Generating test cases so you don’t have to
In my spare time, I have developed a C++ framework for property based testing called RapidCheck. As my Hack Week project, I wanted to see if it could be a applied to the code I deal with at work: the Spotify player code. “But hey, aren’t there lots of C++ testing frameworks out there already” you say, “Do we really need another one?”. This one is a bit different and to explain why, let’s talk about tests.
“But I already have unit tests!”
Do your unit tests look anything like this?:
BOOST_AUTO_TEST_CASE(correctlyParsesNumbers) {
BOOST_CHECK(parseSignedInteger("0") == 0);
BOOST_CHECK(parseSignedInteger("3") == 3);
BOOST_CHECK(parseSignedInteger("15") == 15);
BOOST_CHECK(parseSignedInteger("1337") == 1337);
}This is a typical unit test that tests a simple unsigned integer parser. It has four test cases that test that we get the correct output given a particular input. First we test with "0" which makes sense because that might be seen as the trivial case, gotta get that right. We then then we test with "3" because that’s a simple but non-trivial input. We also add a test for "15" since we need to ensure that we treat numbers in different positions correctly. However, only three test cases seem a bit weak so we add a fourth one for good measure. But why only four test cases? Is that enough? How much is enough? Shouldn’t we at least cover all the powers of ten that fit into the target data type? What about overflow? Are there any optimizations that introduce weird corner cases? How much testing is enough? If we assume that we are dealing with a 32-bit unsigned integer datatype, there are 4,294,967,296 valid inputs so exhaustive testing is not an option. We could double the number of test cases but that’s not really much of an improvement in the grand scheme of things. Besides, we all know that writing unit tests is boring. There, I said it. When reaching over 10 test cases, most of us will probably say “Whatever, it seems to work, let’s Ship It™”. It will probably pass code review and the code coverage report will likely be as good as ever.
Property based testing
In 2000, John Hughes and Koen Clasessen invented the phenomenal QuickCheck, a framework to solve this exact problem for the Haskell programming language. In QuickCheck, you specify properties of your code that should hold regardless of input. QuickCheck then randomly generates the input data to try to find a case for which the property fails. When such a case is found, it tries to find a minimal test case by shrinking the input data. This minimal test case is then reported for easy reproduction. This form of testing became known as property based testing and is actually the dominant form of testing in the Haskell ecosystem. Fascinated by the concept and surprised that nobody had made a worthy alternative for C++, I decided to create RapidCheck. RapidCheck is a complete implementation of property based testing for C++11 that implements all of the significant features of the original Haskell version and even more. Using RapidCheck we can rewrite the example above:
rc::check("correctly parses numbers", [](unsigned int x) {
RC_ASSERT(parseUnsignedInteger(std::to_string(x)) == x);
});Assuming we have a bug in parseUnsignedInteger, RapidCheck might print the following:
- correctly parses numbers
Falsifiable after 35 tests and 3 shrinks
std::tuple:
(1000)
../examples/mapparser/main.cpp:25:
RC_ASSERT(parseUnsignedInteger(std::to_string(x)) == x)
Expands to:
0 == 1000Apparently, we should have tried 1000 as input in our original unit test! This form of testing has several advantages:
It frees you from having to manually specify the test cases, the framework generates them for you.
It can find bugs for inputs that you didn’t even consider, it is not biased. – It can give more coverage with less code.
Encourages you to think about the complexity of its behavior – simple code, simple properties.
Encourages totality/robustness – Instead of filtering out unwanted input, write your code so that it handles everything.
“Sure, but my types are not just ints!”
In the example above, the generated input is an unsigned integer, a very simple value. However, real world code does not deal with just integers. Also, you will probably want more control over what input is generated in many cases, not just any integer will do. RapidCheck fortunately has a solution for all of this through the concept of “generators”. Generators are the source of all generated input in RapidCheck. A generator is an object of type Gen where T is the type of the values that it generates. RapidCheck comes packed out-of-the-box with generators for most common types in C++ and the standard library. It also provides combinators that allow you to build complex generators from simples ones. To start with an example, rc::gen::inRange(0, 2000) returns a generator of integers (i.e. Gen) between 0 and 2000. We can pick a value from this generator using the *-operator like this:
rc::check("correctly parses numbers", [] {
const auto x = *rc::gen::inRange(0, 2000);
RC_ASSERT(parseUnsignedInteger(std::to_string(x)) == x);
});We can also create an std::vector of integers between 0 and 2000:
const auto ints = *rc::gen::container>(
rc::gen::inRange(0, 2000));Or how about a generator for our own domain specific object type using the gen::build combinator:
using namespace rc;
const auto person = *gen::build(
// Construct with ID, constructor takes std::size_t
gen::construct(
gen::arbitrary()),
// Pick a first name, Person class has a setter
gen::set(&Person::setFirstName,
gen::element("Joe", "John", "Jane", "Kate")),
// Pick an age between 0 and 100
gen::set(&Person::setAge, gen::inRange(0, 100)));RapidCheck allows you to create generators for very complex types and you also get the test case shrinking for free when you use the built in combinators.
“Right, but my code has tons of state!”
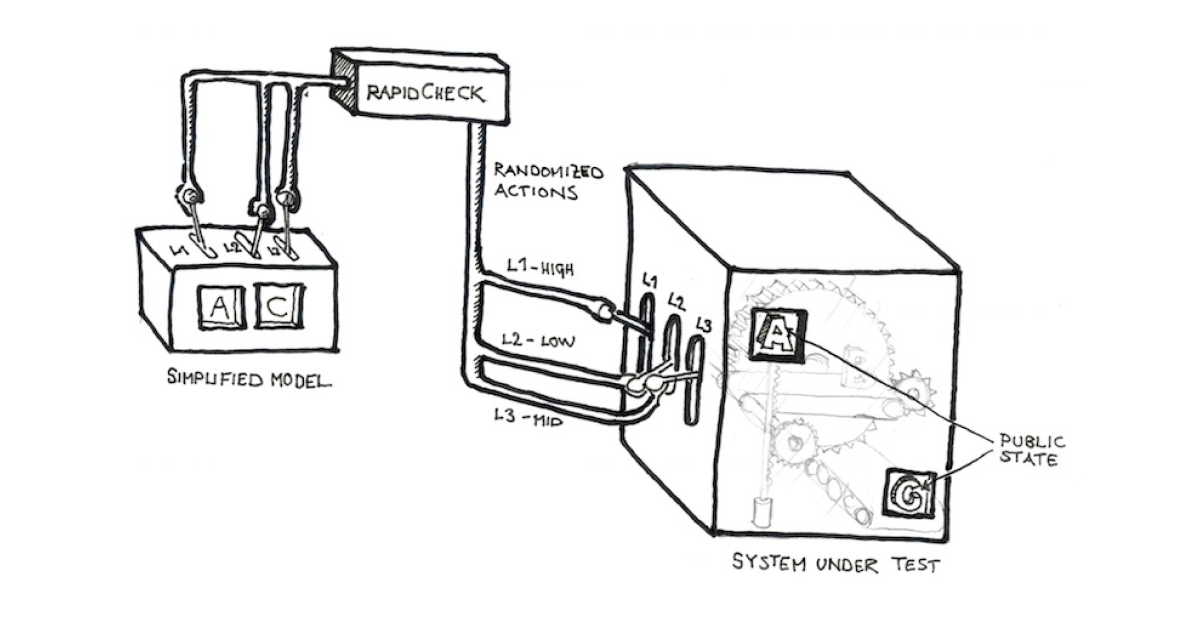
In our first example, we were testing a pure function, a function that takes some input and produces output that only depends on the input. Unfortunately, real world code does not always consist of pure functions, it is littered with hidden state that is hard to manipulate directly. But even if our code is not a function, our test can still be. We only have to reconsider our notion the input is. RapidCheck includes a model based testing framework inspired by that of the Erlang version of QuickCheck. When using this, the generated input is not data but a sequence of operations to perform on the System Under Test. We also build a simplified model of the System Under Test that we can verify against while performing these operations. Thus, what the developer needs to implement are essentially two things: the model and the operations that can be performed on the model and the System Under Test. RapidCheck will then generate a valid (according to the model) sequence of commands and try to apply it to the System Under Test. If the post-conditions of any command fails, RapidCheck will, just like above, try to find minimal test case consisting of as few commands as possible with as simple parameters as possible.
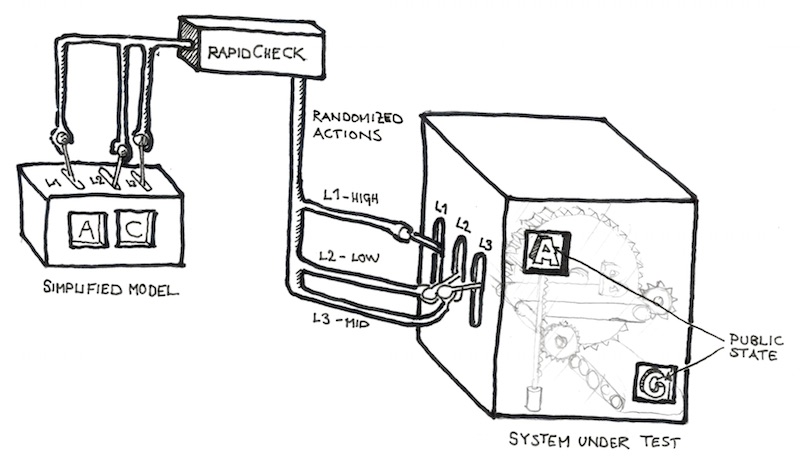
Thanks to Mats Lindelöf for the image
This type of testing is what I applied to the Spotify player.
Let there be bugs!
Spotify clients have a shared module that handles the sequencing of tracks (not the actual audio playback) including shuffling, repeating tracks, repeating playlists and so for. For the purposes of this article, let’s call it “the player”.
When it comes to the player, it turns out that the basic functionality does not require a lot of state to model. Here is the model that I used:
struct SessionModel {
Context context;
std::vector tracks;
};
struct PlayerModel {
bool is_playing;
bool is_paused;
bool repeating_context;
bool repeating_track;
bool first_repeat;
using SessionModelSP = boost::shared_ptr;
std::vector sessions;
int session_index;
int track_index;
};Of course, the actual player has a lot more state than this but it also does a lot of things that we did not model here. The other part that we need to provide is all of the operations that we want to test. In RapidCheck, the operations are implemented as subclasses of the Command template. Here is the implementation of the preparePlay operation which prepares playback of a playlist (possibly prefetching etc.):
using PlayerCommand = state::Command;
struct PreparePlay : PlayerCommand {
Context context =
*gen::build(gen::set(&Context::entity_uri),
gen::set(&Context::metadata),
gen::set(&Context::pages,
gen::map(genContextPage(gen::arbitrary()),
[](ContextPage &&page) {
return std::vector{std::move(page)};
})));
PlayOrigin play_origin = *gen::arbitrary();
PreparePlayOptions options = *genPreparePlayOptions(context);
void apply(PlayerModel &s0) const override {
s0.sessions.push_back(boost::make_shared(context));
}
void run(const PlayerModel &s0, PlayerSystem &sys) const override {
sys.sessions.push_back(
sys.player->preparePlay(context, play_origin, options));
}
};As we can see above, a command must implement two operations: apply and run. apply performs the operation on the model and run applies the operation on the actual System Under Test. In this case, the system is a fixture that has the player and all the related objects and mocks required for it to function. This operation also has three parameters provided as member variables of the command, context, play_origin, and options. These are all generated by RapidCheck and if the test case is shrunk, they will be shrunk too. Here is another command:
struct Pause : PlayerCommand {
void apply(PlayerModel &s0) const override {
RC_PRE(s0.is_playing);
RC_PRE(!s0.is_paused);
s0.is_paused = true;
}
void run(const PlayerModel &s0, PlayerSystem &sys) const override {
EXPECT_CALL(*sys.track_player, pause()).Times(1);
sys.player->pause(PauseOptions());
}
};This command uses the RC_PRE macro to assert preconditions for the command in the apply method. If the preconditions are not met, RapidCheck will discard the command and try another one. We also set a Google Mock expectation in the run method. If this expectation fails, RapidCheck will detect that as a failure and then try to find a minimal command sequence that still fails.
…and there were bugs
It’s not always that you’re happy to find bugs in production code but in this case, I made some very pleasant discoveries. I found a total of three bugs but one of them really stood out. RapidCheck printed the following:
Using configuration: seed=11317088442510877731
Falsifiable after 76 tests and 30 shrinks
std::vector>>:
ToggleRepeatingContext()
PreparePlay({
"tracks": [{
"uid": "a",
"uri": "spotify:track:aaaaaaaaaaaaaaaaaaaa"
}]
})
Play(0)
AddTrack(0, 0, {
"uid": "b",
"uri": "spotify:track:aaaaaaaaaaaaaaaaaaaa"
})
SkipToNextTrack()
../spotify/player/cpp/properties/main.cpp:94:
RC_ASSERT(track == expected_track)
Expands to:
{
"uid": "a",
"uri": "spotify:track:aaaaaaaaaaaaaaaaaaaa"
} == {
"uid": "b",
"uri": "spotify:track:aaaaaaaaaaaaaaaaaaaa"
}RapidCheck first prints out the counterexample which in this case is a textual representation of the command sequence that caused the failure. Then comes the assertion that triggered the failure. For someone not familiar with the player API, these were the reproduction steps:
Turn on playlist repeat.
Prepare playback of a playlist with a single track, let’s call this track A.
Play the prepared playlist.
Add a single track to the start of the playlist.
Skip to the next track.
Since we have repeat enabled, we expect to wrap around to the newly added track when we advance from the first track. However, instead we get the same track again. This was even easily reproducible in both the iOS and Android clients!
Final thoughts
This was the first time I actually tried RapidCheck on a more complex real world system so I had no idea what to expect. I was very happy to see that it was a great success. While writing these tests, I did make a few observations:
Developing a model of the player made me really think about how the player is supposed to work since every misinterpretation results in a test failure. Because of this, every design decision and every peculiarity in the behavior is very evident in the model.
Simple bugs are almost always found after very few tests.
Test case shrinking is a really important feature. If shrinking is disabled, the counterexample for the bug above is huge and there is no way to know what is wrong just by looking at it.
With its roots in pure functional programming, one could get the impression that property based testing is merely a toy for academics. On the contrary, my experience during Hack Week is that it is an excellent tool to find complex bugs in complex real world code, even when that code is written in a programming language as inflexible as C++. This also echoes the takeaway other people at Spotify have had when out trying property based testing for other programming languages (such as the developers of the Spotify playlist system).
What remains to be seen is how this fits into our team’s existing testing workflow and this is something we want to experiment with. The next step is to enable this test in Continuous Integration and expand it to model more of the player state and operations. Regardless, if you care about the quality and correctness of your code, property based testing is definitely a tool that I think you should evaluate.
Emil Eriksson, The Players squad at Spotify
SHARE THIS ARTICLE



