Spotify’s Event Delivery – The Road to the Cloud (Part I)

Whenever a user performs an action in the Spotify client—such as listening to a song or searching for an artist—a small piece of information, an event, is sent to our servers. Event delivery, the process of making sure that all events gets transported safely from clients all over the world to our central processing system, is an interesting problem. In this series of blog posts, we are going to look at some of the work we have done in this area. More specifically, we are going to look at the architecture of our new event delivery system, and tell you why we choose to base our new system on Google Cloud managed services.
In this first post, we’ll explain how our current event delivery system works and talk about some of the lessons we’ve learned from operating it. In the next post, we will cover the design of the new event delivery system, and why we chooseCloud Pub/Subas the transport mechanism for all the events. In the third and final post, we will explain how we consume all the published events with DataFlow, and what we have discovered about the performance of this approach so far.
The events that propagate through our event delivery system have many uses. Most of our product design decisions are based on the results of A/B tests, and those A/B tests rely on rich, accurate usage data. The Discover Weekly playlist, released in 2015, quickly became one of the Spotify’s most used features. It was built by leveraging Spotify playback data. Year in music, Spotify Party and many other Spotify features are also fueled by data. Spotify usage data is one of the sources for Billboard top lists.
Our event delivery system is one of the foundational pieces of Spotify’s data infrastructure. It has a key requirement to deliver complete data with a predictable latency and make it available to our developers via well-defined interface. Usage data can be defined as a set of structured events that are generated at some point in time as a response to some predefined actions.
Most of the events that are being used in Spotify are directly generated from Spotify clients as a response to certain user actions. Whenever an event occurs in the Spotify client, it is sent to one of the Spotify gateways which logs it via syslog. There it is assigned a timestamp that is used throughout the event delivery system. To be able to give latency and completeness guarantees for the event delivery, it was decided to use the syslog timestamp and not the timestamp when the event originated on the client, because we do not have control of the events before they hit our servers.
In Spotify’s case, all data needs to be delivered to a centrally located Hadoop cluster. Spotify servers, from which we collect data, are located in multiple data centers on two continents. Bandwidth between our data centers is a scarce resource. Great care needs to be taken in how it gets used.
The data interface is defined by the location where the data is stored in Hadoop and the format in which it gets stored. All data that gets delivered via our event delivery service is written in Avro format on HDFS. Delivered data is partitioned based on hourly buckets. This is a relic from the past, when the first event delivery system was based on the scp command and copied hourly based syslog files from all the servers to Hadoop. Since all the data jobs running in Spotify today are expecting to have hourly-partitioned data, this interface is going to stick with us for the foreseeable future.
Most data jobs in Spotify read data only once from a hourly bucket. The output of a job can then serve as the input of another job, forming long chains of transformations. Once the job transformed the data for the hour, it does not perform any checks if the data in the hourly source bucket has been changed in the meantime. If the data haschanged, the only way to reproduce the data is to manually force all the downstream jobs—and subsequently their downstream jobs—to run for that particular hour. This is a costly labour intensive process, which is why the event delivery service has a requirement on it that, after it presents hourly buckets. It doesn’t perform any data backfills after that. This problem, known as the data completeness problem, has competing requirements to delivery latency. An interesting point of view on the data completeness problem can be found in the Dataflow paper from Google.
Currently running event delivery system (Here be dragons)
System Design
The system that we have in production today was built on top of Kafka 0.7.
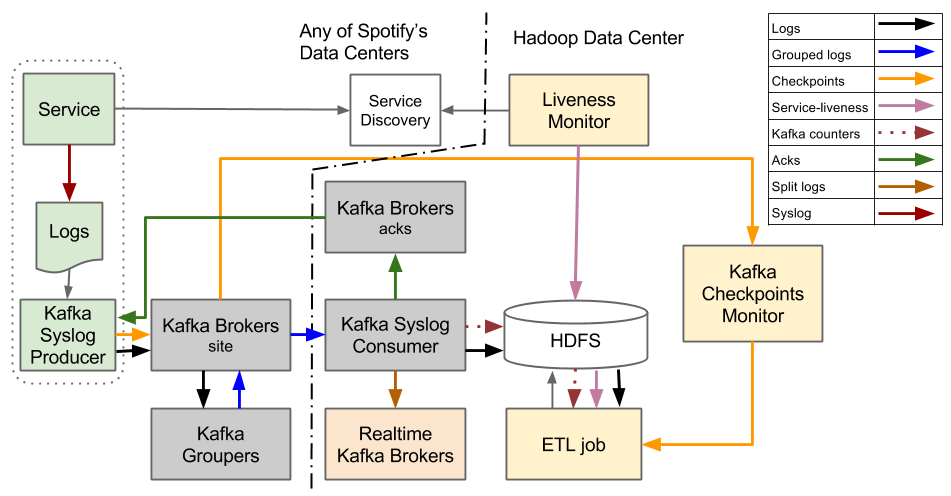
Figure 1. Event Delivery system based on Kafka 0.7
The event delivery system that we have today is designed around the abstraction of hourly files. It’s designed to stream log files, which contain events, from the service machines to the HDFS. After all the log files for the specific hour get transferred into HDFS they get transformed from tab-separated text format to Avro format.
When the system was built, one of the missing features from Kafka 0.7 was the ability of the Kafka Broker cluster to behave as a reliable persistent storage. This influenced a major design decision to not keep persistent state between the producer of data, Kafka Syslog Producer, and Hadoop. An event is considered reliably persisted only when it gets written to a file on HDFS.
A problem with having events reliably persisted only after they reach Hadoop is that the Hadoop cluster is a single point of failure in the event delivery system. If Hadoop is down the whole event delivery system stalls. To cope with this, we need to ensure we have enough disk space on all the services from which we are collecting events. When Hadoop comes back up, we need to “catch up” by transferring all the data as soon as possible to it. Recovery time is mostly constrained by the amount of bandwidth that can be used between our data centers.
The Producer is a daemon which runs on every service host from which we want to send events to Hadoop. It tails log files and sends batches of log lines towards Kafka Syslog Consumer. The Producer has no notion of event type or other properties an event might have. From the producer’s point of view event are just lines in a file and all lines gets forwarded via the same channel. This means that all event types contained in same log file are also sent over the same channel. In this system, Kafka topics are used as channels for transferring events. After the Producer sends log lines to the Consumer it needs to wait for the acknowledgment (ACK) that the Consumer has successfully persisted log lines into HDFS. Only after the Producer receives ACK for sent log lines it considers them reliably persisted and moves on with sending other log lines.
For events to get from the Producer to the Consumer they need to pass through Kafka Brokers and then Kafka Groupers. The Kafka Brokers are a standard Kafka component, while the Kafka Grouper is a component written by us. The Groupers consume all event streams from their local data center and then republish them, compressed, efficiently batched to a single topic which is then pulled by the Consumers.
An Extract, Transform and Load (ETL) job is used to transform data from plain ol’ tab separated format to Avro format. The job is an ordinary Hadoop MapReduce job, implemented using the Crunch framework, which operates on hourly data buckets. Before starting the job for a specific hour it needs to be ensured that all files have been fully transferred.
All the Producers are constantly sending checkpoints that contain end-of-file markers. These markers are only sent once, when the Producer concluded that the whole file was reliably persisted to Hadoop. Liveness monitor continually queries our service discovery systems in all the data centers to get information on which service machines were alive during the particular hour. To check if all the files have been completely transferred during a particular hour, the ETL job combines information about which are the servers that it should expect data from and end-of-file markers. If the ETL job detects that data haven’t been fully transferred it delays the processing of data for the particular hour.
To be able to maximally utilize the available mappers and reducers, the ETL job, which is an ordinary Hadoop MapReduce job, needs to know how to shard input data. Mappers and reducers get calculated based on the input data size. Optimal sharding is calculated based on the event counts continually sent from the Consumers.
Learnings
One of the main problems with this design is that the local producer needs to make sure that data is persisted in HDFS at a central location before it can be considered to be reliably delivered. This means that a producer on a server in west coast US needs to know when data has been written to disk in London. Most of the time this works just fine, but if transfers are slow this will cause delivery delays that are hard to recover from.
Contrast this with a design where the point of handover is in the local datacenter. This simplifies the design of the producer as networking between hosts in a datacenter is typically rock solid.
Putting some problems aside, we are quite happy to have built a system that can reliably push more than 700 000 events per second halfway across the world. A redesign of the system also gave us opportunity to improve on our software development process.
By sending all the events together via the same channel, we lose the flexibility of managing event streams with different quality of service (QoS). It also limits the real time use case, since any real-time consumer needs to tap on to the firehose that transmits everything and filter out only messages in which it’s interested.
Sending unstructured data on the wire adds unnecessary latency since it requires extra transformation of data with an ETL job. As currently implemented, the ETL job adds around 30 min of latency to event delivery. If data had been sent in structured Avro format, it would have been immediately available as soon as it was written out to HDFS.
Having the sender keep track of when an hour is complete causes problems. For example, when machine dies it can’t send an end-of-file message. If there is a missing end-of-file marker, we will wait forever unless there is manual intervention. As the number of machines grows, these problems become more pronounced.
Next steps
The number of delivered events has been consistently increasing at Spotify. As a result of increased load on the system, we started experiencing more outages. With time, the number of outages started to alarm us. We realised that neither we nor the system would be able to keep up with the increased load for long.
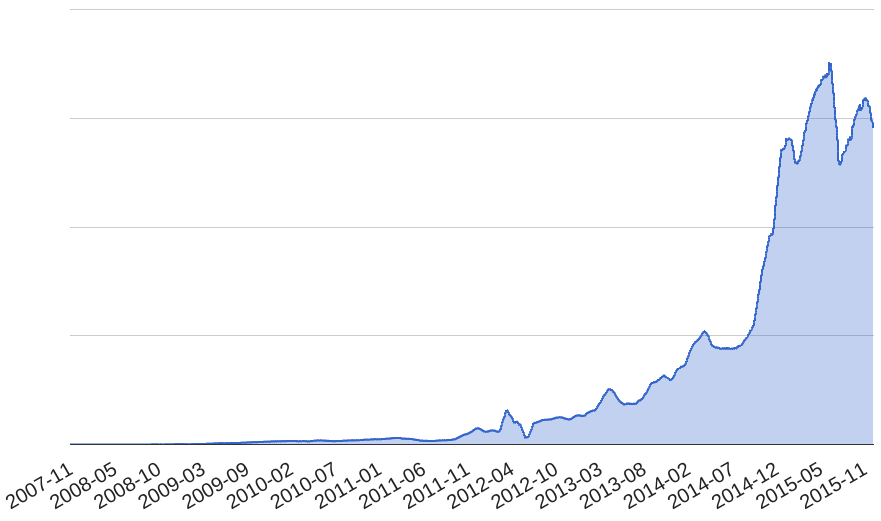
Figure 2. Amount of Spotify’s Delivered Events over time
Unfortunately, we couldn’t iteratively improve the existing system since all the components were tightly coupled. Even small changes to one component would lead to system outages that were hard to fix. The only way forward that we saw was a total rewrite of the event delivery system.
In the next blog post in this series we will go through how we chose to base the next generation of Spotify’s event delivery on Google’s Cloud Pub/Sub offering. Stay tuned!
SHARE THIS ARTICLE


