Test Flakiness – Methods for identifying and dealing with flaky tests

On September 12, 2019 I spoke at Assert(JS) in Toronto to talk about my journey with test flakiness at Spotify and some of the systems we have built over the years to address flakiness.
Assert(JS) is a conference dedicated entirely to automated testing for web systems and this was the second year it has been run. This conference has hosted speakers that are well known in the automated testing world such as Kent Dodds, Justin Searls, Aaron Abramov, James Shore, Isaac Schlueter, and now yours truly.

What is test flakiness?
A flaky test is a test that both passes and fails periodically without any code changes. Flaky tests are definitely annoying but they can also be quite costly since they often require engineers to retrigger entire builds on CI and often waste a lot of time waiting for new builds to complete successfully.
But the real cost of test flakiness is a lack of confidence in your tests. The picture you see above tells this story! If you don’t have confidence in your tests then you are in no better position than a team that has zero tests. Flaky tests will significantly impact your ability to confidently continuously deliver.
Causes of flakiness
There are many causes of flakiness but the few I highlight in my talk are:
Inconsistent assertion timing – when your application state is not consistent between test runs you will notice that expect/assert statements fail randomly. The fix for this is to construct tests so that you wait for the application to be in a consistent state before asserting. I am not talking about “wait” statements either. You should have predicates in place to poll the application state until it reaches a known good state where you can assert.
Reliance on test order – global state is the main culprit that causes tests to be reliant on other tests. If you see that you cannot run a test in isolation and it only passes when the whole suite is run then you have this problem. The solution is to entirely reset the state between each test run and reduce the need for global state.
End to end tests – end to end tests are flaky by nature. Write fewer of them. Instead of having 500 end to end tests for your organization, have 5.
Tracking flakiness at Spotify
Over the years we have built a few systems at Spotify which have helped us to significantly reduce test flakiness across the engineering organization. I’ll share some of the tools I discussed below:
Odeneye
Odeneye is a system at Spotify that visualizes your test suites and can help you identify both test flakiness and infrastructure problems. Looking at the image below, vertically you see individual tests and horizontally you see the result of these tests running in CI. If you see a scattering of orange dots this usually means test flakiness. If you see a solid column of failures this usually represents infrastructure problems such as network failures and things of that nature. Views like this are a great way to help you establish what is flaky and what is an infrastructure problem.

A simple table
We have another tool at Spotify that is part of a large suite of developer tooling. Looking at the image below of a simple table, the results are surprising. This view allows teams to see their tests, see which ones are fast & slow, and see which ones are flaky. Simple right?
By making this table available and doing nothing else this reduced test flakiness at Spotify from 6% to 4% in two months. If you have a flakiness problem in your organization simple tools like this can make a dramatic difference.

Flakybot
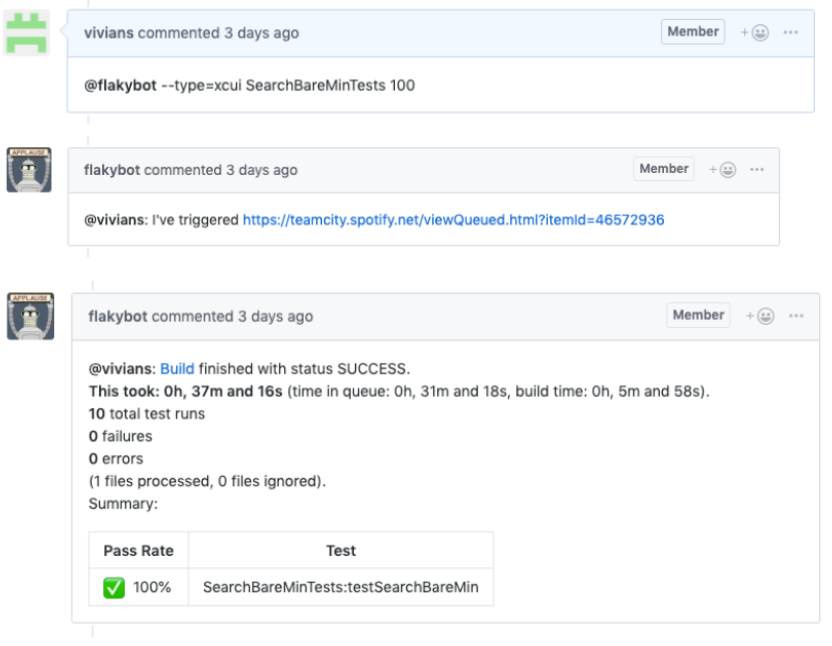
So we have the tools to tell you which tests are flaky, but how will an engineer know they have fixed the flakiness problem? This is why we created Flakybot. This is an internal tool at Spotify to help engineers determine if their test(s) are flaky before merging code to master.
An engineer can invoke Flakybot at any time in a pull request, and their tests will be exercised quickly and show a report. This gives a high level of confidence that flakiness problems have been fixed.
Conclusion
Flakiness is a common problem across every engineering organization but is often ignored and treated as a simple nuisance. My talk explains how flakiness can manifest into much larger problems and how you can take steps right now to reduce or even eliminate it.
This was my first public speaking engagement outside of Spotify and it was an amazing experience that I hope to do again. Check out the .pdf of my slide presentation from the talk.
SHARE THIS ARTICLE