Reach for the Top: How Spotify Built Shortcuts in Just Six Months

The launch of Shortcuts, which now appears at the top of Spotify Home, is an important step forward in how listeners experience their favorite music and podcasts. Engineering Manager, Damien Tardieu, tells the story behind the launch of this exciting new feature and why the methodology chosen to support its development was the foundation for success.
The quality of our personalized content is what differentiates Spotify from the rest of the music streaming industry. Playlists such as Discover Weekly and new podcast recommendations encourage listeners to try out original content and discover unfamiliar artists. But personalization should also put your favorite “go-to” content right at your fingertips. Getting this balance right, between familiarity and freshness, is one of the biggest challenges we face from a user experience standpoint.
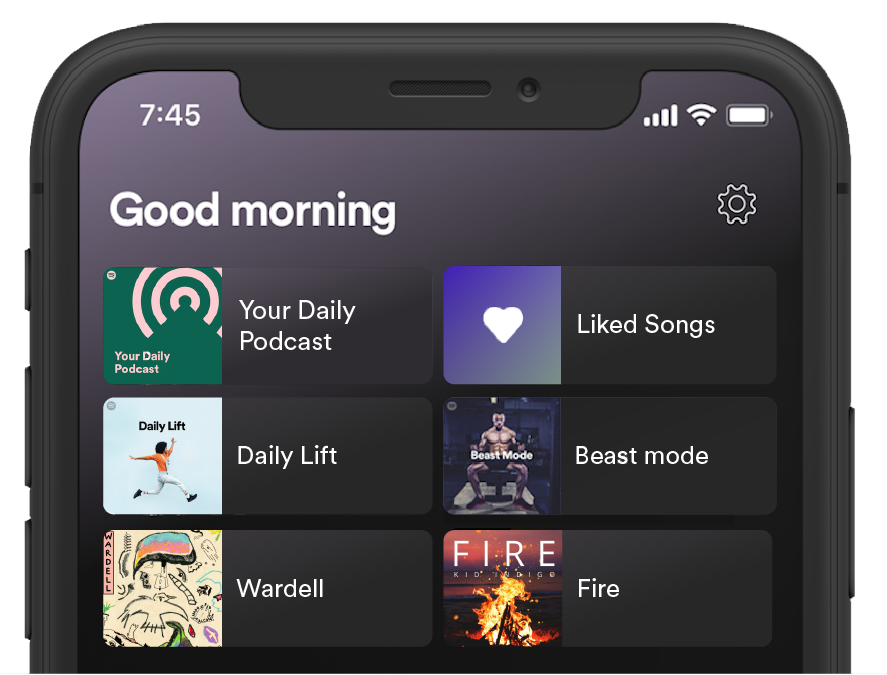
This is why Spotify is constantly looking for ways to improve our Home page. Early last month, we launched Shortcuts: a new way for listeners to dive back into recently-played and heavily-rotated music and podcasts. As you’ve probably seen by now, it’s the area at the top of your screen that contains six tiles (or what we call “entities”) that reflect your recent listening habits.
In the months leading up to our launch, many teams collaborated to create Shortcuts. We designed and tested a visually new User Experience (UX) that users could trust on Spotify Home. We augmented this UX with personalized recommendations based on what the user is most likely to play next. In the rest of this post, I’ll focus on how we identified and quantified the opportunity that Shortcuts could represent and then, how we developed recommendation heuristics and recommendation models. I’ll also explain the process we followed, the series of iterations on heuristics (and eventually models), and how we performed both offline and online evaluations in order to reliably recommend familiar and personalized
Understanding the user experience
Before developing a new feature, it’s crucial to understand if it will be useful, and by how much. Since the main goal of Shortcuts is to recommend user’s current favorites, our first step was to measure the extent to which users consume familiar content versus new content.
Our analysis showed that, over the course of a week, for a given user, a meaningful amount of listening on Spotify comes from a relatively small number of entities. An entity can be a specific user playlist, an album, or a podcast. It can also be a Spotify playlist like Rap Caviar, Discover Weekly or Release Radar. That’s not entirely surprising. However eclectic our musical taste, once we have discovered a new song or a new album that we really like, most of us have a tendency to play it over and over again. This is different from other media like TV, where we often only want to watch things once. We also have our regular routines for exploring new music, such as listening to Discover Weekly or Rap Caviar, or when catching up on the daily news from our favorite podcasts.
It was this analysis that led us to create Shortcuts, which was conceived as a dedicated space on Home where listeners can find their current favorites quickly.
How heuristics and ML models helped us build Shortcuts
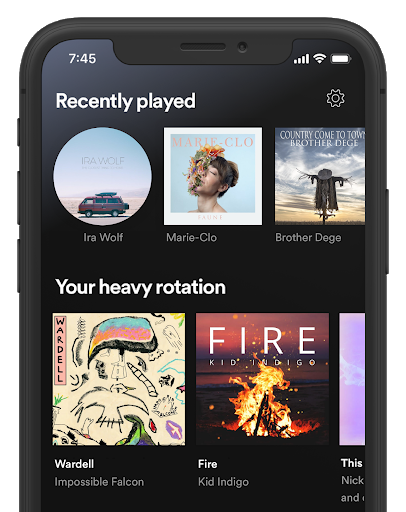
Home consists of horizontal sections, which we call shelves. Each shelf contains a number of entities. The shelf that surfaces most of the user’s current favorites, on average, is Recently Played, followed by Your Heavy Rotation, making both strong candidates for breaking down and examining favored content on Home.
As seen on the image to the left, a typical shelf on Home can display 2-3 elements on screen without needing to scroll. With this in mind, we conceived of Shortcuts as a condensed space at the top of Home that surfaces six playable entities to users. As a naive “minimum viable product”, by simply showing the top six entities from content in Your Heavy Rotation and Recently Played in this denser space, we estimated we could surface most of the current favorites of our users, using roughly the space of a single shelf. Of course, using this very naive approach would only give us a lower-bound baseline of accuracy in predicting the content a user might play next.
So, we worked next on refining the content recommended in Shortcuts by developing both heuristics and machine learning (ML) models. Having established a baseline, we could then optimize heuristics and models. The metric we chose to optimize was, specifically: maximize the amount of a user’s listening history that is represented by the six entities in Shortcuts.Having a baseline also enabled us to quantify the improvements obtained from new heuristics and models.
Validating our Hypothesis
The analysis mentioned in the previous section was based on users’ listening histories from the previous month, from any surface in Spotify. This means that users could have listened to their top entities via different sources including their Library page or the Search page.
Our initial hypothesis was: **by creating a dedicated space on the top of Home and populating it with a user’s favorite content, we can reduce the effort needed to find and play the content they want to listen to, right now.**Of course we wanted to validate this as early as possible and we began with an A/B test where the test experience had Your Heavy Rotation at the top of the home page and Recently Played directly underneath it. This enabled us to validate our hypothesis that users will listen to music from the top of the home page, even if they have previously accessed it from other surfaces in Spotify. Once validated, we could continue to refine the recommendations that we surface at the top of Home.
Refining Recommendations with Heuristics
There were strong reasons for starting with a heuristic technique rather than jumping straight into an ML model. To start with, heuristics act as a baseline with which we can compare future ML models against.
Moreover, heuristics:
Provide an improvement to the existing experience.
Enable us to iterate quickly.
Allow us to determine whether a model improves the recommendations to the extent that it is worth supporting in production.
Models are significantly harder to maintain, monitor, and debug in comparison to heuristics. What’s more, if we found that the model didn’t perform better than the baseline heuristic, there would be a good reason to keep a heuristic in production.
Another important reason for experimenting with different heuristics was the opportunity to validate our offline evaluations metric. Our offline evaluation consisted of computing the amount of a user’s listening history that can be represented by the six entities in the Shortcuts heuristic.
By running online experiments, and measuring the volume of listening from the Shortcuts heuristic, we were able to correlate our offline and online metrics. This provided an offline metric that we could use, when developing, to indicate whether or not the next proposed heuristic (or model) would perform well online.
When it came to the heuristics themselves, we had to make important decisions about what data to use and why. For example, only the user’s listening history from the past 90 days is in the set of candidates because Shortcuts is designed to reflect the user’s recent favorite content, rather than the more gradual changes that may take place over a series of months.
Starting with the algorithm used to select content for Your Heavy Rotation, we tested different modifications. Some of the heuristics used different decay functions, with more weight given to recently played content than older content. We also tested different ways of ranking the most familiar content, such as play frequency and play duration. Through many heuristics iterations, we tested a variety of parameters until we reached the heuristic that performed best in our online experiments (A/B tests).
Developing a Neural Net for Predicting Shortcuts
Once the heuristics became significantly complicated, it was time to move to an ML model. The models used the same data as the heuristics, but the data is heavily used for training purposes (and at prediction time for serving features). Specifically, each training example is a user’s listening history sequence, and the targets are the last items listened to by the user.
We used the Tensorflow library for feature transformation, and for building and training our models. To evaluate the models, we used Normalized Discounted Cumulative Gain (NDCG), a common metric used in many recommendation systems. A unique characteristic of our models is that they must output content that was in the input of the model (we are only recommending content that a user has listened to previously). Because of this, our models output a ranking of most familiar content based on the input for a given user.
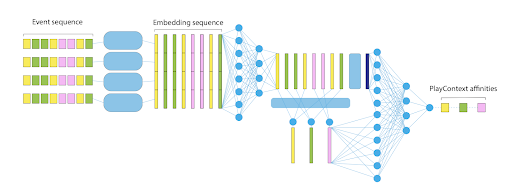
A neural net of the kind being used to train the ML model for Shortcuts.
The architecture of the neural network is the result of three months of ML research and more than 1,000 experiments. We started by replicating our heuristics with an ML model trained on data. Then, we modified the network architecture to improve the offline evaluation metrics. The final architecture showed a relative improvement of 26.7% compared to the heuristic model offline.
This architecture works in two steps. The first step uses a dense network to learn a relevant event representation (embedding) of each play event. This is done by mixing the timestamp, the intention of the play (active/passive) and the characteristics of the corresponding entity. These embeddings are then aggregated, per entity, and sent to a second dense network which scores each entity. This final output represents the probability of each entity being played next. Finally, we sort the entities according to their score with the top 6 presented to the user in Shortcuts.
Our models differed in a number of ways, including the set of features they consumed, the model architecture they leveraged, and how their hyper-parameters were tuned. We started with a simple model that was designed to mimic a heuristic and, therefore, ensured that modeling could perform just as well as heuristics. In this case, we created a model that recommended content with exponential decay (similar to the decay used in one of the heuristics).
Taking a similar approach to the development of a good heuristic, we tested multiple versions of the model, both offline and online. Our offline metrics included not only NDCG, but also the offline metric used to evaluate heuristics. By performing A/B tests, we were able to correlate NDCG scores with our online metric: the amount of listens coming from the Shortcuts section generated by models.
After more than 1,000 offline experiments and a series of A/B tests that included dozens of different model variants, we concluded that there was one that performed the best, and selected this model to be used for the launch of Shortcuts.
Moving the model to production
Before launch, we had to prepare for any issues that might arise when using the model to predict hundreds of millions of users’ Shortcuts. There was a significant amount of work that went into designing and building a system that monitors, alerts, and aids in debugging. This includes problems associated with serving the model, issues in upstream data sources that become serving features, and degraded quality in the recommendations output by the model.
The team used a number of tools to detect such issues. We built multiple hourly-batch pipelines that emit statistics on feature serving, characterize model outputs, and compute offline metrics in BigQuery tables. Subsequently, the data in these tables was used as inputs to monitoring dashboards, which were also configured with alert mechanisms. While problems may still arise, these tools allow us to detect them and respond much more quickly.
Key Takeaway
Our main takeaway from this project is that methodology trumps technology. Before diving into a machine learning algorithm implementation, we looked at the data from many different angles, ran many online and offline tests, and tried simple heuristics. By doing this, we acquired a much better understanding of the expectations of our users and were able to develop a clearer vision of the product we were trying to create… and the metric it should move. As soon as the vision is clear, it becomes much easier to choose the offline evaluation, the objective function, the training data and the architecture of a machine learning algorithm.
Just as important as putting this foundation in place was the ability to communicate the opportunity to the rest of the business. This meant we could start assembling a cross-functional team that included experts from UX, user research, product marketing and elsewhere. It’s this blend of individual autonomy and teamwork that makes working at Spotify unique—as is the feeling of satisfaction you get when you see a project that’s been nurtured for six months come to life for millions of end users.
What’s Next For Us
Although this new feature has been launched to all of our mobile app users, the work to refine the current display is ongoing. We are frequently asking users how they interact with Shortcuts to see how we can improve it further. For example, we are trying to understand the extent to which the six entities might change during the day according to your listening habits in the morning, at lunchtime and so on.
So there’s plenty more we can do! But it’s only possible thanks to the hard work and commitment of everyone involved in the Shortcuts initiative. Once again, I’d like to thank the team for making this possible. It was a tough assignment, but the past six months have been both exhilarating and rewarding. It’s been a pleasure to take part in it.
The Team: Adam Alix, Ethan Boye-Doe, Keenan Cassidy, Christophe Charbuillet, Tracey Churray, Annie Edmundson, Mark Kizelshteyn, Justin Li, Anil Muppalla, Nhi Ngo, Johan Pages, Yoshnee Raveendran, Yancey Reid, Isaiah Spicer, Damien Tardieu, Logan Wilson
SHARE THIS ARTICLE