Scalable User Privacy

At Spotify, we have a complex and diverse data processing ecosystem. Our backend infrastructure handles millions of requests per second, which are processed by over a thousand (micro)services. Our batch pipeline environment is equally complex and diverse; we run thousands of jobs written in a variety of frameworks such as Scio, BigQuery, Apache Crunch and Spark. The data processed by these services and pipelines power critical parts of our organization. We use data to calculate royalties, run A/B tests, process payments, serve playlists and suggest new tracks to our users.
Despite cultivating such an ecosystem, there are a few areas where we need a company-wide standard. Privacy is one of these areas; as it is time consuming and resource-intensive to verify the integrity of several different approaches, we need a single approach that works everywhere.
In this post, we will discuss one of the infrastructure systems that helps our developers build systems that are compliant with our privacy standards.
Why we encrypt
One of the standards we have set at Spotify is that personal data of our users can only be persisted when it is encrypted. Each user has their own set of keys that should be used for the encryption. We set this standard for two reasons. First, because it reduces the impact of leaking a dataset, since the dataset by itself is useless – attackers also need the decryption keys. Second, because it allows us to control the lifecycle of data for individual users centrally.
The latter reason is especially important, because if all data belonging to a user is encrypted with a single keychain, deleting that keychain guarantees the data is inaccessible. This means that we have an efficient way of removing all data associated with an individual user, without reliance on a full listing of all systems and datasets that may have data about the user.
This is a big win for a company like Spotify, where we highly value the autonomy of squads (our term for teams). We believe squads should have freedom in designing their systems and that dependencies between squads should be minimized. Having a simple rule – encrypt data before you store it – that ensures compliance and helps us uphold our privacy standards with minimal overhead to squads.
Before choosing encryption, we considered two alternative approaches for managing the lifecycle of data about our users. The first was to require services to include a deletion endpoint, which would remove an individual user when queried with the user’s userid. To delete a user, we would call the delete endpoint on all services. Once all systems acknowledged the delete, all data of the user would be removed.
The downsides of this approach are that it is very difficult to provide any guarantees that it successfully ran on all systems, and that it requires each squad to correctly implement and maintain their own solution for each system they own. For smaller companies with only a few backend services, this may work, but for a company that has over a thousand microservices (and growing) this is simply not viable. Additionally, this approach only works for backend systems: it does not work for our datasets. We want to keep our datasets immutable, because scanning through petabytes of data every time we want to delete a few rows for a single user is too expensive.
The second approach we considered but later rejected is tokenization. Instead of storing personal data in a system, one would store all personal data in a central database and other systems would only store tokens that reference entries in the central database. If the central database correctly manages the data lifecycle, other systems do not have to implement their own solutions.
This approach seems promising for highly structured data, but is difficult to scale to hundreds of services and thousands of datasets. Our systems have very different requirements on their storage mediums; some require low latency, others high throughput; some have small payloads (email addresses), others have big payloads (profile images). The access pattern also wildly differs, which makes caching difficult. Altogether, a central storage system that serves all needs was not an achievable solution.
Introducing Padlock: a global key-management system
The rest of this post will discuss the infrastructure system that helps squads encrypt the personal data processed by their services. We call this system Padlock. Padlock is our key management service that manages keychains for all Spotify users. Each time a service has to process personal data, it first queries Padlock to get the keychain needed to encrypt or decrypt the data. This means, for example, that every time a user looks at a playlist (even their own), the playlist service makes a call to Padlock to get the keychain of the playlist owner and decrypt the playlist.
Each service that calls Padlock gets its own set of keys. We do this to reduce the impact of a single service being compromised and leaking its keys. Padlock internally stores a set of root keys for every user; these root keys are never exposed to calling services. When services call Padlock, they include a secret service key, which is unique to that service. We use a key derivation algorithm that takes a root key and the service key and returns a derived key. The services use the derived keys for encryption and decryption.
To provide more fine-grained granularity for data lifecycles, we defined several data categories. Each user has a separate key for every category. This allows us to manage each category independent of the others. For example; when a user opts out of targeted advertisement, we can easily block access to this user’s personal data related to targeted advertisement by removing the corresponding key.
Building at Spotify scale
Since Padlock is involved in all requests that process personal data, we have three big requirements on the service:
It needs to scale to handle the aggregate load of dozens of other services. Some core features (like login, playlist and spotify-connect) process personal data, and call Padlock on every request. We designed Padlock to scale linearly, with an initial capacity of one million lookups per second.
It needs to have low latency; many systems add Padlock’s latency on top of their own, so every millisecond counts. The initial SLO was to have a p99 response time of under 15 milliseconds for all lookups. During normal operations, the p99 is under 5ms.
It needs to be highly available; downtime of Padlock means all systems that process personal data are effectively down. We set an SLO of 99.95% availability, and might increase this to 99.99%.
Fortunately, Padlock has some properties that make it relatively easy to scale. First, the traffic is heavily read-dominated; less than 0.1% of requests are inserts or updates. Second, fetching keychains only requires consistency within a single row; even multi-gets (which fetch multiple users in a single GET request) are implemented as independent get operations in the service. These properties make it simple to cache data and scale without requiring much communication between nodes.
At Spotify, our go-to database for globally replicated, highly available storage is Cassandra. Since our infrastructure runs on the Google Cloud, Cassandra has new competition in the form of Bigtable and Spanner. However, when we started developing Padlock, BigTable and Spanner were untested inside Spotify and Cassandra was still the obvious choice given the scalability and global replication requirement. Now that there is more operational experience in Spotify with Google’s cloud-native storage solutions, we are reassessing this choice.
Read requests to Cassandra are cached on a memcached cluster. (For reference, you can find Folsom, an open source version of our client here.) The p99 request latency to our memcached cluster is between 2 and 4 milliseconds, while the request latency to our Cassandra cluster is around 10 milliseconds. When serving traffic without cache, Cassandra request latency grows to a p99 of about 15 milliseconds. Thus, having a memcached cluster for caching lowers our p99 by about 10 milliseconds. (Latencies are measured on the client and include delays caused by the network.)
We made a number of optimizations in how we use Cassandra to help us get the most out of our setup:
All reads are done with LOCAL_ONE consistency. If the read cannot find the key (which should never happen, assuming we only request existing user IDs) we retry the read with LOCAL_QUORUM consistency. Retrying with a higher consistency level ensures we always return existing users, while the initial low consistency level keeps the latency down. We tolerate staleness of a few seconds for updates, since opt-outs do not have to be processed instantly; only fresh writes (newly signed up users) have to be readable instantly since their keys are used by other services during the signup process.
We disabled read repair (both local and global). Read repairs will probabilistically perform repairs by requesting digests of a row from several replicas to verify that all replicas store consistent values. To do this, the node coordinating a query must request digests from all replicas not involved in the read (for dc_local_read_repair only replicas in the same datacenter). A single LOCAL_ONE read could trigger dozens of digest requests that have to travel across the world, just to check for consistency between replicas. This happens as a background process and should not affect latency, but in a cluster that processes hundreds of thousands of reads per second it is a non-negligible overhead.
We don’t use row caching. Caching is handled by memcached so there are almost no repeated requests to the database. This access pattern makes row caching superfluous. We can instead use the memory to load SSTables into pagecache, or just provision skinnier machines.
Avoiding tombstones. This is not a performance optimization, but about reliability. We have seen various incidents related to tombstones that follow days after network splits or cluster topology changes. To avoid this class of incidents, we designed our table schema to avoid tombstones, for example by not using multi-value data types (like maps or lists).
Padlock does not implement any retries internally. Instead, we fail fast and leave it up to our clients to decide if they want to retry. For services calling Padlock with a high request rate (like playlist), increased latency is as devastating as failures because their request queue fills up quickly. Clients are free to retry, if they require more certainty that their requests will succeed. The payment systems, for example, all use retries.
Running Padlock with high reliability
Since Padlock is involved in so many request flows, we spent a lot of effort making it a reliable system. Padlock is not the only single point of failure system, but it is custom-built and a new system. We’ll go through some of the ways we try to make our system as reliable as we can without sacrificing development speed.
First of all, all code changes are first deployed in a staging environment that does not have any real clients connected to it. Many core systems at Spotify are deployed in this environment, so it helps us test both our own system and the integrations with many other systems. Once we see the system behaves well in this staging environment, we have a 3-stage rollout process for code deploys that requires manual approval to continue to the next stage. It starts with a single canary machine, then a single region (we call this the “albatross”) and finally global.
Second, we provision Padlock in all locations where Spotify has a presence. Currently that means it runs in three regions (in America, Europe and Asia), in three zones per region. If a single zone is unavailable, the other two will automatically take over. If an entire region becomes unavailable we can manually redirect traffic to one of the other regions. This is a common practice at Spotify; all systems backing an important client feature should be provisioned in all available locations. This is both for reliability and to decrease latency in serving clients.
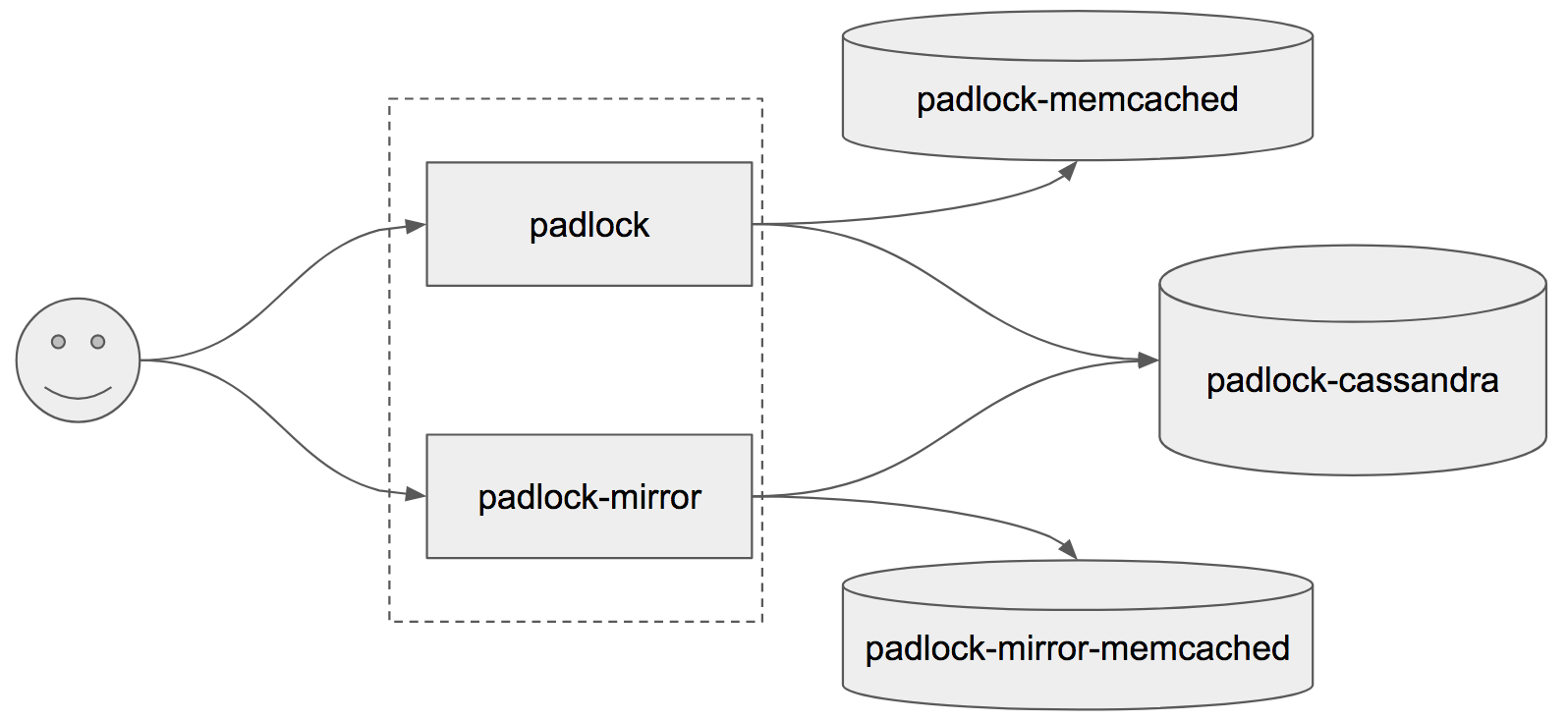
Additionally, we duplicate our setup within a region wherever we can. Padlock is deployed as two separate deployment groups – padlock and padlock-mirror. Both groups have separate puppet roles and separate caches, and both have enough capacity to take over production traffic from the other group. See the image below for a high-level overview of the request flow. This limits the blast radius of risky puppet changes, and even helped us during an incident where one memcached cluster returned corrupt data which broke our service hosts.
The two deployment groups still share a single Cassandra cluster. Keeping two databases in sync is difficult, so we trust Cassandra to be highly available rather than reinventing the wheel.
Designing failovers is a nice first step but no use without verifying they work. We periodically run disaster recovery tests (DiRTs), simulating service or storage failures. This is something Spotify runs on a large scale (simulating full data center outages and network splits) and something we do as a team. A few weeks after we ran a DiRT, we had an incident where several Cassandra hosts in one region had disk corruption. Having simulated similar Cassandra outages in a DiRT, we knew what to expect and how to quickly mitigate impact.
Final Thoughts
Hopefully this blog post gives you an overview of the rationale behind and design of Padlock, a core backend service at Spotify. We built Padlock as a tool for our developers that centralizes the control over lifecycles of personal data of individual users at Spotify.
The tradeoff for this centralization is that it introduces a central single point of failure. We try our best to mitigate this risk by building in redundancy on multiple layers, and choosing well-understood building blocks like Cassandra as our foundation.
In the future we will carefully look into the possibility of leveraging more features of Google’s cloud platform, such as autoscaling on Kubernetes and managed databases like Spanner. For now, we can look back on operating one of Spotify’s core services for almost a year, and easily matching all SLOs we aimed for at the beginning of the project.
SHARE THIS ARTICLE