Introducing cstar: The Spotify Cassandra orchestration tool, now open source

Today, we announce that we are open sourcing cstar, our Cassandra orchestration tool.
Operating Cassandra is not always an easy task. It has a myriad of knobs you can tune that affect performance, security, data consistency etc. Very often you need to run a specific set of shell commands on each node of a cluster, usually in some coordination to avoid the cluster being down. This can be done manually for small clusters, but can get tricky and time consuming for big clusters. And what if you need to run those commands on all Cassandra nodes in the company? During 2017 the Spotify Cassandra fleet reached 3000 nodes, having a safe and efficient solution for this task was becoming increasingly urgent.
One such task was a scheduled upgrade of our entire Cassandra fleet. Unsurprisingly, our upgrade process turned into a kafkaesque nightmare:
Clear all snapshots (to have enough disk space to finish the upgrade)
Take a new snapshot (to allow a rollback)
Disable automated puppet runs
Stop the Cassandra process
Run puppet from a custom branch of our git repo in order to upgrade the package
Start the Cassandra process again
Update system.schema_columnfamilies to the JSON format
Run
nodetool upgradesstables, which depending on the amount data on the node could take hours to completeRemove the rollback snapshot
We did not want to leave partially upgraded clusters overnight, because repairs and various other background tasks don’t work across Cassandra versions. But since we have clusters with hundreds of nodes, upgrading one node at a time is unrealistic. On the other hand, we can’t upgrade all nodes at once, since that would take down the whole cluster. We needed an efficient and robust method to perform all of these operations on thousands of computers in an orchestrated fashion.
More complexities
In addition to the outlined performance problems, some other complications when dealing with Cassandra at our scale:
Temporary network failures, breaking SSH connections, etc. happen all the time.
Operations that are computation heavy or involve restarting the Cassandra process/node should be executed in a particular order to avoid impacting performance and availability. You should not bring down more than one node in the same token range (usually we have 3 replicas for each token range, so this means one in every 3 nodes at most). This constraint makes parallelization non-trivial.
Nodes can go down at any time, so the status of the cluster should be checked not just before running the task, but also before execution is started on a new node. This also makes parallelization non-trivial, at least if you want to do it in a safe way.
How should partially finished executions be handled? (i.e. the task succeed on some nodes but not on others). What about error messages?
Over the years, we have done this in many different ways depending on what task was at hand. For instance, we built the Cassandra Reaper to solve the repairing problem.
The most common way of running commands or scripts on multiple Cassandra hosts in the early Spotify days was to open up multiple terminals and typing the command in everywhere at once:
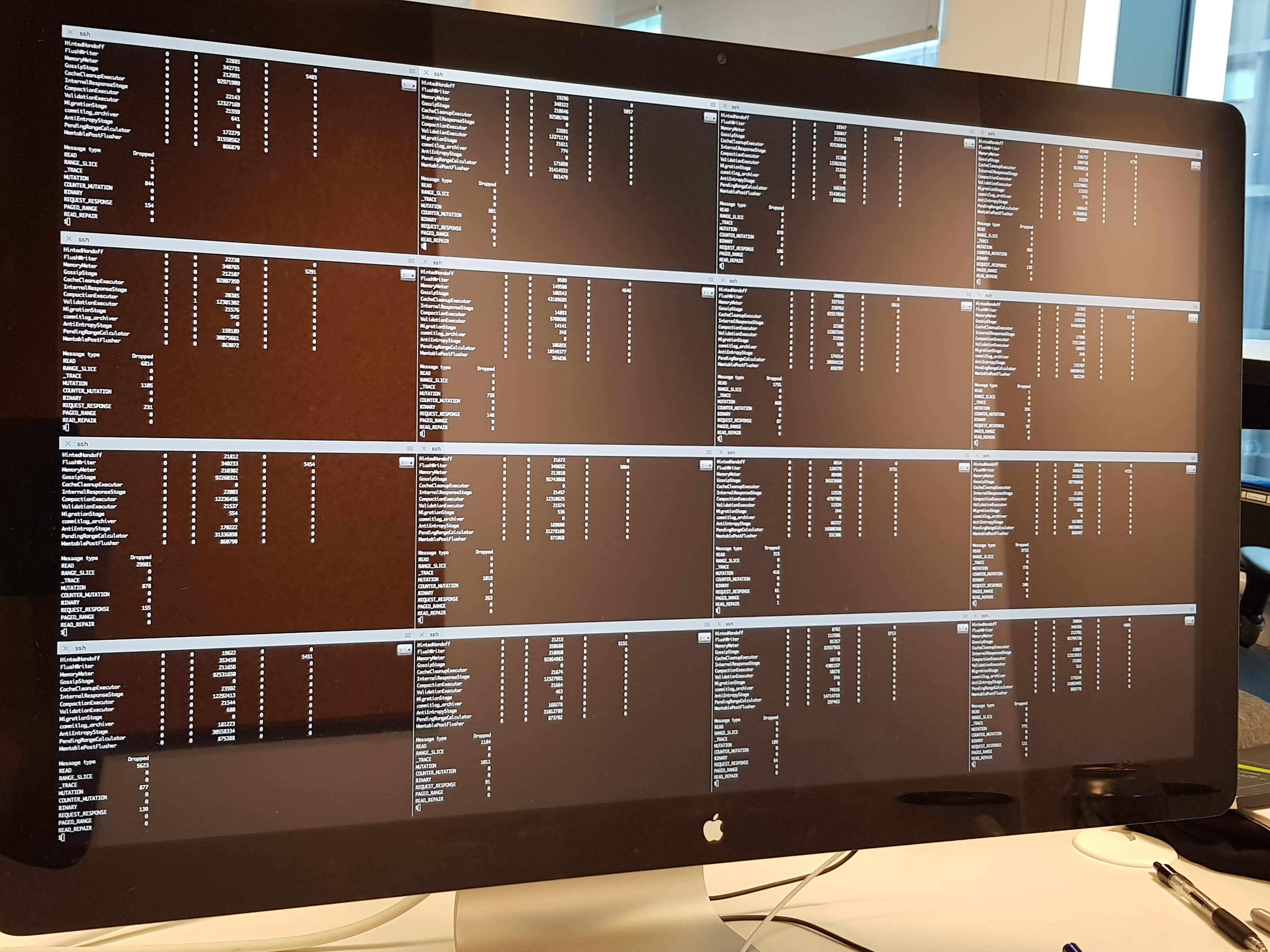
Sixteen SSH sessions running in sixteen terminal panes: The precursor to cstar.
Why not Ansible or Fabric?
Ansible and Fabric can both be made to run commands in parallel on groups of machines, but out of the box, neither of them is topology aware. With some wrapper scripts and elbow grease, it is possible to split a cassandra cluster into multiple groups, and execute a script on all machines in one group in parallel. However, this solution doesn’t wait for Cassandra nodes to come back up before proceeding, nor does it notice if random Cassandra nodes go down during execution. Some initial attempts showed that a solution based on wrapping Fabric or Ansible were possible but somewhat flaky and unpleasant to use.
cstar to the rescue
cstar is a command line tool that runs an arbitrary script on all hosts in a Cassandra cluster in “topology aware” fashion. It’s based on paramiko, the same ssh/scp implementation that Fabric uses.
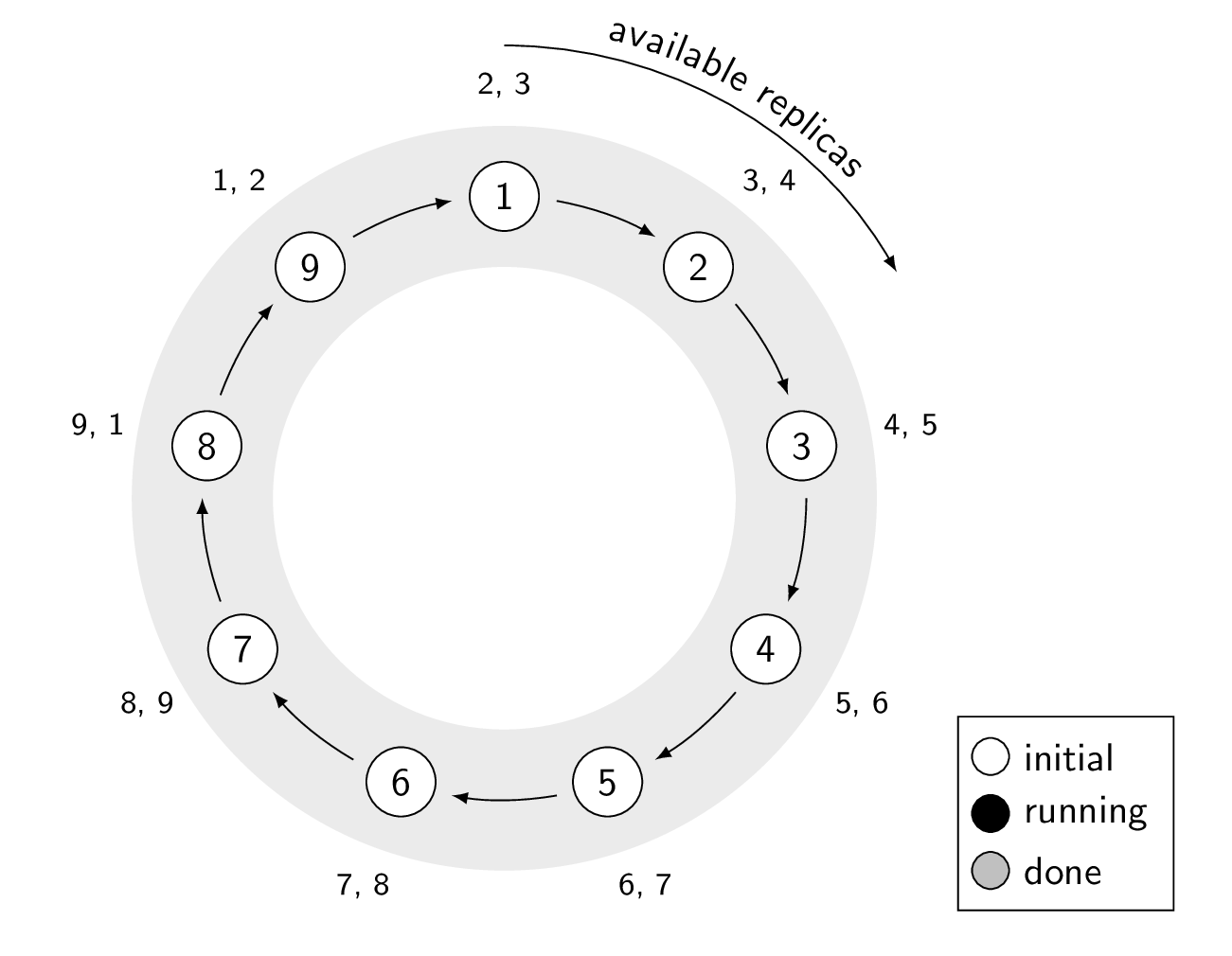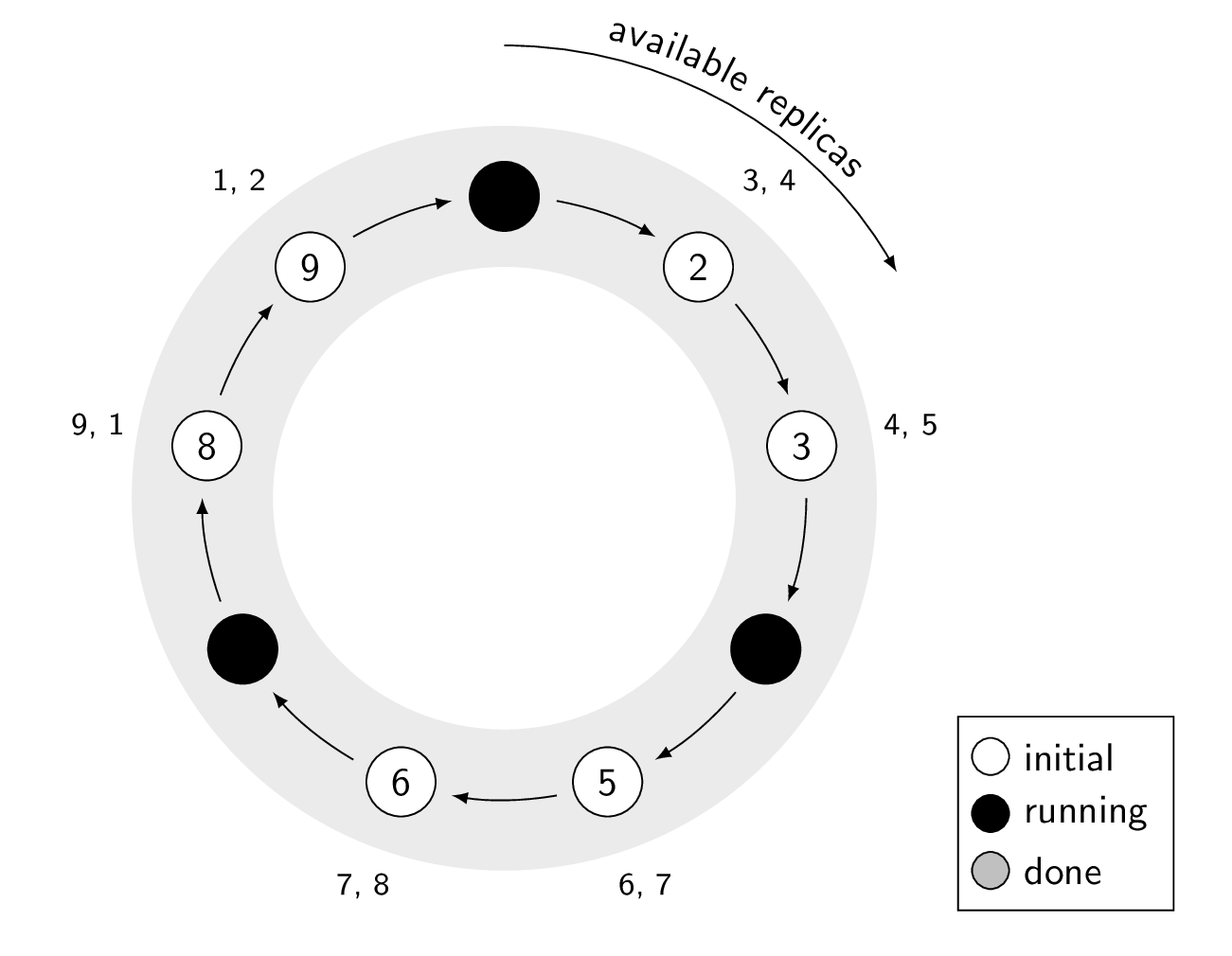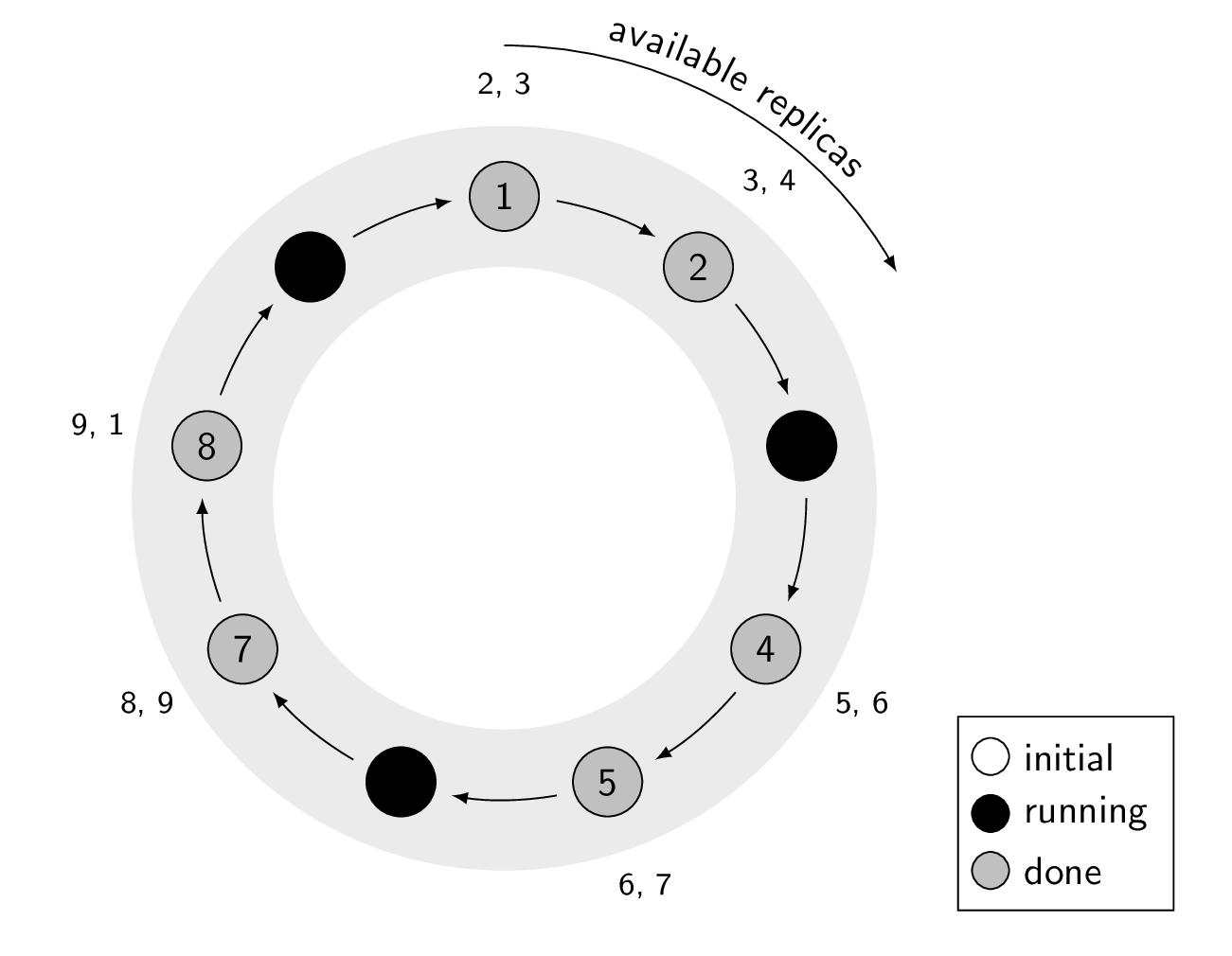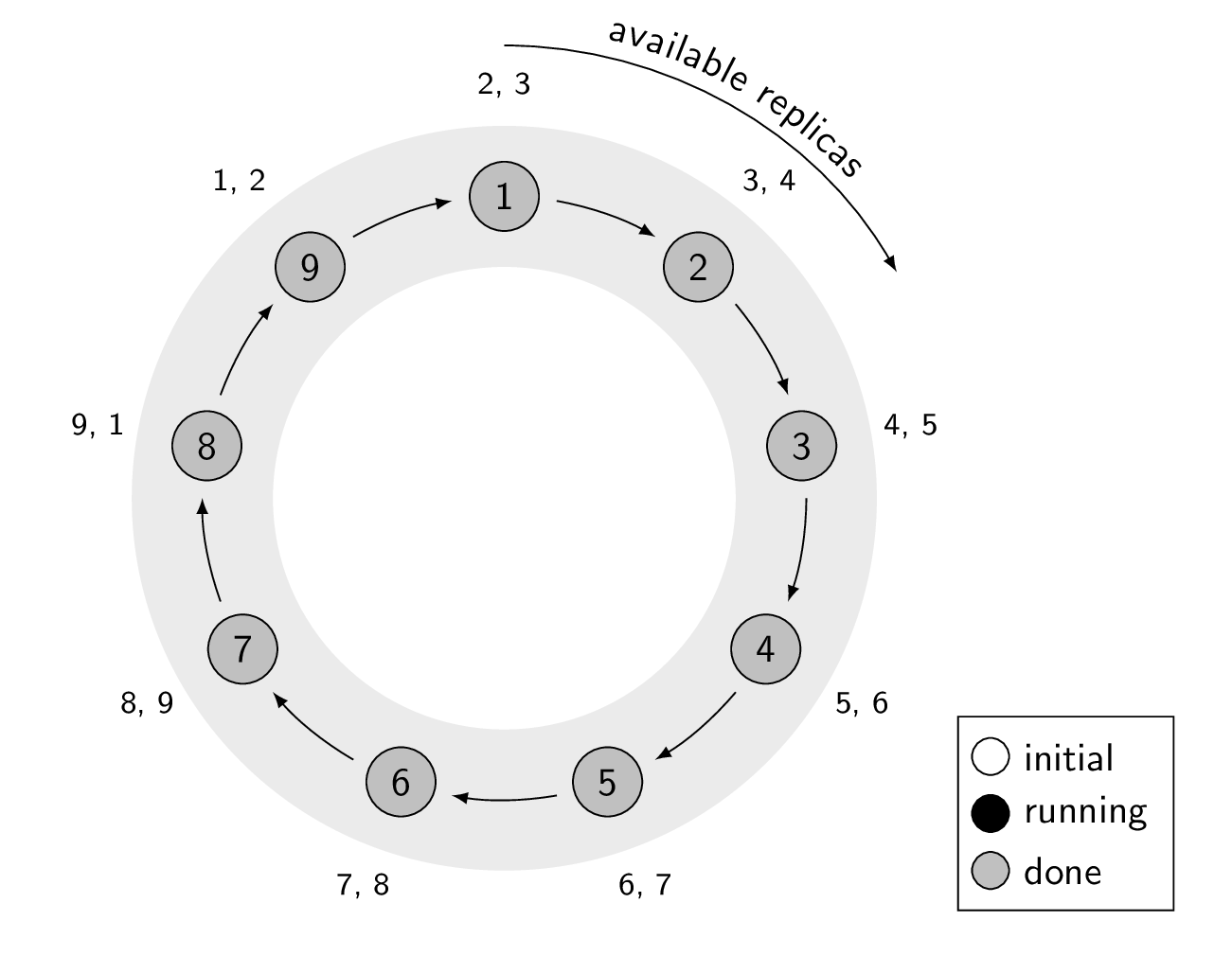
Example of cstar running on a 9 node cluster with replication factor of 3, with the assumption that the script brings down the Cassandra process. Notice how there are always 2 available replicas for each token range.
cstar supports the following execution mechanisms:
ONE. The script is run on exactly one node per data center at the time.
TOPOLOGY. As many nodes at the same time as the Cassandra topology allows. That is, it will not run on two nodes in the same data center if a replica can be on both nodes. If you have N data centers with M nodes each and replication factor of X, this effectively runs the script on M/X * N nodes at the time.
ALL. The script run on all nodes at the same time, regardless of the topology.
The topology is inferred from a single seed node. That and the script itself is the only input needed. Installing cstar and running a command on a cluster is as easy as this example:
Jobs
Another powerful feature of cstar is the concept of jobs. Execution of a script on one or more clusters is a job. Job control in cstar works like in Unix shells, you can pause running jobs and then resume them at a later point in time. It is also possible to configure cstar to pause a job after a certain number of nodes have completed. This is useful since you can run your cstar job on one node, then manually validate that the job worked as expected, after which you can resume the job.
In closing
We’ve been using cstar in production for almost a year, and we’ve found it has significantly improved our experience running our Cassandra clusters. We are open sourcing it today in the hope that it will do the same for you.
SHARE THIS ARTICLE