Big Data Processing at Spotify: The Road to Scio (Part 1)

This is the first part of a 2 part blog series. In this series we will talk about Scio, a Scala API for Apache Beam and Google Cloud Dataflow, and how we built the majority of our new data pipelines on Google Cloud with Scio.
Scio > Ecclesiastical Latin IPA: /ˈʃi.o/, [ˈʃiː.o], [ˈʃi.i̯o] > Verb: I can, know, understand, have knowledge.
Introduction
Over the past couple of years, Spotify has been migrating our infrastructure from on premise to Google Cloud. One key consideration was Google’s unique offerings of high quality big data products, including Dataflow, BigQuery, Bigtable, Pub/Sub and many more.
Google released Cloud Dataflow in early 2015 (VLDB paper), as a cloud product based on FlumeJava and MillWheel, two Google internal systems for batch and streaming data processing. Dataflow introduced a unified model to batch and streaming that consolidates ideas from these previous systems, and the Google later donated the model and SDK code to the Apache Software Foundation as Apache Beam. With Beam, an end user can build a pipeline using one of the SDKs (currently Java and Python), which gets executed by a runner for one of the supported distributed systems, including Apache Apex, Apache Flink, Apache Spark and Google Cloud Dataflow.
Scio is a high level Scala API for the Beam Java SDK created by Spotify to run both batch and streaming pipelines at scale. We run Scio mainly on the Google Cloud Dataflow runner, a fully managed service, and process data stored in various systems including most Google Cloud products, HDFS, Cassandra, Elasticsearch, PostgreSQL and more. We announced Scio at GCPNEXT16 last March and it’s been gaining traction ever since. It is now the preferred data processing framework within Spotify and has gained many external users and open source contributors.
In this first post we will take a look at the history of big data at Spotify, the Beam unified batch and streaming model, and how Scio + Beam + Dataflow compares to the other tools we’ve been using. In the second post we will look at the basics of Scio, its unique features, and some concrete use cases at Spotify.
Big Data at Spotify
At Spotify we process a lot of data for various reasons, including business reporting, music recommendation, ad serving and artist insights. We serve billions of streams in 61 different markets and add thousands of new tracks to our catalogue every day. To handle this massive inflow of data, we have a ~2500 node on-premise Apache Hadoop cluster, one of the largest deployments in Europe, that runs more than 20K jobs a day.
Spotify started as a Python shop. We created Luigi for both job orchestration and Python MapReduce jobs via Hadoop streaming. As we matured in data processing, we began to use a lot of Scalding for batch processing. Scalding is a Scala API from Twitter that runs on Cascading, a high-level Java library for Hadoop MapReduce. It allows us to write concise pipelines with significant performance improvement over Python. The type-safe functional paradigm also boosts our confidence in code quality and correctness. Discover Weekly, one of our very popular features, is powered by Scalding (BDS2015 talk). We also use Apache Spark for some machine learning applications, leveraging its in-memory caching capability for iterative algorithms.
On the streaming side we’ve been using Apache Storm for a few years now to power real time use cases like new user recommendation, ads targeting and product metrics. Most pipelines are fairly simple, consuming events from Apache Kafka, performing simple filtering, aggregation, metadata lookups, and saving output to Apache Cassandra or Elasticsearch. The Storm API is fairly low level which limited its application for complex pipelines. We’ve since moved from Kafka to Google Cloud PubSub for ease of operations and scaling.
Apart from batch and streaming data processing, we also do a lot of ad-hoc analysis using Hive. Hive allows business analysts and product managers to analyze huge amounts of data easily with SQL-like queries. However Hive queries are translated into MapReduce jobs which incur a lot of IO overhead. On top of that we store most of our data in row-oriented Avro files which means any query, regardless of actual columns selected, requires a full scan of all input files. We migrated some core datasets to Apache Parquet, a columnar storage format based on Google’s Dremel paper. We’ve seen many processing jobs gaining 5-10x speed up when reading from Parquet. However support in both Hive and Scalding has some rough edges and limited its adoption. We’ve since moved to Google BigQuery for most ad-hoc query use cases and have experienced dramatic improvements in productivity. BigQuery integration in Scio is also one of its most popular features which we’ll cover in the second part.
Beam Model
Apache Beam is a new top level Apache project for unified batch and streaming data processing. It was known as Google Cloud Dataflow before Google donated the model and SDK code to the Apache Software Foundation. Before Beam the world of large scale data processing was divided into two approaches: batch and streaming. Batch systems, e.g. Hadoop map/reduce, Hive, treat data as immutable, discrete chunks, e.g. hourly or daily buckets, and process them as a single unit. Streaming systems, e.g. Storm, Samza, process continuous streams of events as soon as possible. There is prior work on unifying the two, like the Lambda and Kappa architectures, but none which address the different mechanics and semantics in batch and streaming systems.
Beam implements a new unified programming model for batch and streaming introduced in the Dataflow paper. In this model, batch is treated as a special case of streaming. Each element in the system has an implicit timestamp and window assignment. In streaming mode, the system consumes from unbounded (infinite and continuous) sources. Events are assigned timestamps at creation (event time) and windowed, e.g. fixed or sliding window. In traditional batch mode, elements are consumed from bounded (finite and discrete) sources and assigned to the same global window. Timestamps usually reflect the data being processed, i.e. hourly or daily bucket.
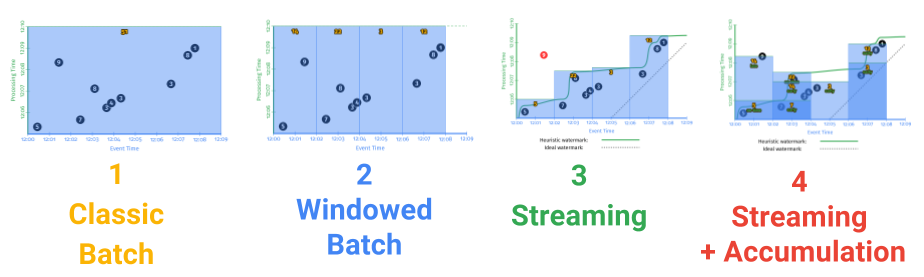
Beam Model
This model also abstracts parallel data processing as two primitive operations, parallel do (ParDo) and group by key (GBK). ParDo, as the name suggests, processes elements independently in parallel. It is the primitive behind map, flatMap, filter, etc. and behaves the same in either batch or streaming mode. GBK shuffles key-value pairs on a per window basis to collocate the same keys on the same workers and powers groupBy, join, cogroup, etc. In the streaming model, grouping happens as soon as elements in a window are ready for processing. In batch mode with single global window, all pairs are shuffled in the same step.
With this simple yet powerful abstraction, one can write truly unified batch and streaming pipelines in the same API. We can develop against sampled log files, parsing timestamps and assigning windows to log lines in batch mode, and later run the same pipeline in streaming mode using Pub/Sub input with little code change. Checkout Beam’s mobile gaming examplesfor a complete set of batch + streaming pipeline use cases.
Enter Scio
We built Scio as a Scala API for Apache Beam’s Java SDK and took heavy inspiration from Scalding and Spark. Scala is the preferred programming language for data processing at Spotify for three reasons:
Good balance between productivity and performance. Pipeline code written in Scala are usually 20% the size of their Java counterparts while offering comparable performance and big improvement over Python.
Access to large ecosystem of both infrastructure libraries in Java e.g. Hadoop, Beam, Avro, Parquet and high level numerical processing libraries in Scala like Algebirdand Breeze.
Functional and type-safe code is easy to reason about, test and refactor. These are important factors in pipeline correctness and developer confidence.
In our experience, Scalding or Spark developers can usually pick up Scio without any training while those from Python or R background usually become productive within a few weeks and many enjoy the confidence boost from functional and type-safe programming.
So apart from the similar API, how does Scio compare to Scalding and Spark? Here are some observations from different perspectives.
Programming model
Spark supports both batch and streaming, but in separate APIs. Spark supports in-memory caching and dynamic execution driven by the master node. These features make it great for iterative machine learning algorithms. On the other hand it’s also hard to tune at our scale.
Scalding supports batch only and there’s no in-memory caching or iterative algorithm support. Summingbird is another Twitter project that supports batch + streaming using Scalding + Storm. But this also means operating two complex systems.
Scio supports both batch and streaming in the same API. There’s no in-memory caching or iterative algorithm support like Spark but since we don’t use Scio mainly for ML it has not been a problem.
Operational modes
With Spark, Scalding, Storm, etc. you generally need to operate the infrastructure and manage resources yourself, and at Spotify’s scale this usually means a full team. Deploying and running code often requires both knowledge of the programming model and the infrastructure you’re running it on. While there are services like Google Cloud DataProc and similar Hadoop-as-a-Service products, they still require some administrative know-how to run in a scalable and cost-effective manner. Spydra and Netflix’s Genie are some examples of additional tooling for such operation.
Scio on Google Cloud Dataflow is fully managed, which means there is no operational overhead of setting up, tear down or maintaining a cluster. Dataflow supports auto-scaling and dynamic work rebalancing which makes the jobs more elastic in terms of resource utilization. A data engineer can write code and deploy from laptop to the cloud at scale without any operational experience.
Google Cloud Integration
While there are Hadoop connectors for GCS, BigQuery, plus native clients for several other products, the integration of these with Scalding and Spark is nowhere near as seamless as that of Dataflow.
This is where Dataflow shines. Being a Google project, it comes with connectors for most Google Cloud big data projects, including Cloud Storage, Pub/Sub, BigQuery, Bigtable, Datastore, and Spanner. One can easily build pipelines that leverage these products.
By moving to Scio, we are simplifying our inventory of libraries and systems to maintain. Instead of managing Hadoop, Scalding, Spark and Storm, we can now run the majority of our workloads with a single system, with little operational overhead. Replacing other components of our big data ecosystem with managed services, e.g. Kafka with Pub/Sub, Hive with BigQuery, Cassandra with Bigtable, further reduces our development and support cost.
This concludes the first part of this blog series. In the next part we’ll take a closer look at Scio and its use cases. Stay tuned.
SHARE THIS ARTICLE



