Spotify’s Event Delivery – The Road to the Cloud (Part II)

Whenever a user performs an action in the Spotify client—such as listening to a song or searching for an artist—a small piece of information, an event, is sent to our servers. Event delivery, the process of making sure that all events gets transported safely from clients all over the world to our central processing system, is an interesting problem. In this series of blog posts, we are going to look at some of the work we have done in this area. More specifically, we are going to look at the architecture of our new event delivery system, and tell you why we choose to base our new system on Google Cloud managed services.
In thefirst postin this series, we talked about how our old event system worked and some of the lessons we learned from operating it. In this second post, we’ll cover the design of our new event delivery system, and why we chooseCloud Pub/Subas the transport mechanism for all events.
Designing Spotify’s New Event Delivery System
Our experience in operating and maintaining our old event delivery system provided plenty of input into the design of the new and improved one. The current design was built on top of an even older system operating on hourly rotated log files. This design choice creates complexity such as the propagation and confirmation of end-of-file markers on each event producing machine. Moreover, the current implementation has some failure modes it can not recover from automatically. A piece of software that requires manual intervention for many failure modes running on each machine that produces logs incurs significant operational cost. In the new system we wanted a simpler design on the log producing machines, handing over events to a smaller set of machines close on the network for further processing.
The missing piece here is an event delivery system or queue that implements reliable transport of events and the persistence of undelivered messages in the queue. With such a system in place, we should be able to have the producer hand off events close to the producer at a very high rate; receive an acknowledgement back with low latency; and have the rest of the system be responsible for the complexity of making sure that submitted events gets passed to HDFS.
Another change we made was to have each event type have its own channel, or topic, and to convert to a more highly structured format early on in the process. Pushing more of the work onto the producer side means that less time needs to be spent converting the format in the Extract, Transform, Load (ETL) job later in the the process. Having separate topics per event is a key requirement for building efficient real time use cases.
Since event delivery is something that simply needs to work, we designed the new system in such a way that it could run in parallel with the current system. The interface, both at the producer and the consumer end, matched the current system and we can verify both performance and correctness of the new system rigorously before making the switch.

Figure 1. High Level System Design of New Event Delivery System
The four main components of the new system are the File Tailer, the Event Delivery Service, the Reliable Persistent Queue, and the ETL job.
In this design, the Tailer has a much narrower set of responsibilities than the Producer in our old system. It tails log files looking for new events, and forwards them to the Event Delivery Service. As soon as it gets a confirmation that the event has been received it’s responsibility ends. No more complexity handling end-of-file markers or making sure that data has reached it’s final destination in HDFS.
The Event Delivery Service accepts events from the Tailer, transform them to their final structured format and forwards them to the Queue. It is built as a RESTful microservice using the Apollo framework and deployed using the Helios orchestration platform, a common design pattern at Spotify. It enables clients to be decoupled from the specifics of a single persistence technology as well as enabling any underlying technology to be switched without service disruption.
The Queue is the core of our system and, as such, is important for it to scale with growing data volumes. To cope with Hadoop downtime, it needs to reliably store messages for a number of days.
The ETL job should reliably de-duplicate and export events from the Queue to hourly buckets in HDFS. Before it exposes a bucket to the downstream consumers, it needs to detect with high level of confidence that all data for the bucket has been consumed.
In Figure 1, you can see a box that says “Service Using API directly”. We have felt for some time that syslog was a less-than-awesome API for event producers. When the new system is in production and the old system has been fully retired, it makes sense to move away from syslog and start providing libraries that services can use to communicate directly with the Event Delivery Service.
Choosing a Reliable Persistent Queue
Kafka 0.8
Building a Reliable Persistent Queue system that reliably handles Spotify event volumes is a daunting task. Our intention was to leverage existing tools to do the heavy lifting. Since event delivery is the foundation of our data infrastructure, we wanted to play it safe. Our first choice was Kafka 0.8.
There are many reports that Kafka 0.8 is successfully used by companies of significant size around the world and Kafka 0.8 is a big improvement over the version in use in the current system. In particular, its improved Kafka brokers provide reliable persistent storage. The Mirror Maker project introduced mirroring between data centers, and the Camus project can be used for exporting Avro structured events to hourly buckets.
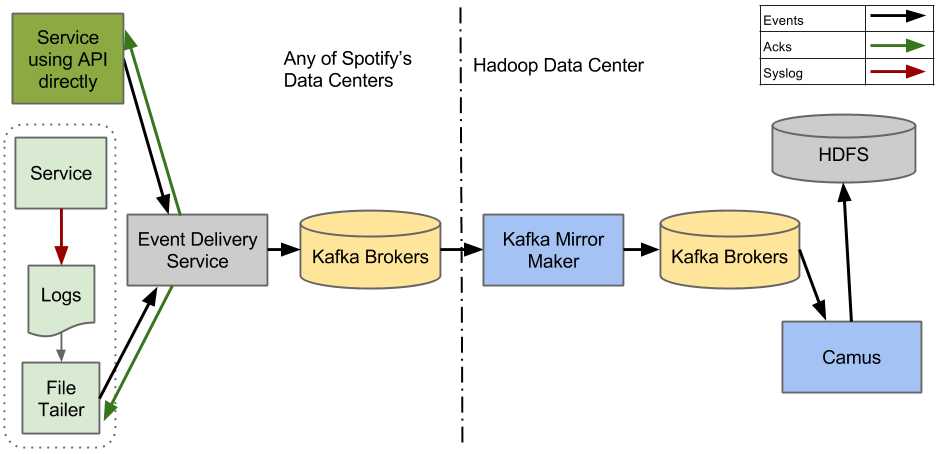
Figure 2. Event delivery system design in which we use Kafka 0.8 as reliable persistent queue
To prove that event delivery can work as expected on Kafka 0.8, we deployed the test system shown in Figure 2. Embedding a simple Kafka producer in the Event Delivery Service also proved to be easy. To ensure the system worked correctly end-to-end—from Event Delivery Service to HDFS—we embedded various integration tests in our continuous integration and delivery process.
Sadly, as soon as this system started handling production traffic, it started to fall apart. The only component that proved to be stable was Camus (but since we didn’t push much load through the system, we still don’t know how Camus would perform under stress).
Mirror Maker gave us the most headaches. We assumed it would reliably mirror data between data centers, but this simply wasn’t the case. It only mirrored data on a best effort basis. If there were issues with the destination cluster, the Mirror Makers would just drop data while reporting to source cluster that data had been successfully mirrored. (Note that this behaviour should be fixed in Kafka 0.9.)
Mirror Makers occasionally got confused about who was the leader for consumption. The leader would sometimes forget that it was a leader, while the other Mirror Makers from the cluster would happily still try to follow it. When this happened, mirroring between data centers would stop.
The Kafka Producer also had serious issues with stability. If one or more brokers from a cluster was removed, or even just restarted, it was quite likely that the producer would enter a state from which it couldn’t recover by itself. While it was in such a state it wouldn’t produce any events. The only solution was to restart the whole service.
Even without solving these issues, we saw that a lot of work would be needed to make the system production-ready. We would need to define deployment strategies for Kafka Brokers and Mirror Makers, do capacity modelling and planning for all system components, and expose performance metrics to Spotify’s monitoring system.
We found ourself at a crossroads. Should we make a significant investment and try to get Kafka work for us? Or should we try something else?
Cloud Pub/Sub
While we were struggling with Kafka, various other Spotify teams were beginning to experiment with Google Cloud products. A particularly interesting products that was being assessed was Cloud Pub/Sub. It seemed as if Cloud Pub/Sub might satisfy our basic need for a reliable, persistent queue: it can retain undelivered data for 7 days, provide reliability through application-level acknowledgements, and has “at-least-once” delivery semantics.
As well as satisfying our basic needs, Cloud Pub/Sub came with extra goodies:
Global availability—as a global service, Pub/Sub is available in all Google Cloud Zones; transferring data between our data center wouldn’t be through our normal internet provider but would use underlying Google network.
A simple REST API—if we didn’t like client library Google provided, we can easily write our own.
Operational responsibility was handled by someone else—there was no need to create a capacity model or deployment strategy, or to set up monitoring and alerting.
It all sounded great on paper… but was it too good to be true? The solutions we’d built on Apache Kafka, while not perfect, has served us well. We had lots of experience of the different failure modes, access to the hardware and source code, and could—theoretically—find the root cause of any problem. Moving to a managed service would mean we’d have to trust operations of another organisation. And Cloud Pub/Sub was being advertised as beta software; we were unaware of any organisation other than Google who were using it at our scale.
With this in mind, we decided that we needed a comprehensive test plan to make absolutely sure that, if we were to go with Cloud Pub/Sub, it would meet allof our requirements.
The Producer load test
The first item on our agenda was testing Cloud Pub/Sub to see if it could handle the anticipated load. Currently our production load peaks at around 700K events per second. To account for the future growth and possible disaster recovery scenarios, we settled on a test load of 2M events per second. To make it extra hard for Pub/Sub, we wanted to publish this amount of traffic from a single data center, so that all the requests were hitting the Pub/Sub machines in the same zone. We made the assumption that Google plans zones as independent failure domains and that each zone can handle equal amounts of traffic. In theory, if we’re able to push 2M messages to a single zone, we should be able to push number_of_zones* 2M messages across all zones. Our hope was that the system would be able to handle this traffic on both the producing and consuming side for a long time without the service degrading.
Early on, we hit a stumbling block: the Cloud Pub/Sub Java client simply didn’t perform well enough. The client, like many other Google Cloud API clients, is auto-generated from API specifications. That’s good if you want clients that support a wide variety of languages, but not so good if you want a high performance client for a single language.
Thankfully Pub/Sub has a REST API, so it was easy to write our own library. We designed the new client with its performance foremost in our minds. To enable better use of resources, we used asynchronous Java. We also added queuing and batching in the client. (This wasn’t first time that we needed to roll our sleeves up and reimplement a Google Cloud API client: in another project we implemented a high performance client for the Datastore API.)
With our new client in place, we were ready to start pushing some serious load to Pub/Sub. We used a simple load generator to send mock traffic through the Event Service to Pub/Sub. The generated traffic was routed through two Pub/Sub topics with a ratio of 7:3. To push 2M messages per second, we ran the Event Service on 29 machines.

Figure 3. Number of successful requests per second to Pub/Sub from all data centers

Figure 4. Number of failed requests per second to Pub/Sub from all data centers

Figure 5. Incoming and outgoing network traffic for Event Service machines in bps
Pub/Sub passed the test with flying colours. We published 2M messages without any service degradation and received almost no server errors from the Pub/Sub backend. Enabling batching and compression on the Event Service machines resulted in ~1Gbps of network traffic towards Pub/Sub.

Figure 6. Google Cloud Monitoring graph for total published messages to Pub/Sub
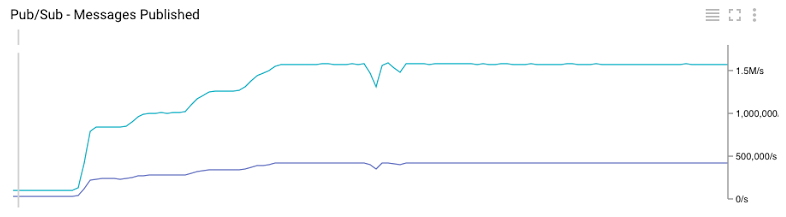
Figure 7. Google Cloud Monitoring graph for per topic published messages to Pub/Sub
A useful side-effect of our test was that we could compare our internal metrics with the metrics exposed by Google. As it can been seen by looking Figure 3 and Figure 6, the graphs match perfectly.
The Consumer stability test
Our second major test focused on consumption. Over a period of 5 days, we measured the end-to-end latency of the system under heavy load. For the duration of the test we published, on average, around 800K messages per second. To mimic real world load variations, the publishing rate varied according to the time of day. To verify that we could use multiple topics concurrently, all data was published to two topics with ratio 7:3.
A slightly surprising behaviour of Cloud Pub/Sub is that subscriptions need to be created before messages can be persisted: until the subscription exists, no data is retained. Every subscription stores data independently and there is no limit to how many consumers a subscription can have. Consumers are coordinated on the server side, and the server is responsible for fairly allocating the messages to all the consumers that request data. This is a very different to Kafka: in Kafka, data is retained per created topic and the number of Kafka consumers per topic is limited by the number of topic partitions.

Figure 8. The consumption test dashboard
In our test, we created a subscription, then one hour later we started to consume data. We consumed data in batches of 1000 messages. Since we didn’t try to push consumption as high as we could have, we only consumed events at a slightly higher rate than we were sending at peak. It took about 8 hours to catch up. Once we caught up, consumers kept consuming at a rate that matched the publishing rate.
The median end-to-end latency we measured during the test period—including backlog recovery—was around 20 seconds. We did not observe any lost messages whatsoever during the test period.
Decision
Based on these tests, we felt confident that Cloud Pub/Sub was the right choice for us. Latency was low and consistent, and the only capacity limitations we encountered was the one explicitly set by the available quota. In short, choosing Cloud Pub/Sub rather than Kafka 0.8 for our new event delivery platform was an obvious choice.
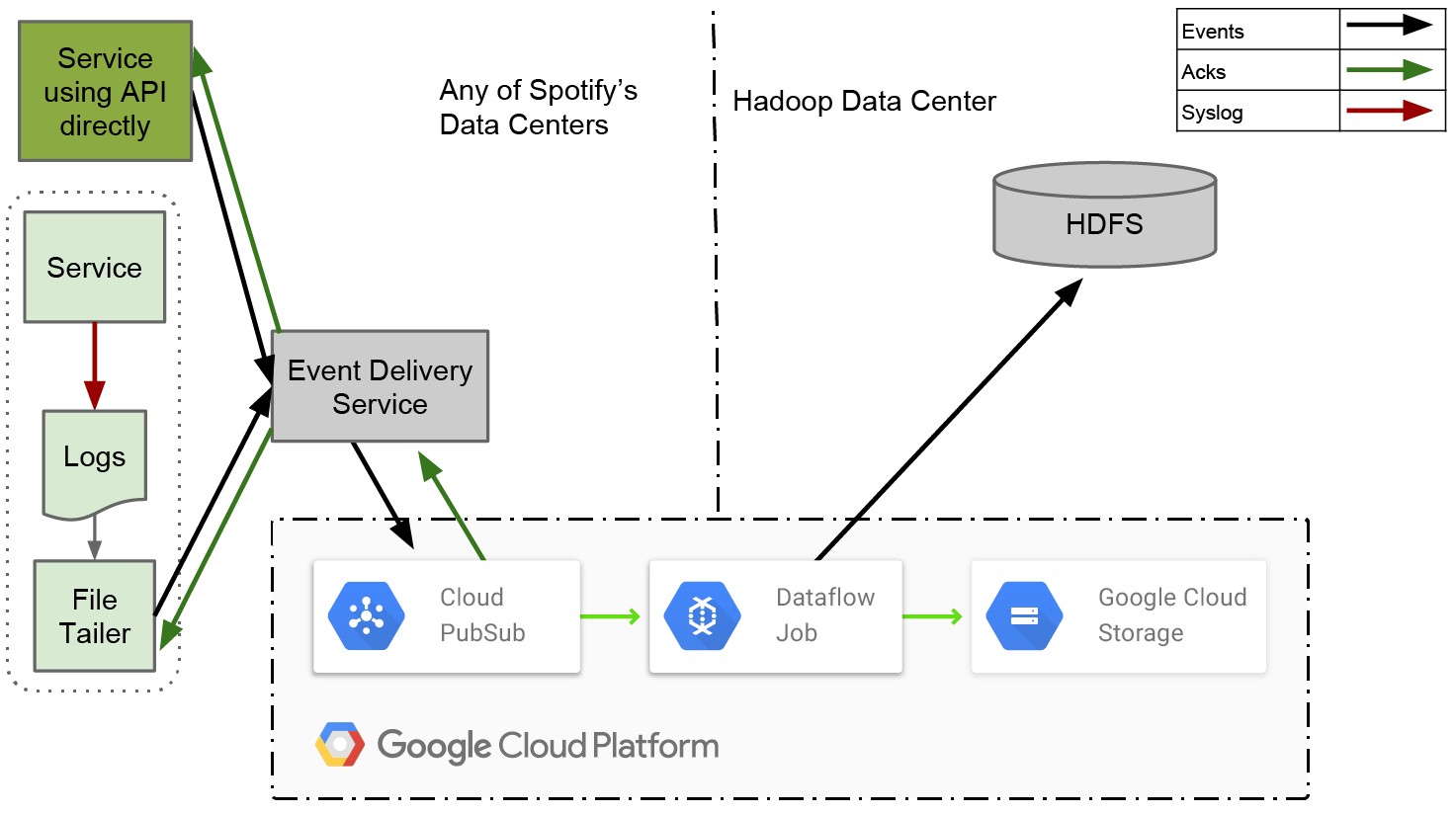
Figure 9. Event delivery system design in which we use Cloud Pub/Sub as reliable persistent queue
Next step
After events are safely persisted in Pub/Sub it’s time to export them to HDFS. To fully leverage the Google Cloud offering we decided to give a chance to Dataflow.
In the last blog post from this series we’re going to go through our plan on leveraging Dataflow for this job. Stay tuned.
SHARE THIS ARTICLE



