The Winding Road to Better Machine Learning Infrastructure Through Tensorflow Extended and Kubeflow

When Spotify launched in 2008 in Sweden, and in 2011 in the United States, people were amazed that they could access almost the world’s entire music catalog instantaneously. The experience felt like magic and as a result, music aficionados dug in and organized that content into millions of unique playlists. Early on, our users relied on playlists and rudimentary recommendation features like a related artists feature to surface new music. Over time Spotify got more advanced in our recommendations and user-favorite features like Discover Weekly started to significantly improve new music discovery and the overall Spotify experience (more on that journey in this talk). More users and more features led to more systems that relied on Machine Learning to scale inferences across a growing user base.
As we built these new Machine Learning systems, we started to hit a point where our engineers spent more of their time maintaining data and backend systems in support of the ML-specific code than iterating on the model itself. We realized we needed to standardize best practices and build tooling to bridge the gaps between data, backend, and ML: we needed a Machine Learning platform.
This blog post will outline our “winding” journey that established the building blocks for our platformized Machine Learning experience and specifically how Spotify leverages TensorFlow Extended (TFX) and Kubeflow in our Paved Road for ML systems.
The First Iteration: Meet Our ML Practitioners Where They Are
Spotify has had major ML systems in production (like Discover Weekly and our Search Infrastructure) long before we ever had a team dedicated to building tools for ML teams. Because of that, we didn’t want to flip any tables by telling the existing systems they would have to rewrite their jobs because a new tooling sheriff was in town. We decided to meet our teams where they were by building connectors amongst the most popular ML frameworks in active use instead of dictating to teams which framework to use.
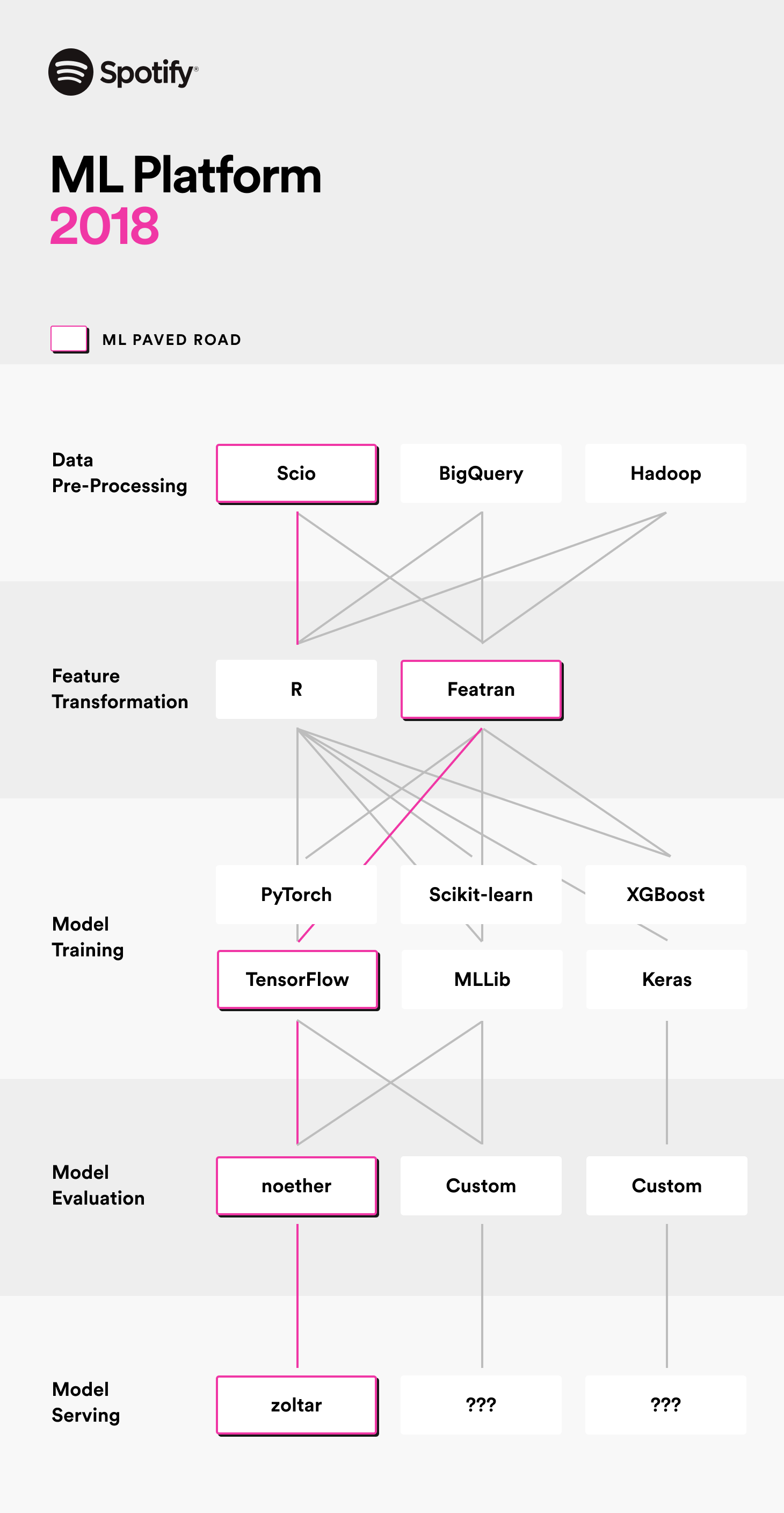
At the time, our data tooling used the Scala language heavily – especially Scio (previous blog post), our open-source Data Processing library built on top of Apache Beam. To support the transition from data engineering to Machine Learning, we built libraries like Featran for feature engineering, Noether for model evaluation and a library called Zoltar to connect the trained models with our JVM-based library Apollo which is used almost exclusively in Spotify’s production services.
While this was a welcome change to engineers familiar with our Scala ecosystem, we realized early on that this path wasn’t aligned with the larger ML community and the toolsets they used, which were largely Python-based. Some of the best feedback we received was blunt: some ML engineers would never consider adding Scala to their Python-based workflow. If we went down that path, those ML practitioners would either have to do complex things to build end-to-end ML systems or have no path at all!
We realized we needed to rethink our approach – to either double-down on the direction we were heading or to embrace an alternative path.
The Second Iteration: Standardize on Tensorflow Extended (TFX)
One important thing we did during the first iteration was to build something we named the “Paved Road for Machine Learning at Spotify”. The concept is simple: an opinionated set of products and configurations to deploy an end-to-end machine learning solution using our recommended infrastructure, targeted at teams starting out on their ML journeys. As we evolved our infrastructure decisions and products, the Paved Road would evolve and always reflect the latest state.
As more people deployed our Scala-heavy Paved Road, some common problems crept in:
It was confusing to switch back and forth between Python and Scala
Scala was difficult to use by Data Scientists that had been using Python for the majority of their careers
It was difficult to ensure feature versions, configurations, and models were linked-up correctly as a unit

At the time, we were aware of Google’s TFX paper and were impressed by the solutions and their impact. While most of the TFX tooling wasn’t yet available outside of Google, some important foundational pieces were, such as TFRecord and tf.Example. In short, these provide a data storage and message format that is targeted for ML workloads. In an attempt to slowly shift Spotify ML engineers towards a smaller set of “roads” for ML, we thought a good first step was to standardize the storage format between steps in the ML workflow – essentially, to agree on the interface between the steps so that we could build connectors/bridges to common tooling used by the different Spotify workloads.
We quickly built connectors from our ML workflow tools and internal libraries that supported linking these data and message formats to common training libraries like XGBoost, Tensorflow, and scikit-learn.
An early advantage of using TFRecord/tf.Example was the easy support of Tensorflow Data Validation (TFDV) – one of the first components open-sourced by Google from their TFX paper. TFDV allowed our ML engineers to understand their data better during model development, and easily detect common problems like skew, erroneous values, or too many nulls in production pipelines and services.
Soon thereafter, the TFX team released much more of their internal tooling – including components like Tensorflow Transform, Tensorflow Model Analysis, and Tensorflow Serving. An evaluation of these components determined that they were both comparable in performance to our Scala-based tooling and offered compelling features that we hadn’t yet built. It wasn’t a full set of tools at the time, but it was promising and we suspected there was more to come – a conversation with some members of the TFX team confirmed this. We decided to steer Spotify ML and our Paved Road towards standardizing on TFX tooling.
With the TFX tooling, we had an end-to-end Paved Road for Machine Learning! However, it still had a lot of gaps:
Nothing tied together the disparate tooling and provided the end-to-end experience
Keeping track of independent machine learning experiments was still very manual and teams had trouble comparing results from different approaches
Our orchestration framework, Luigi, was built for data pipelines and had trouble dealing with the unique constraints of machine learning workflows.
We started talking to Google Cloud about these gaps in early 2018. They were intrigued and just starting to build a product that might serve some of those needs. That product became Kubeflow Pipelines.
The Third Iteration: Introducing Kubeflow Pipelines
More recently, we started to switch teams over to Kubeflow Pipelines (KFP), an open-source platform for defining, deploying, and managing end-to-end ML workflows. It turns components of an ML workflow into Docker containers to enable portability and reproducibility while handling resource management and workload orchestration via Kubernetes.
As the Kubeflow ecosystem gained maturity in the last year, we adopted it as the foundation of our ML platform offering as it solved a lot of our problems.
First of all, our existing efforts to standardize on TFX are supported within Kubeflow Pipelines. As explained above, our users were already familiar with TFX and its components, thus did not need to learn yet-another-way of doing core ML tasks.
Second, the KFP SDK allows for the creation and sharing of components: self-contained sets of code that perform one step in a pipeline (e.g. data preprocessing, data transformation, model training). Teams that need custom components now build them against a common interface. It makes it much easier for teams to share components, and reduces the amount of “reinvented wheels”.
Thanks to its SDK, users can compose parameterizable pipelines leading to faster model iteration. But most importantly, all these iterations are automatically tracked for the ML practitioner via a metadata store and exposed in a rich Web UI to explore, compare, and examine pipelines’ runs in detail.
To support the use of Kubeflow and KFP at Spotify, we deployed managed Kubeflow clusters and built a Python software development kit (SDK) and command-line interface (CLI).
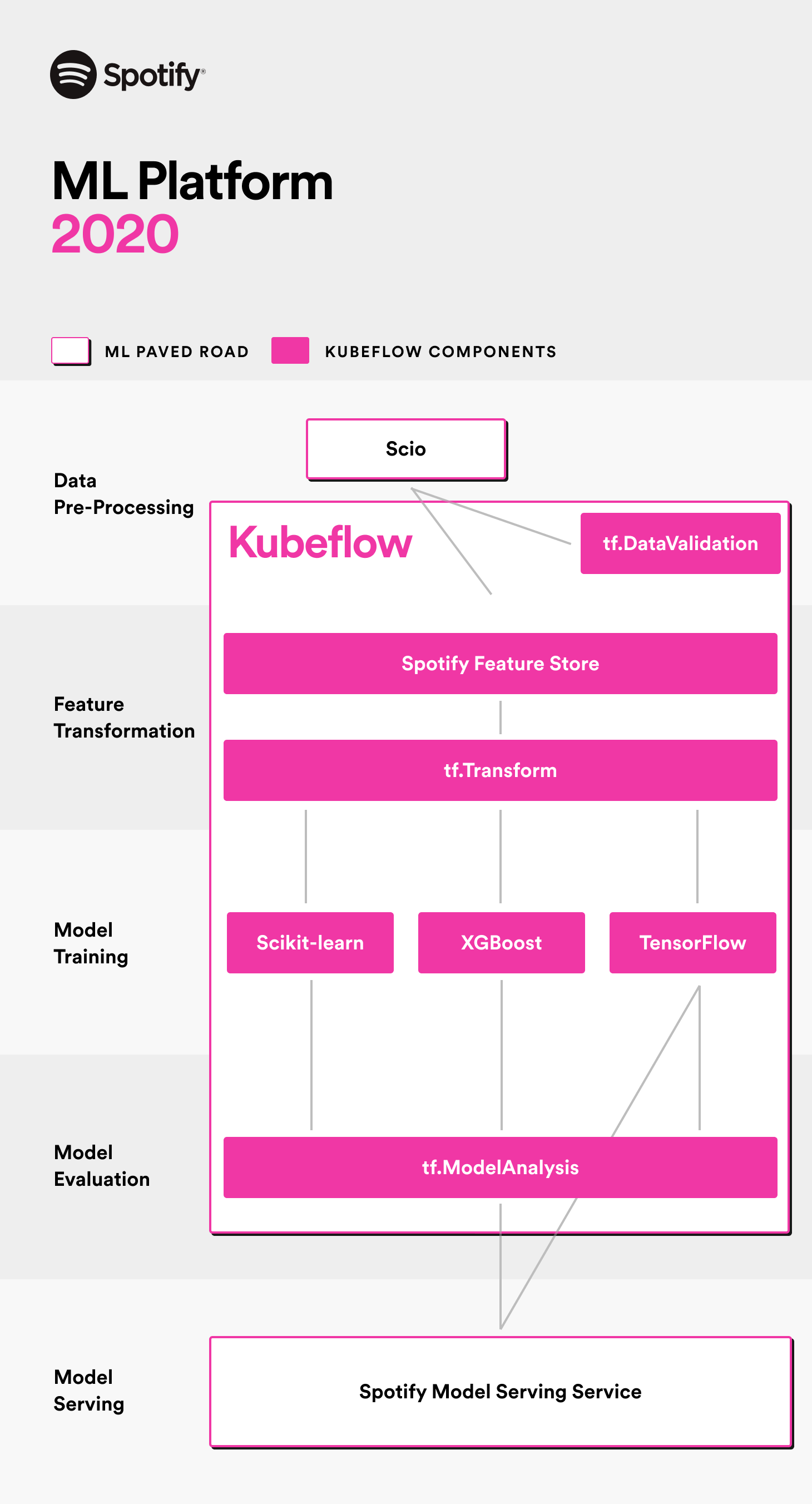
Despite cross-functionality and autonomy of teams being the core of Spotify engineering culture, expecting our customers to run their own Kubeflow clusters defeats the purpose of abstracting the resource needs and planning. We deployed and operate centralized Kubeflow clusters so that ML engineers at Spotify don’t have to worry about the details of managing the resources under the hood and can focus on ML-specific tasks.
Here are some features of our clusters that we added on top of Kubeflow’s stock deployment:
GCP’s Cloud SQL managed database service to store pipeline metadata instead of running KFP’s default MySQL database in the cluster
Shared VPC (Virtual Private Cloud) integration, allowing multiple GCP projects to communicate with each other via a common VPC network
Pre-defined node pools, suited for standard ML tasks, memory-intensive jobs, or GPU training.
For more details on our journey building and managing our clusters, check out the presentation we gave at KubeCon North America 2019: Building and Managing a Centralized Kubeflow Platform at Spotify.
In response to interest expressed at KubeCon, we’ve open-sourced the Terraform module for setting up our GKE clusters at https://github.com/spotify/terraform-gke-kubeflow-cluster.
While the Kubeflow Pipelines SDK provided a lot, the TFX 0.13 release did not integrate perfectly with it. Some of our biggest issues at the time were that:
KFP and TFX components couldn’t be mix-and-matched in the same pipeline
HTML-artifacts from TFX components, such as the ones generated by TensorFlow Model Analysis, couldn’t render in the KFP Web UI
KFP’s orchestrator for TFX didn’t support caching, meaning a pipeline would need to re-run entirely even if only the last component failed for example
A TFX component couldn’t be extended easily, meaning users were not able to add custom run-time dependencies to components such as Trainer or Transformer
Additionally, we developed an internal Python library, heavily based on both TFX and KFP’s SDKs, to help bridge the gap between them. It features the following:
Both SDKs are unified, closely following TFX-style components and their rich metadata system while allowing for additional flexibility offered by KFP
Caching support was added by re-working the KFP orchestration to talk to ML Metadata (MLMD) to benefit from TFX’s built-in caching
TFX visualizations like dataset statistics and model evaluation metrics can be displayed in the KFP UI
Integrations with existing data infrastructure that manages data discovery, publishing, and access control
Adding custom components and external Python dependencies are made simpler
A collection of common components to cover most of our customers’ use cases, effectively reducing boilerplate code and abstracting details away from the user (e.g. XGBoost training, data sampling with Apache Beam).
It is worth mentioning that Google and the open-source community are looking to fix the aforementioned issues.
To easily compile and run KFP workflows on our managed clusters, we have extended our library to act as a CLI. It allowed us to reduce boilerplate around configuration and authorization, and have control over our metadata for future exposure in our existing centralized developer platform. The CLI also abstracts the building of the Docker images of the components during the pipeline compilation step via skaffold. As a result, our customers rarely have to build their own Docker containers, once again focusing less on infrastructure and more on their core use case.
By having this controlled layer between the user and Kubeflow, we can easily manage upgrades of Kubeflow and TFX.
We launched the alpha version of our platform in August and so far we have already seen about 100 users totaling 18,000 runs. Machine learning engineers can now focus on designing and analyzing their ML experiments instead of building and maintaining their own infrastructure, resulting in faster time from prototyping to production. In fact, early analysis indicates some teams are producing7x more experiments already!

Note: The spike in the middle is due to a rogue scheduled job which ran every 5 minutes for a few weeks. The good news was that it ran successfully the entire time!
Lessons Learned
Building infrastructure with our users moves us faster
At Spotify, we have the advantage of being able to work closely with users of our infrastructure. In this case, users are the engineers building machine learning features in the product. This gives the infrastructure teams a clear direction on priorities and provides fast feedback during evaluation. It also comes in handy when our engineers need specific domain knowledge to help make decisions. We’ve been incredibly lucky to have enthusiasm and trust from our internal machine learning teams and all products are better as a result.
Infrastructure evolution takes a toll on your users
This post details three distinct iterations we made in our journey to standardize machine learning. While we believe every iteration was valuable and improved development speed, it’s also true that each change in our “blessed” toolset was a tax on our adopters. We’ve been extremely grateful to our users for paying that tax and continuing to give us useful feedback and it’s safe to say we’re both hoping our current iteration will last for a few solid years.
Standing on the shoulders of giants
We put in a lot of work evaluating the many possible directions we could go with our infrastructure and bridging the gaps between our choices and the internal infrastructure, but the majority of code in our stack is a result of open-source contributions or investments by Google Cloud. Many insights and ideas that informed our infrastructure are results of knowledge exchanges with companies working on similar problems. We’ve been able to “see further” via the generosity of others and look forward to contributing to the ecosystem so that others can stand on our shoulders too!
What’s Next?
For the next blog post, our VP of ML Engineering Tony Jebara will discuss how Spotify’s Home page leverages this stack to personalize your experience. Over the next year, we’ll be excited to tell you more about our infrastructure, which includes: our end-to-end ML platform and interface, our approach towards feature sharing, how we’re solving model serving, and infrastructure for processing audio at scale.
One thing we’ve picked up in our discussion with other companies is that while we’ve made some positive strides in building solid infra for machine learning, we still have a ways to go. And we don’t think that is particularly unique:
If there's one takeaway I have from this event it's that we're all dealing with similar problems with different variations due to the constraints of our organizations, and we're working hard to put our best offerings forward, and nobody has got it all figured out. Nobody.
— Ryan Clough, A Professional (@fnord2vec) November 20, 2019
Stay tuned to this space for more about how we solve it for our organization! And we’d love to talk to you (or hire you) if you have good approaches in the space!
Acknowledgments
Everything above was the result of years of collaborative work across many different teams at Spotify. Our proudest achievement is how different areas came together to solve the problems for the whole. We’d especially like to shoutout a team called Hyperkube for building out the third iteration and for many people that put us on the right path: Andrew Martin, Bindia Kalra, Damien Tardieu, Edward Newett, Ed Morgan, Eric Simon, Gandalf Hernandez, Molly Holder, Joseph Cauteruccio, Keshi Dai, Marc Romeijn, Marc Tollin, Maya Hristakeva, Mark Koh, Martin Laurent, Matt Brown, Rafal Wojdyla, Romain Yon and Ryan Clough!
Samuel Ngahane is a Staff Engineer and Josh Baer is the Product Lead on Spotify’s Machine Learning Platform Group.
SHARE THIS ARTICLE