Spotify’s Event Delivery – Life in the Cloud

Spotify is a data informed company and in such a company Event Delivery is a key component. Every event containing data about users, the actions they take, or operational logs from hundreds of systems is a valuable piece of information. Without a successful Event Delivery system, we would not be able to understand our users deeply and serve them the personally tailored content they love. It follows that we would not have been able to redefine the music industry and the way the world interacts with audio! What would your Monday morning be without Discover Weekly or the end of every year without Wrapped? Other examples include company key metrics, metrics for our A/B Testing Platform, or live statistics when an artist releases their next big hit (check Spotify for Artists).
In 2015, when Spotify decided to move its infrastructure to Google Cloud Platform (GCP), it became evident that we needed to redesign Event Delivery in the cloud. This post is the next installment of our blog series about Event Delivery at Spotify. The first three can be found at Spotify’s Event Delivery – The Road to the Cloud (Part I), (Part II) and (Part III). Since we wrote the original 3 blog posts, we have run Event Delivery in the Cloud for 2.5 years and we feel it is time for two more parts in the blog series. In this part (IV), we will discuss what we have achieved and what worked from our original plan, the next steps we’re taking, and how we have evolved and simplified by moving up the stack in the cloud. During those 2.5 years a lot of things have changed and we have new requirements. Right now we are working on the next generation of Event Delivery, which we will write about in part V of this blog series.
Current Event Delivery System
It took us almost a year to design, write, deploy and scale the current, Cloud Pub/Sub-based Event Delivery system fully into production. From the very beginning, this system was supposed to run only in the cloud (GCP) and we achieved that. In order to iterate quickly, we kept the producing and consuming interface compatible with the old system. This setup gave us the ability to run both systems in parallel in order to compare if all delivered data was complete. This was critical for us to pass strict auditing requirements, which was a pressing concern at that time. Since we ensured that the new Event Delivery system was ready for strict IT auditing requirements, it made sense to migrate the business-critical data to the new system first. Examples of business-critical data include EndSong Event (an event emitted when a Spotify user finished listening to a track), which is used to pay royalties to labels and artists, calculate Daily Active Users (DAU), Monthly Active Users (MAU); and the UserCreate Event (an event indicating a new Spotify user account was created). This was bold and counter-intuitive, but by migrating the big fish first, we managed to achieve stability and critical mass in the new system much quicker, and drastically sped up the total time of the migration. We planned a pragmatic and staged rollout, however it did not go as planned. We rolled out the new system to 100% of the traffic in just one day, and it surprisingly worked fine. In February 2017, we killed the existing Kafka-based system, and the new system has been running successfully, delivering billions of events every day since then.
Spotify’s user base has had staggering growth since we rolled the GCP-based event delivery system into production. Between 2016 and 2018 we more than doubled our MAU, having now 232M MAU (as of August 05, 2019). Once the system was fully in production, we reached 1.5M events/sec (e/s), that was just 0.5M e/s short of what we had tested as maximum during the design phase (read more in Part II). At the end of Q1 2019, we were producing globally more than 8M e/s at peak. There are more than 500distinct Event Types, summing up to over 350 TB of events (raw data) flowing through our system daily, coming from our clients and internal systems.
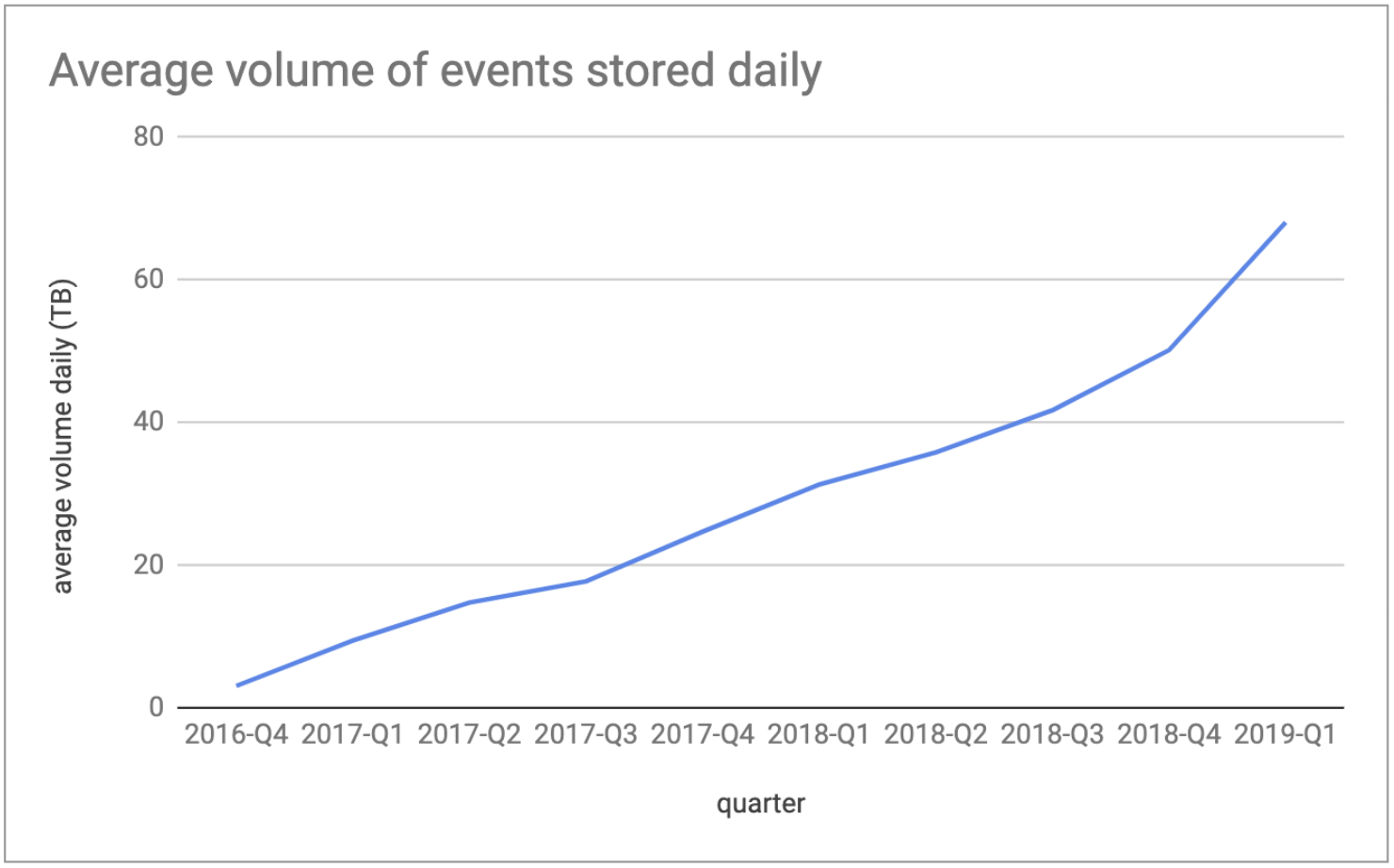
Figure 1. Average total volume (TB) of events stored daily by our ETL process (after compression).
Principles, strategies, and great decisions
These are impressive numbers, so what are the principles that let us build such a scalable infrastructure? Let’s share a few.
Isolation per Event Type
The Event Type is defined by a producer, it has a name, a schema and metadata. From the operational difficulties with our Kafka-based system, we learned that not all events are equal and that we can leverage this in our favor. Event Types are prioritized and may differ based on some of the properties listed below:
Business Impact Event Types – some are used to pay royalties to labels and artists, and some are used to calculate company key metrics. These Event Types are subject to external SLAs both for timely delivery, and quality
Volume Event Types – are emitted a few hundred times an hour, and some are emitted 1M+ times a second.
Size Event Types – size varies between a few bytes and tens of kilobytes.

Figure 2. Event Delivery infrastructure, isolation per Event Type starts in Cloud Pub/Sub.
In order to prevent high volume or noisy events disrupting the business-critical data, we chose to isolate event streams as soon as possible. Event Types are separated right after the Event Service which is the entry point to our infrastructure. It is responsible for parsing and recognizing Event Types and publishing them to Cloud Pub/Sub (Pub/Sub). Malformed or unrecognized events are rejected. In the end, every Event Type has its own Pub/Sub topic, Extract, Transform, Load (ETL) process, and final storage location. This setup gives us the flexibility to deliver every Event Type individually. For operational purposes, Event Types are distinguished by importance: high, medium, and low, and we have separate priorities and Service Level Objectives (SLOs) for each importance level. This allows us to prioritize work and resources during incidents in order to deliver the most critical events first. We also stagger alerting to avoid waking up in the middle of the night when a less important Event Type is struggling. Our strictest SLOs follow:
High priority – a few hours SLO
Normal priority – 24h SLO, chosen for events needed to be present the next day
Low priority – 72h SLO, mostly used internally, for events needed the next working day
You can read more about how we maintain our Event Delivery Pipeline from an operational perspective, in the chapter we co-authored, in The Site Reliability Workbook (available online, Chapter 13 – Data Processing Pipelines, Case Study: Spotify).
Liveness over Lateness
Delivered events are partitioned hourly; this means that each Event Type has an immutable hourly bucket where events are stored (see Figure 3., hourly buckets are represented by squares and each of the colors represent a given Event Type,e.g. dark red square with T14 label means an immutable bucket containing all events (of red dark Event Type) that arrived into our system between 13:00 and 14:00 UTC. **Thanks to the previously mentioned separation per Event Type, we chose to prioritize liveness over lateness.**In other words, a noisy, broken, or blocked Event Type will not halt the rest of the system.
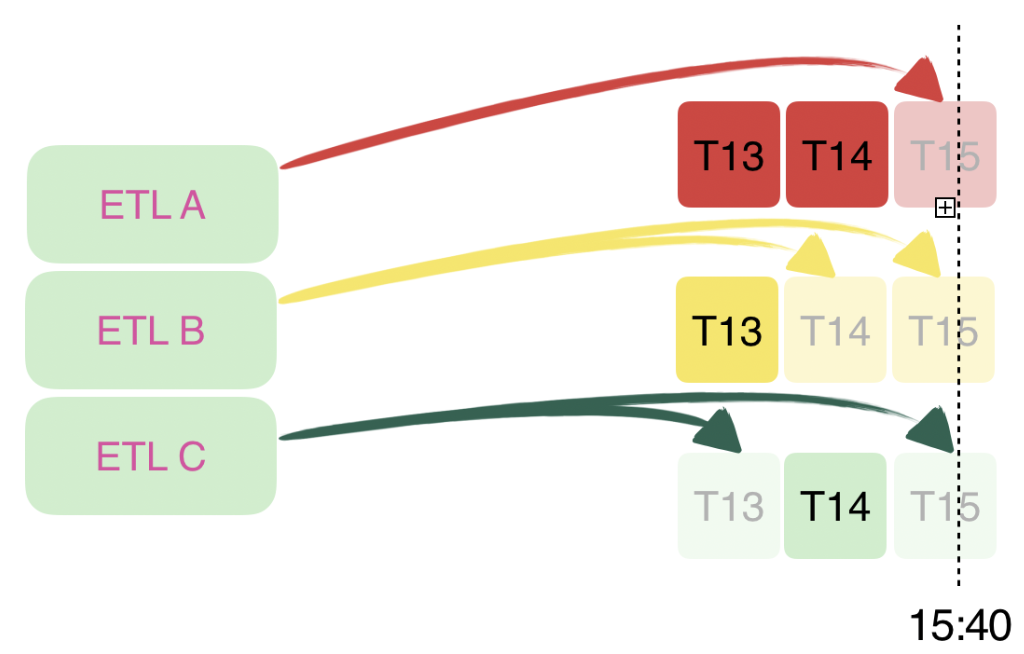
Figure 3. Liveness over lateness. Some Event Types have their partitions not delivered yet (the faded ones,the dark ones are already delivered and closed). However open partitions do not block other Event Types’ partitions to be delivered and ready for consumption.
Figure 3. Liveness over lateness. Some Event Types have their partitions not delivered yet (the faded ones,the dark ones are already delivered and closed). However open partitions do not block other Event Types’ partitions to be delivered and ready for consumption.
You can read more about this concept in Reliable export of Cloud Pub/Sub streams to Cloud Storage, a blog post explaining all technicalities of our ETL.
Separation of concerns and autoscaling
Our system consists of close to 15 different microservices that are deployed on around 2500 VMs. This enables us to work on each of them individually, and replace any if needed. Every component is monitored separately, which makes it easy to debug and find bottlenecks. There is, of course, risk associated with introducing changes to such a large system with business-critical implications. To enable us to iterate with confidence, we have end-to-end integration tests, a staging environment, and canary machines. Some of those services are autoscaled, this is why the previously mentioned number of VMs varies. The biggest challenge with autoscaled infrastructure, with hundreds of machines, is that its state changes all the time. This became one of our pain points. With the scale we have reached now, autoscaling with Spotify’s deployment tooling caused deployments of the whole fleet to take up to three hours! This means that while the system is designed for safe and rapid iteration, now we unfortunately have long iteration cycles due to limitations in the deployment tooling. You can read more about our configuration in Autoscaling Pub/Sub Consumers.
Managed services
As part of Spotify’s move to the cloud, the strategy has been to outsource time consuming problems that are not core to our business to Google and GCP. Particularly, we take advantage of managed messaging queues, data processing, and storage. The backbone of our system is Cloud Pub/Sub. Cloud Storage (GCS) is the main storage for both the final datasets and intermediate data. The ETL is built on Compute Engine (GCE) instances (a cluster per Event Type, using Regional Managed Instance Groups), CloudSQL for metadata, and Dataproc for deduplication. We use Dataflow jobs for encryption of sensitive data in events. We use BigQuery for data warehousing, and this tool has become a favourite for data engineers, data scientists, analysts, product managers, and most who wish to interact with event data.
**Our path to stability with all these managed services has been successful, but has not been without bumps. We have fostered strong collaboration with Google, and learned a lot about building infrastructure in the cloud.**Here are some things to consider when using managed services:
The fleet of Google support engineers is available around the clock, and this is extremely valuable.
Engineers can quickly turn their ideas into infrastructure projects with a few clicks. Building concepts early reduces the amount of time previously required to try something new, and the risk associated with failing is drastically reduced.
The value in using alpha or beta products. Cloud providers need early adopters on new offerings, and by providing feedback early you get traction on feature requests your organization might benefit from, or can even shape the future of a product offering.
Sometimes things will not work out of the box. Solutions built by the major cloud providers are generic, in order to serve a wide variety of different needs. It is very possible that what you are doing is special in some way. In our case, it was often our scale. We succeeded by building our own extensions and libraries for many of the managed services. Overtime these extensions became obsolete, but our willingness to accept limitations and create extensions was a major part in delivering the project. If you hit a limitation and build an extension for your use case, chances are it will be valuable throughout the community, which is a great opportunity for open source contributions (see our GitHub profile).
Test new ideas, fail fast, and recover even faster
During the migration to cloud services we needed to create custom solutions since the available options were not the best fit. I will provide three examples of our trial and error experience while trying to tailor the cloud services to our needs.
Dataflow is a great data processing framework that can partition data in real-time based on the type and processing time. This sounded like a perfect choice for our ETL process – this idea failed. When we tried to productionize our proof of concept we ran into problems. We wrote about the details of this initial plan and failure in Reliable export of Cloud Pub/Sub streams to Cloud Storage.
Another example is our experience with trying out Pub/Sub. When we started as early adopters of this service, our plan was to use official Java client libraries – this failed too. They were either not ready, or did not work for our use cases and scale. However, we were still sold on Pub/Sub and decided to write our own libraries for publishing and consuming instead. We successfully used those libraries in production for more than a year before switching to Google’s libraries.
The last example worth mentioning involves the difficulties we faced using hundreds of autoscaled managed instance groups with a wide range of traffic, being deployed to nearly ~2500 GCE instances. Since this was before Kubernetes Engine (GKE), there was a lot of manual labor needed to set up a VM before it can run an application. These include DNS registration, Puppet installing dependencies such as Docker, Helios (our internal container orchestrator), monitoring daemon, and the remaining steps needed to set up a VM. If any of these steps fail, a VM will become unresponsive. The default healthchecker from GCE also failed for our setup, it detects an unhealthy machine, but replaces it with a new machine with the same name. This causes a problem in our Puppet infrastructure because we use the machine name as an ID. The puppet-CA rejects the new machine because the name is already registered, and the code wasn’t getting deployed. To resolve this, we wrote our own healthchecker, and are successfully using this approach today (you can read more details here).
Building and maintaining custom solutions can be hard, and software gets outdated very quickly. This is not the case when using recommended clients or libraries since the cloud provider is usually obliged to deliver updates as long as the product is available. Additionally, custom solutions degrade the value provided by customer support specialists, as they have difficulty determining if the issue lies within the cloud vendor’s infrastructure, or within your library.
Event Delivery as a Service
We have over 500 different Event Types owned by hundreds of teams, and these teams are most likely the producers of a given Event Type. However, some Event Types are generic and shared across many teams, for example the PageView. Owners have full control over their Event Types, but most importantly, their desired changes require no involvement from us. They can define and start emitting a new Event Type at anytime. Owners can apply different types of storage (GCS or BQ) and partitioning strategies (hourly or daily) to their Event Type definitions. We allow owners to evolve schemas of the Event Type (we use Apache Avro), in a backwards compatible way. With this restriction, consumers can read up to 10 years of historical, and evolve data with the same code without backfilling datasets.
All of this automated infrastructure is managed by a centralized composer for the cloud resources needed. For each Event Type it creates a separate Pub/Sub topic and subscription, ETL cluster (and schedules the ETL job), distributes its schema, registers it with the proper SLO, and configures monitoring on all the different microservices and pipelines. This composer is also responsible for all the cleanup after the Event Type is officially deprecated. This centralized service is a runtime component, but we have ambitions for the next iteration to be a declarative and static resource, like a config file.
Privacy by design
Protecting user data and privacy has always been very important to us. For much of 2017, we focused on adapting our system to the new GDPR privacy regulations,. The Event Delivery system captures and stores information about our users, often considered to be personal data. The schema fields for every Event Type is annotated with semantic data types, which determine the presence of personal data. Based on these annotations, the ETL process encrypts the data we store and expose to consumers. Annotations also allow us to apply different access tiers and retention policies for all the Event Type datasets. In the blog post Scalable User Privacy, you can learn more about how we make sure our users’ data is stored safely. By enabling encryption based on schema annotations, our internal users (developers, data scientists, etc.) can handle sensitive data without our team’s intervention.
Lessons learned
Growth and scale
When designing a system for scale, a good approach is to come up with a capacity model for the system. It will help you calculate quotas needed for each resource, and operate smoothly as scale increases. Interestingly, we observed that data grows an order of magnitude faster than service traffic. Growth is a multidimensional function on the dimensions of DAU and organization growth. Whereas DAU is quite obvious, organizational growth is not. There will be an increasing number of engineers and teams introducing new features and instrumenting them. Capturing more data means a need for more data engineers and scientists looking into that data to gain more insights. More insights means more features, and the growth compounds. Our growth was quite rapid, in April 2017, we were capturing 100 billion events a day, in Q1 2019 we had 500 billion events a day without any issues. Additionally, small changes can sometimes cause unexpected exponential growth on your system. Ask us some time about an A/B test on the Spotify homepage that sent the curve skyward! Monitoring for unexpected traffic increases helped prevent creating incidents and exceeding our GCP quota.
Big systems cost big money
We began to develop this system with the goal of reducing friction so that we could collect as much data as possible. Two years, and a doubling of the R&Dorg later, we collect more data than we can use. Spending money is fine, but wasting it is not. Systems with millions of users and thousands of VMs will cost a lot of money, no matter if it is running in your own data center, or if it is outsourced to a cloud provider. Initially, it was a conscious decision to abstract data production cost from the data community with the intention of not hindering learning and innovation. The flip-side is it becomes way too easy to waste, sometimes huge amounts of money. Currently, we are working on striking a balance between unconstrained innovation and cost consciousness. Intermittent and short cost saving sprints have been a great mechanism to cut waste, while allowing unconstrained spending on new projects.
What’s Next?
The current system was designed in a world with a drastically different technological landscape than we see today. We designed this system before we had ever heard of GDPR, so we needed to spend a lot of time on making it compliant. Now GDPR is a prime requirement whenever designing a system that handles data. Additionally, Google’s cloud offering has become much more mature. Many products have evolved to our liking thanks to our alpha or beta usage, and feedback. Spotify’s internal infrastructure has also evolved drastically, and we no longer have the same restrictions we had when we designed this system. At our scale, we learned that completely abstracting cost away from engineers and data scientists can create waste. Lastly, there are some strategic improvements we can make that will have a clear and large business impact – which we will discuss in a future blog post. We have just begun rolling out this next generation infrastructure into production. Stay tuned for the next installment of Spotify’s Event Deliveryseries in the next few months!
SHARE THIS ARTICLE



