshold=4, the placement of the last few time windows at 7 consecutive hours may look like this:
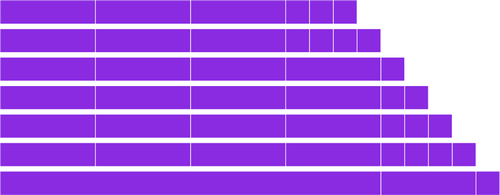
The condition for compaction is simple: if multiple SSTables have an age that falls into the same window, DTCS will nominate all of those for compaction. The current point in time (computed as the maximum timestamp globally across SSTables) is always located in the latest time window.
The precise definition for when time windows get merged is: the moment min_threshold windows of one size get accompanied by yet another same-sized window, the aforementioned group of windows merge into one. This can have a domino effect as seen in the bottom lane of the image, where a fifth 1-hour window triggered the creation of a fifth 4-hour window, triggering the creation of a 16-hour window.
Summary
To keep data clustered based on write time, Date-Tiered Compaction Strategy uses information that other strategies disregard. It is very cheap to keep that structure as long as data is seldom written very out-of-order. This separation of old and new data is excellent for time series. It also holds an advantage against the other strategies at purging deleted data quickly and predictably.
SHARE THIS ARTICLE



