Big Data Processing at Spotify: The Road to Scio (Part 2)

In this part we’ll take a closer look at Scio, including basic concepts, its unique features, and concrete use cases here at Spotify.
Basic Concepts
Scio is a Scala API for Apache Beam and Google Cloud Dataflow. It was designed as a thin wrapper on top of Beam’s Java SDK, while offering an easy way to build data pipelines in idiomatic Scala style. We drew most of our inspiration for the API from Scalding and Spark, two libraries that we already use heavily at Spotfiy.
Here’s the ubiquitous word count example in Scio, which looks almost identical in Spark and is very similar in Scalding. It’s also a lot more concise and readable compare to the Beam Java version.
import com.spotify.scio._
object MinimalWordCount {
def main(cmdlineArgs: Array[String]): Unit = {
val (sc, args) = ContextAndArgs(cmdlineArgs)
sc.textFile(args("input"))
.flatMap(_.split("[^a-zA-Z0-9']+").filter(_.nonEmpty))
.countByValue
.map(t => t._1 + ": " + t._2)
.saveAsTextFile(args("output"))
sc.close()
}
}
The core abstract data type in Scio is SCollection, which wraps the Beam PCollection type and mimics Spark’s RDD by providing parallel operations e.g. map, flatMap, filter. An SCollection of key-value tuples also provides group operations, e.g. join, cogroup, reduceByKey, via PairSCollectionFunctions, similar to Spark’s PairRDDFunctions. By translating Beam Java boilerplate into idiomatic Scala functions, many of which are one-liners, Scio allows users to focus on business logic and makes it easier to evolve and refactor code.
Scio not only wraps Java transforms already available in Beam, but also provides a lot of syntactic sugar for common but complex operations. In addition to the common inner, left-outer and full-outer joins, we also implemented side-input based hash joins to avoid shuffle for small right-hand sides; skewed and sparse-outer joins for extreme data sizes. We use Twitter’s Algebird heavily for parallel and approximate statistical computations and support Semigroup and Aggregator out of the box in Scio.
Beam uses Coder for (de)serializing data in a PCollection during shuffle and disk IO, and provides implementations for common Java types, collections, and libraries like Avro, Protobuf. However Scala types are not covered, and due to type erasure, the library often could not infer which coder to use and required the user to specify it explicitly. Scio instead uses a combination of Scala reflection and Chill to handle serialization. Chill is a serialization library from Twitter built on top Kryo and used by Scalding, Spark and Storm. It includes implementations for common Scala types and can also automatically derive serializers for arbitrary objects. The automatic handling of serialization further reduces user’s tasking loading when writing pipelines.
Unique Features
Scio also offers several unique features that changed the way we build data pipelines. Type-safe BigQuery is probably the most prominent one.
BigQuery is the most heavily used Google big data product at Spotify. Over 500 unique users made over one million queries in August 2017, processing 200PB of data. For common operations like filtering, grouping and simple aggregation, BigQuery is often magnitudes faster and cheaper than writing a custom data pipeline, but sometimes we do want to integrate query results with complex logic that is hard to express in SQL. The official BigQuery API represents results as JSON or Map[String, Any] in Scala, a.k.a. stringly-typed objects which are hard to work with and error prone.
Instead we built Scala macros to generate case classes as a type-safe representation of our data at compile time. A pipeline that consumes BigQuery result might look like this:
@BigQueryType.fromQuery(
"SELECT tornado, month FROM `publicdata.samples.gsod` WHERE month == 1")
class Row
sc.typedBigQuery[Row]()Even though there’s no definition for class Row, our macro performs a query dry-run and generates the class definition automatically:
case class Row(tornado: Option[Boolean], month: Long)The macro also generates converters from and to BigQuery JSON. This makes it a lot easier and safer when working with BigQuery data. To work around IntelliJ IDEA’s limitation with macro generated code, we built our own scio-idea-plugin so that tab-completion and code inspection works seamlessly in the IDE.
Scio also comes with a REPL similar to Spark shell and Scalding REPL. This allows the user to interactively explore data and code snippets, which proves to be very useful for ad-hoc analytics type of tasks.
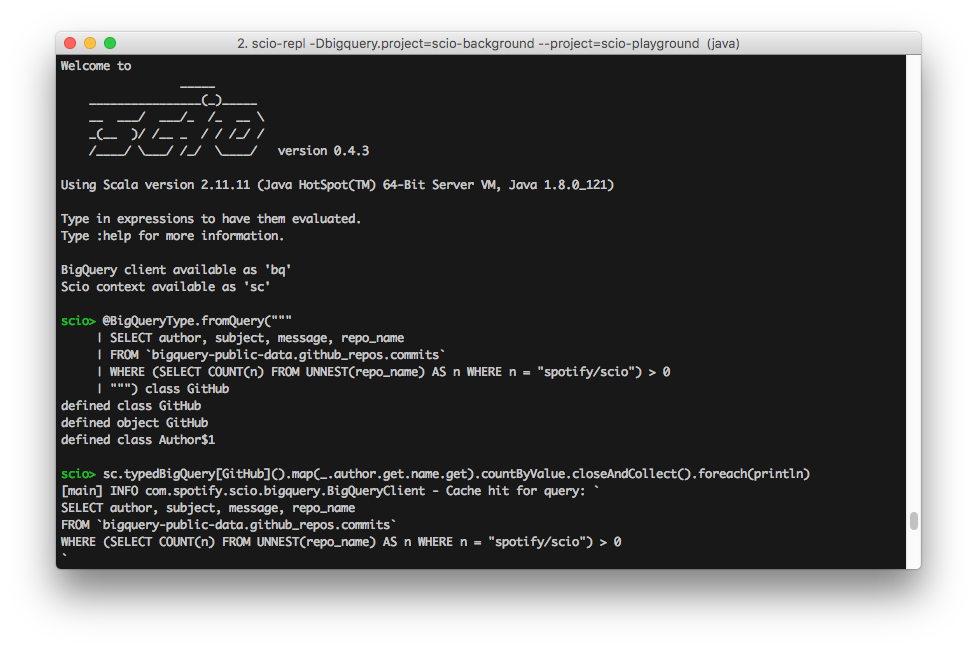
Analyzing GitHub Commits with Scio REPL
Finally, Scio also includes easy integration with many other systems.
Parquet file IO
Cassandra 2.x and 3.x bulk sinks
Elasticsearch 2 and 5 sinks
TensorFlow TFRecords IO and prediction API
Distributed cache
Use Cases
We announced Scio around 18 months ago, and after a trial period with a few teams, started company wide adoption about 12 months ago. Within this short period more than 200 internal users, most of them new to Scala, built more than 1300 production pipelines, about 10% of them streaming. In total Scio powers 80,000 Dataflow jobs per month. It is now the first choice tool for building data pipelines, and we use it for everything include music recommendation, ads targeting, AB testing, behavioral analysis and business metrics.
Number of Production Scio Pipelines at Spotify
We’ve pushed Scio to a scale comparable or in some cases much bigger than legacy systems. The largest batch job we’ve seen uses 800 n1-highmem-32 workers (25600 CPUs, 166.4TB RAM) and processes 325 billion rows in 240TB from Bigtable. We also have numerous jobs that process 10TB+ of BigQuery data daily. On the streaming front we have many jobs with 30+ n1-standard-16 workers (480 CPUs, 1.8TB RAM) and SSD disks for real time recommendation and reporting. |
Largest Batch Scio Pipeline at Spotify |

BigDiffy was probably the first complex use of Scio. It’s a pairwise, field-level statistical diff tool for big datasets. Given 2 collections of structured data (JSON, Avro, Protobuf, etc.) and a key function, we group elements from both sides into keyed pairs for comparison. A numeric delta can be computed for each pair of leaf fields, e.g. subtraction for numbers, Levenshtein distance for strings, cosine distance for vectors, and Jaccard distance for sets. We can then aggregate deltas across all pairs and fields for high-level statistics about the datasets.
From the aggregation, we get the number of pairs that are same, different, missing left or right hand side, plus the list of keys that fall into each of these categories. Drilling down to field level, we get the count, min, max, mean, standard deviation, skewness and kurtosis of each field’s deltas across the entire data set. By leveraging Scio and Algebird, the entire code base is only a few hundred lines and most of the computation logic handled by Algebird abstractions.
BigDiffy is particularly useful when porting legacy pipelines to Scio, where one can simply compare outputs of the old vs. the new pipeline. It’s also great for machine learning applications where we track dataset change overtime and test if an algorithm change causes statistically significant difference.
Featran is another tool we build on top of Scio. It’s a feature transformation library for data science and machine learning. Featran provides a Scala DSL for composing feature transformations, e.g. one-hot encoding, standard scaling, normalization, quantile discretization, in specification style. The library translates the specification into a single reduce + map step over the dataset. Some of our machine learning researchers use Featran to transform billions of records, generating millions of features for deep learning in TensorFlow.
There are roughly a dozen external organizations using Scio for both batch and streaming pipelines. Some of them are listed in this wiki page. While most users run it on Dataflow, we’ve also heard reports of users running it on Flink.
Conclusion
This concludes the two part blog series on Scio. Overall we’re very happy with the results and continue to see its adoption grow both within and outside the company. It’s also still under heavy development as we’re constantly adding new features, fixing bugs and following up with upstream Apache Beam development. Give it a try on and let us know what you think.
SHARE THIS ARTICLE


