Bigtable Autoscaler: saving money and time using managed storage

Background
At Spotify we are moving to managed infrastructure solutions to focus more on our core competencies. In the databases space that means moving to Google Cloud managed databases.
Bigtable is a database battle tested by Google internally since 2005 and available as a service since 2015. With regional replication now available, Bigtable is one of the most interesting database products in the market.
Why Bigtable Autoscaler?
There is only one setting in Bigtable that Google doesn’t manage for you: number of nodes. You need to setup monitoring and alerts to manually set the size of your Bigtable cluster to adjust to changes in CPU utilization and database size.
Of course this means users tend to set a high number of nodes, otherwise they would get alerts all the time and they would have to manually resize in order to follow daily, weekly and other seasonalities.
To secure reliable performance and minimize the operational load on Spotify teams, we developedBigtable Autoscaler: a service that performs automatic cluster rightsizing.
How does it work?
For each cluster the user configures the following:
Min and max size: number of nodes
Average CPU utilization target: recommended is 70%
Overload step: number of nodes to add when cluster is overloaded (> 90% CPU)
Autoscaler uses the Google Cloud Monitoring Java Client to gather Bigtable metrics for all Bigtable clusters that are registered in its database.
Every 30 seconds Autoscaler loops through the list of clusters and, for each one, it:
Gathers metrics: average CPU utilization, storage utilization and current number of nodes in the last hour (or since the last resize)
Applies different rules to decide if it should resize now or not and calculate the resize delta to scale up or down
These are the scaling rules, in priority order:
Keep cluster size between minimum and maximum values set by the user
Have enough nodes to support the amount of data: 2.5 TB per node (SSD) and below recommended 70% disk usage
Have enough nodes to keep CPU utilization below target set by the user
If CPU utilization is above 90% scale up by the “overload step” set by the user
But do not resize too often: resizing a cluster has a performance cost. It takes around 20 minutes to stabilize, so Autoscaler does not scale too often, especially when scaling down, Autoscaler is cautious and keeps extra capacity for a while. On the other hand, when scaling up, it is better to do it more quickly to avoid getting overloaded
Exponential backoff: when Autoscaler finds unexpected errors on a cluster, then it exponentially increases the time it waits before checking again (up to 4 hours). This is to avoid congestion: trying to resize too many times when there is an error. The error could be intermittent (we don’t know). These errors get logged in Autoscaler database and an alert can be configured
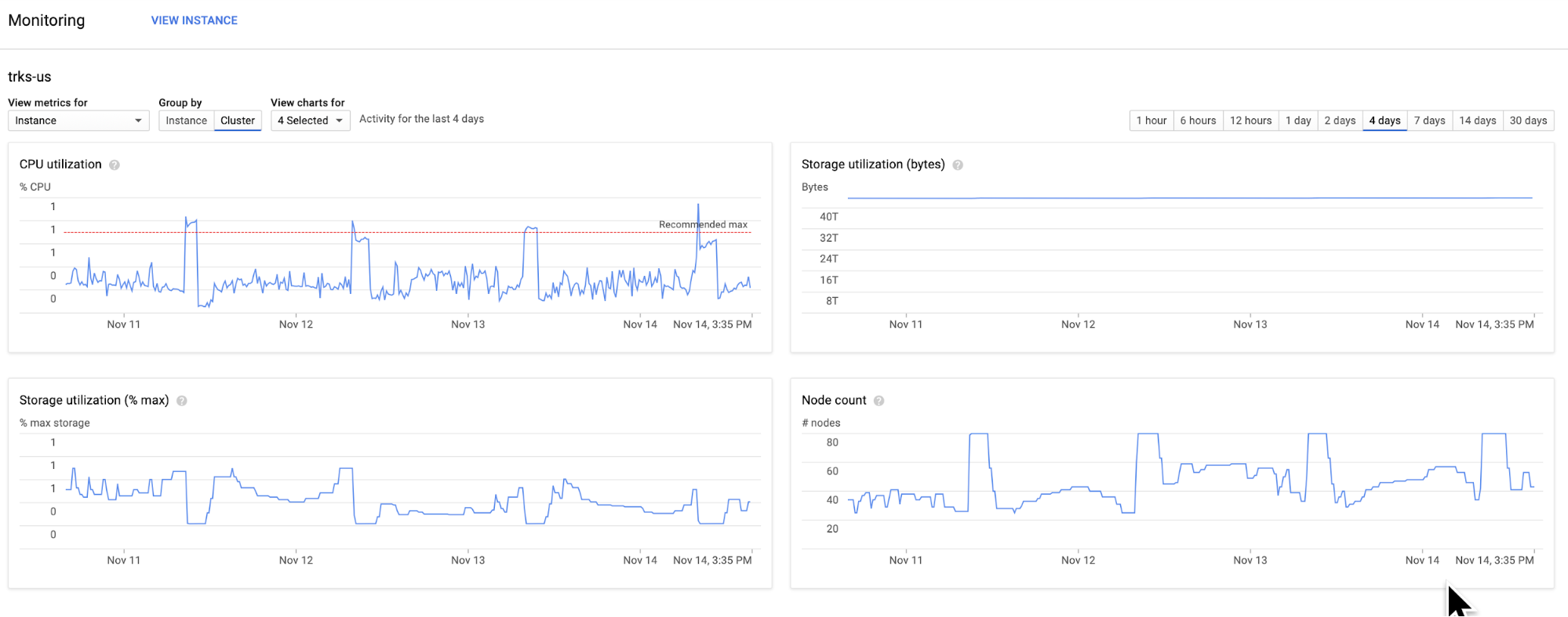
In this example we see Autoscaler adjusting a cluster size in a 4 days interval.
Without Autoscaler this cluster would probably use 80 nodes all the time, but here we see how the capacity is automatically adjusted to demand (~50 in average).
Support for batch jobs
One common use case we found is batch jobs causing sudden big spikes in load. Autoscaler by itself does not scale up fast enough in those cases, but we added a new endpoint where you can let Autoscaler know that a batch job is starting and how many extra nodes you estimate you need and also let Autoscaler know when the job is done.
Autoscaler will add extra nodes to its calculations based on what jobs are currently running.
This way you can integrate Autoscaler with any kind of data workflow or batch jobs that you use, for example we have integrated it with Google Cloud Dataflow jobs.
Quick Start
Autoscaler is a Java RESTful web service built with Jersey using a PostgreSQL or Cloud SQL database. To get started quickly you only need:
A Google Cloud service account that have admin permission in the cluster you want to autoscale. This basically means setting environment variable GOOGLE_APPLICATION_CREDENTIALS to the full path of your credential JSON file
Docker
Run the following commands:
source .env # edit this file with your info: GCP credentials & DB settings make build-image # build docker image make up # start service using docker compose with a dockerized postgresql make logs # see logs |
Then define env vars PROJECT_ID, INSTANCE_ID and CLUSTER_ID and run the following command:
curl -v -X POST “http://localhost:8080/clusters?projectId=$PROJECT\_ID \ &instanceId=$INSTANCE_ID&clusterId=$CLUSTER_ID&minNodes=4&maxNodes=6 \ &cpuTarget=0.8” |
This will save this cluster in the DB and immediately start to autoscale it: every 30 seconds it will check metrics such as CPU and disk usage and resize your cluster to the right number of nodes for your target CPU utilization.
The service is dockerized so it is easy to deploy for real production use and, of course, you need to point it to a real PostgreSQL or Cloud SQL database (it’s all environment variables).
Future Improvements
Right now Autoscaler is reactive, but we are doing some promising experiments with Facebook Prophet to make it predictive. With 6 weeks of metrics every minute it is enough to make good forecasts.
We can use this data to make predictions for the independent variables that define the load:
Number of reads and writes per second
Bytes sent and received
Using the same historical data we can do regression analysis to find the formula that gives us the right number of nodes for a given load and desired CPU utilization range.
For example Google says you can get 10,000 QPS @ 6 ms latency per node, assuming 1 KB rows and only read or writes. We are trying to find the general form of that “formula”, so we can then adjust coefficients based on data for a specific cluster.
Thanks for reading!
SHARE THIS ARTICLE



