Introducing the Spotify Podcast Dataset and TREC Challenge 2020

Podcasts are exploding in popularity. Since 2015, we’ve added hundreds of thousands of shows, and users are listening more and more. With the additions of acquisitions including Gimlet and Parcast, we have a whole host of expertly created content, and with the addition of DIY podcasting platform Anchor, now everyone has access to tools to create their own podcast and publish it to Spotify, so the landscape grows ever richer and more diverse.
As this medium grows, it becomes increasingly important to understand the content of podcasts (e.g. what exactly is being covered, by whom, and how?), and how we can use this to connect users to shows that align with their interests. Given the explosion of new material, how do listeners find the needle in the haystack, and connect to those shows or episodes that speak to them? Furthermore, once they are presented with potential podcasts to listen to, how can they decide if this is what they want?
At Spotify we’re already conducting lots of interesting research on podcasts to delve into these kinds of questions (e.g., how can we identify podcasts that interview Barack Obama, as opposed to those that talk about him? What are the most important parts of a 45-minute episode? How do we know when a podcast is “high quality” or “informative” or “interesting”, and how do we define/quantify these concepts?). In particular, we’re interested in enhancing the discoverability of podcasts and how we characterize their content, so that people can quickly discover exactly the podcasts that will delight them.
To move the needle forward more rapidly toward this goal, we are engaging with the broader research community to dig into ways of understanding podcast content. To this end, we introduce the Spotify Podcast Dataset and TREC Challenge. Like the Spotify Million Playlist Dataset and Playlist Skip prediction challenge before it, this challenge will enable Spotify to tap into the larger audio research community and provide valuable data to push the boundaries of podcasting discovery.
This dataset represents the first large-scale set of podcasts, with transcripts, released to the public. The accompanying challenge will be a shared task as part of the TREC 2020 Conference, run by the US National Institute of Standards and Technology. The challenge will run throughout the year, with data released this Spring, participants experimenting over the Summer, wrapping up experiments in September, and reporting results in November. The challenge is planned to run for several years, with progressively more demanding tasks: this first year, the challenge involves a search-related task and a task to automatically generate summaries, both based on transcripts of the audio.
This dataset contains 100,000 episodes from thousands of different shows on Spotify. For each episode, we include the raw audio file, the RSS header containing its metadata (such as title, description, publisher), and automatically-generated transcript. For this version of the dataset, we’re restricting the language to English. However, we hope to follow up with releasing multilingual versions in the future!
Episodes/shows in this dataset were sampled from both professional and amateur podcasts including a wide range of topics, format, and audio quality. We can expect professionally produced podcasts to have high audio quality, but there is significant variability in the amateur podcasts — these vary in the quality depending on the professionalism of the creator. As for topics, there is a wide range, both coarse- and fine-grained. These include lifestyle and culture, storytelling, sports and recreation, news, health, documentary, and commentary. In addition, the podcasts are structured in a number of different ways. These include scripted and unscripted monologues, interviews, conversations, debate, and inclusion of other non-speech audio material.
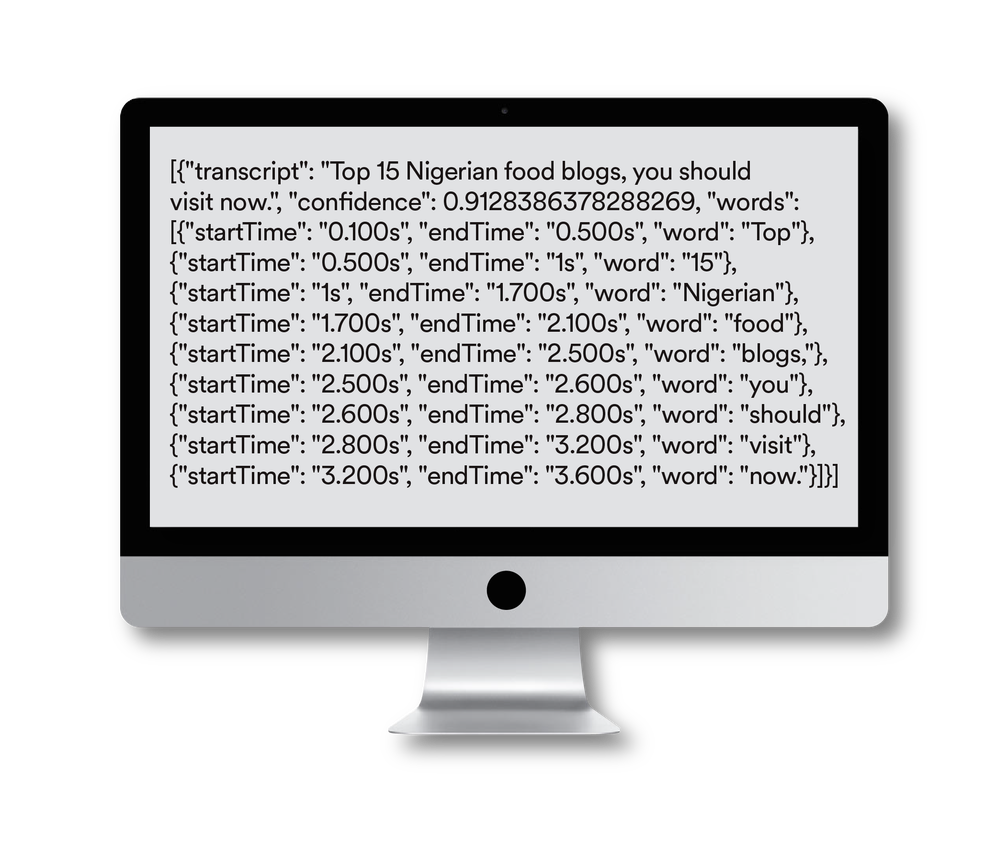
Here’s an example of what a snippet of a transcript might look like. You can see that each word is labeled with a timestamp:
As for the challenge, there are two tasks: search and summarization. The search task is to make content within a podcast searchable. This task gives as input a set of natural language queries (for example, “current status of legalization of medical marijuana”), and receives in response a ranked set of segments of podcasts, each with a specific start index. This helps users to find not just the relevant episodes to their query, but also the specific part of the podcast where the relevant content is, without listening through several minutes of audio that may precede it.
The summarization task takes as input the audio and transcript of a podcast, and generates an informative, brief, human-readable summary of the content of the entire episode. This provides us with meaningful summaries of podcast episodes to expose to users to help them decide whether they want to listen.
The dataset will be released April 16th, and the official task guidelines will be released by May 1. If you’re interested in learning more, we’ll be posting info here, where you can also sign up for the mailing list. To register for the challenge and acquire the data, please sign up with TREC here. And if you’re interested in joining us in solving these kinds of problems, we’re hiring!
SHARE THIS ARTICLE