Spotify’s New Experimentation Platform (Part 2)

So you’ve read Part I of our two-part series about the new Experimentation Platform we’ve built at Spotify, and now know why we decided to invest in a new platform. In Part II, you’ll get a more detailed look at how we assigned users to experiments, how we analyze results and ensure test integrity.
Coordination, holdbacks, and exclusivity
A lot of the experiments we run change some small aspect of the user experience in one of our prime surfaces and it’s important for teams to be aware of what other experiments are running at the same time, as well as what other experiments are running in their field of interest.
To accommodate for this, we allow experiments to be put into a “domain”. Domains roughly map different surfaces or systems in our service. Each domain has a timeline that shows what experiments have been running and what’s upcoming.
For illustrative purposes only.
When a lot of teams experiment in the same proximity, there’s risk of interaction effects. For this reason many experiments need to run in an exclusive manner, where a user can only be in one of a set of experiments that can potentially impact each other. Currently only experiments in a single domain can be exclusive to each other. We’re planning to decouple exclusivity from the domain concept, to allow for experiments across domains to also be exclusive to each other.
We implement holdbacks (the practice of exempting a set of users from experiments and new features, in order to see long-term effects and combined evaluation) in domains. Each domain can have a set of holdbacks. Users in these holdbacks are exempt from the general experimentation that happens in the domain.
At Spotify we have established a pattern where at the start of a quarter, we create a new holdback. Experiments that run throughout the quarter will never be assigned to any of those users subject to the holdback. When the quarter ends, a single test is run on these users where the combined experience of all (successful) experiments is given to the treatment group. This way we can get a read for the compound effect of everything the team decided to ship during the quarter. Once this test is done, the holdback is released and these users will go into new experiments.
The Salt Machine
At Spotify, autonomous are teams free to move at schedules that fit them best. This means that they need to be able to start and stop experiments at any time. With requirements of exclusivity and holdbacks, assigning users to experiments gets quite complex if we do not want to compromise on randomization (and we do not want to).
We have developed something we call the “salt machine” that automatically reshuffles users without the need to stop all experiments. This is done by hashing users into buckets using a tree of “salts” (it’s worth noting that if two experiments are disjoint because of targeting, we do not have to use the same salt tree for them).
For this article, imagine that we split users into 8 buckets:

A user ends up in bucket 1 if HASH(user id, SALT) % 8 = 1 and so forth. We allocate buckets to experiments. In the image below, experiment E1 has been allocated buckets 0 and 1. Note that we also have a per-experiment salt to spread users from the allocated buckets over treatments, but for simplicity we omit that from the images in this article.
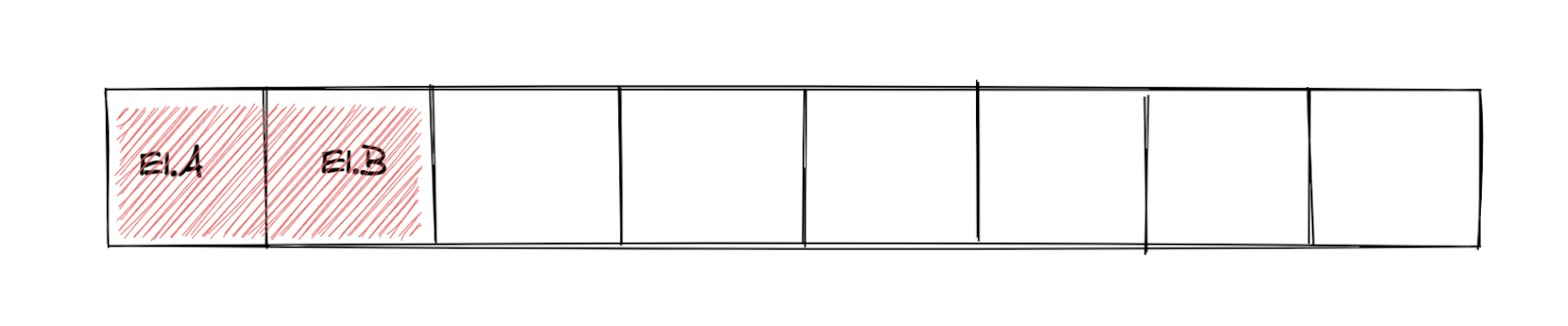
Since we’re experimenting a lot, most buckets are always allocated to an experiment. So what happens when two experiments (E1and E1) end, releasing some space that can be allocated to a new experiment?
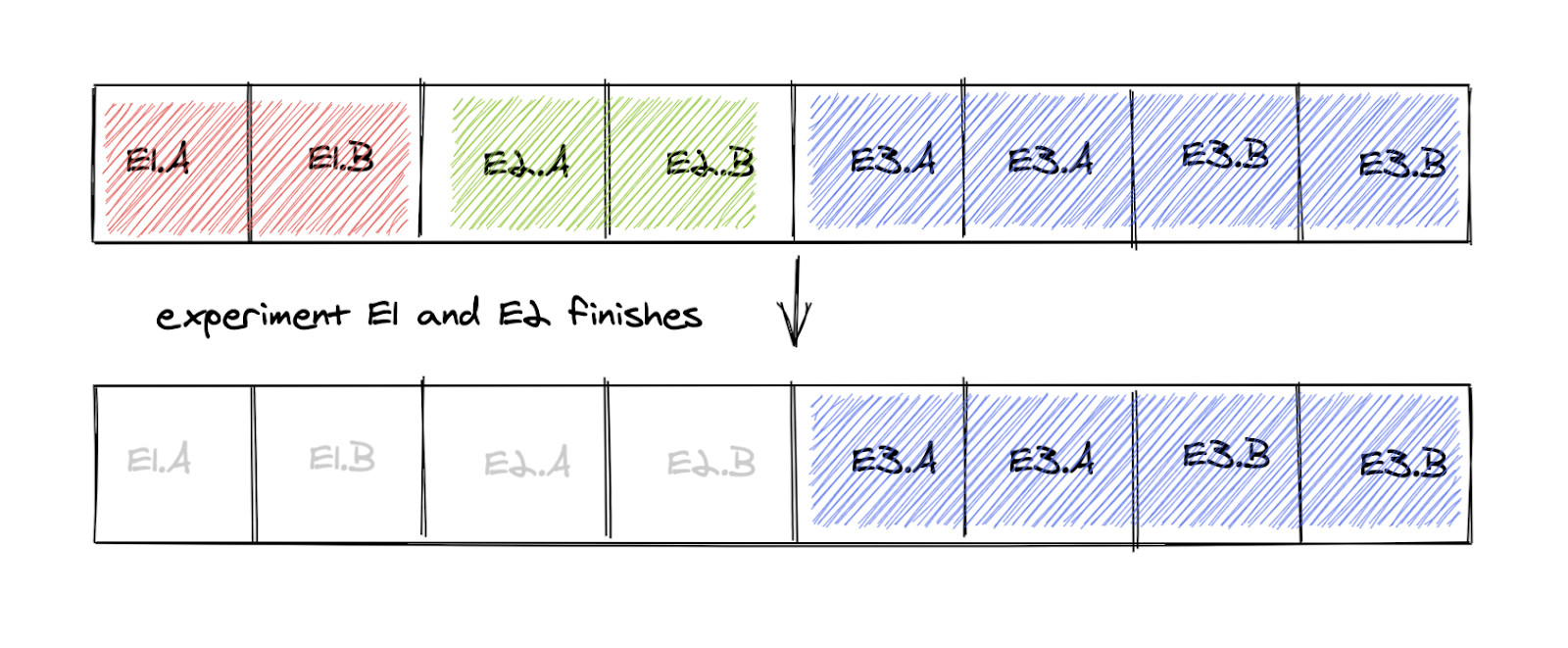
Now 50% of the buckets are free and we want to start E4 that needs 25% of the population. How can we allocate buckets safely without jeopardizing randomization? If we were to pick only bucket 0 and 1 we would have a 100% overlap with experiment E1 that just ended, which might lead to biased results due to carryover effects. Not good.

What if we shuffled the free users into new buckets using a new salt?
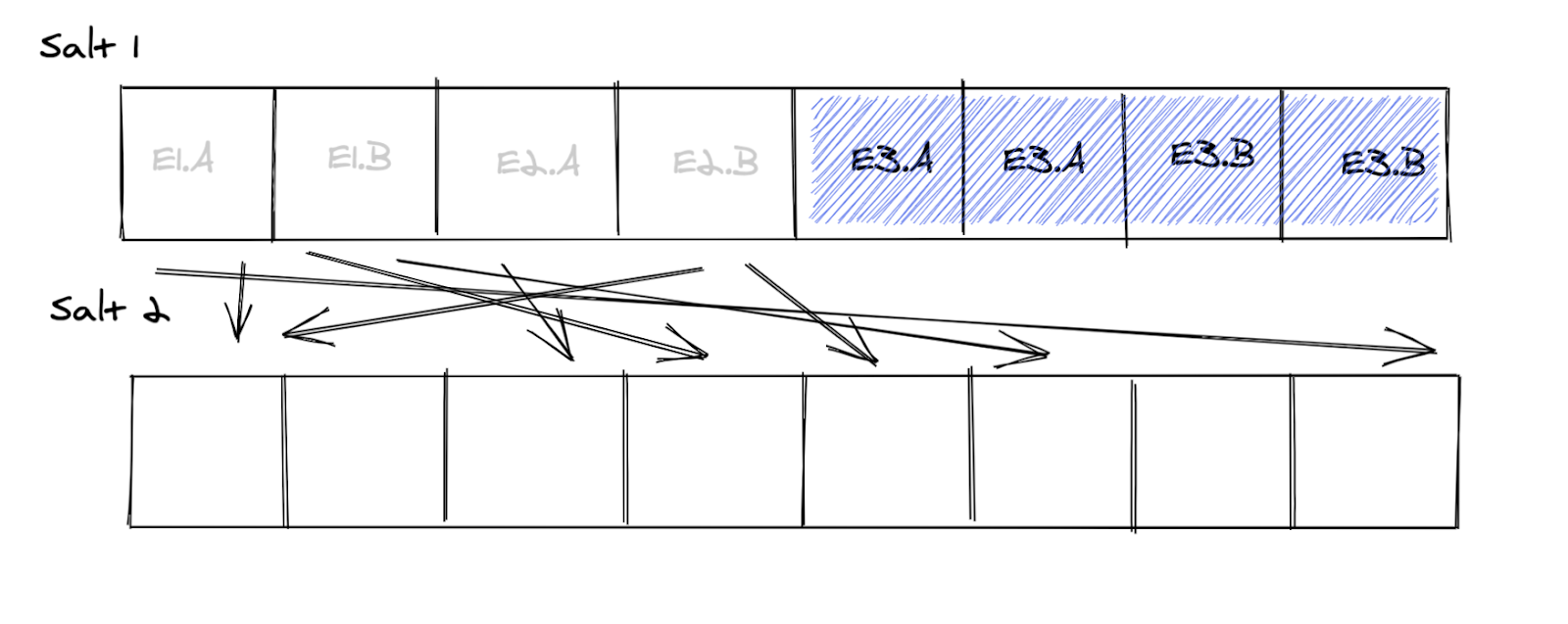
Now we have eight free buckets we can use for experiments. But because of the dilution of bucket size (those new eight buckets only get 50% of the traffic), we need to allocate four of them to E4 to get 25% of the population. We call the amount of required overallocation of buckets the “compensation factor” — and in this case it’s 1/.50 = 2. The remaining four buckets can be allocated to some other experiment.
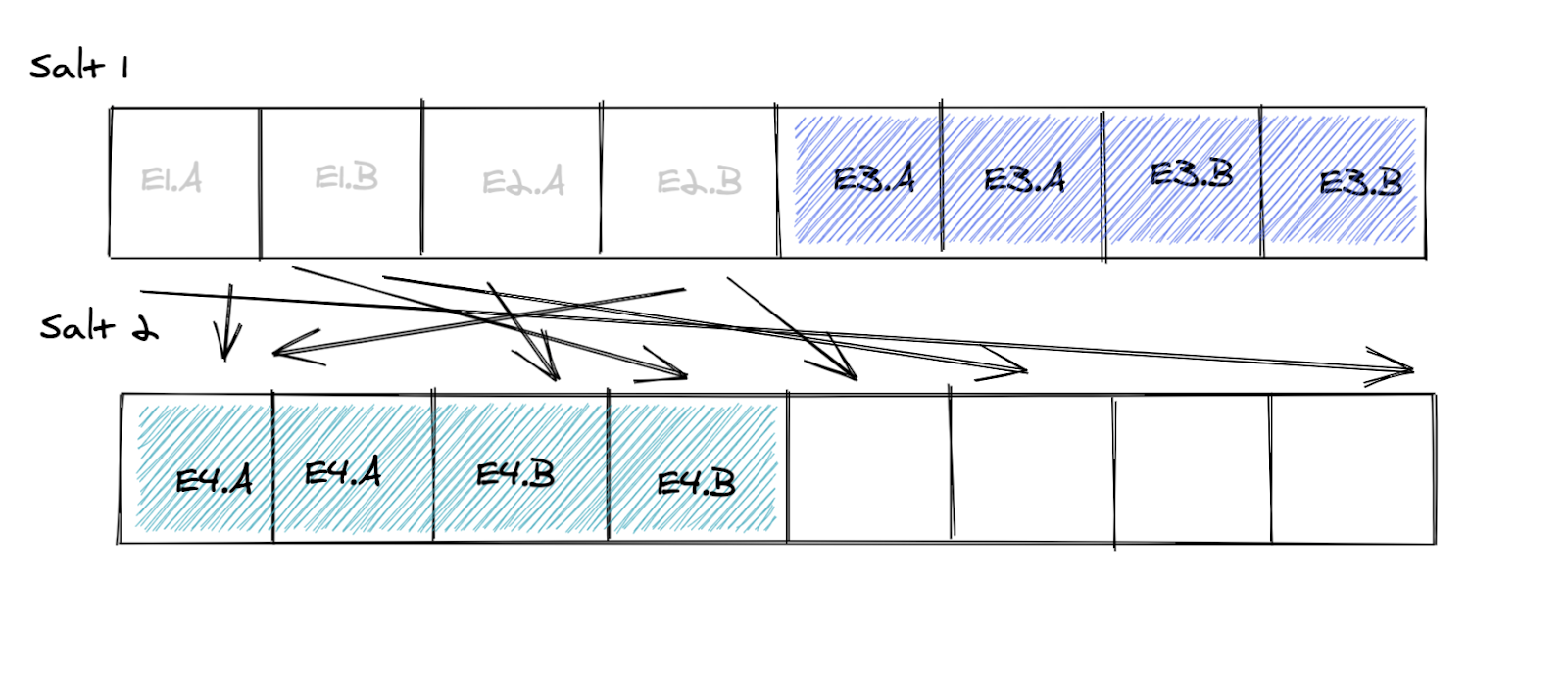
When experiment E3 ends we can completely get rid of salt 1 — but because we diluted the buckets the released space cannot be used until E4 finishes. In effect, we’re wasting 50% of the users.
The compensation factor changes all the time as experiments start and end. Over time we have learned that it’s good practice to not start new experiments if the compensation factor is higher than 5 (the higher the compensation factor, the more space is being wasted).
We’re currently working on the second iteration of our allocation scheme where we believe we waste less space but still maintain the benefits of randomization.
Analysis
To conduct a well-designed experiment we need to decide up front what we want to measure and test. The Experiment Planner asks that all necessary information be specified when an experiment is created. A metric can have one of two roles in an experiment:
Success metrics to find evidence for the hypothesis.
Guardrail metrics to find evidence that the experiment is not introducing any harmful side effects.
For each success metric it is possible to choose either a one- or two-sided statistical test.
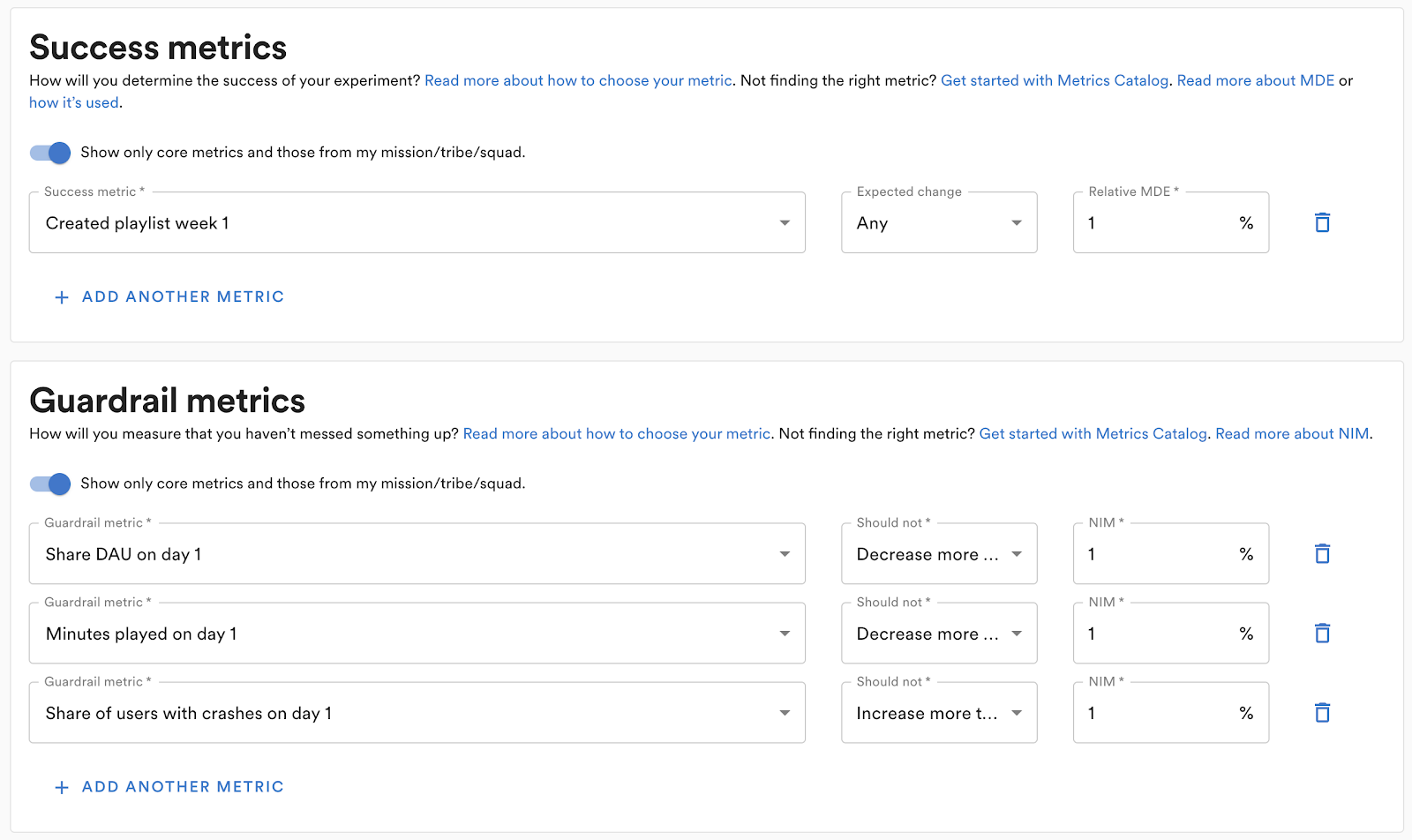
For success metrics, we perform superiority tests and require a relative minimum detectable effect (MDE) to be specified. This is used in power calculations in the result analysis and also in the sample size calculator.
For guardrails, we perform a non-inferiority test where a non-inferiority margin has to be specified so we know when a change is considered non-inferior or not.
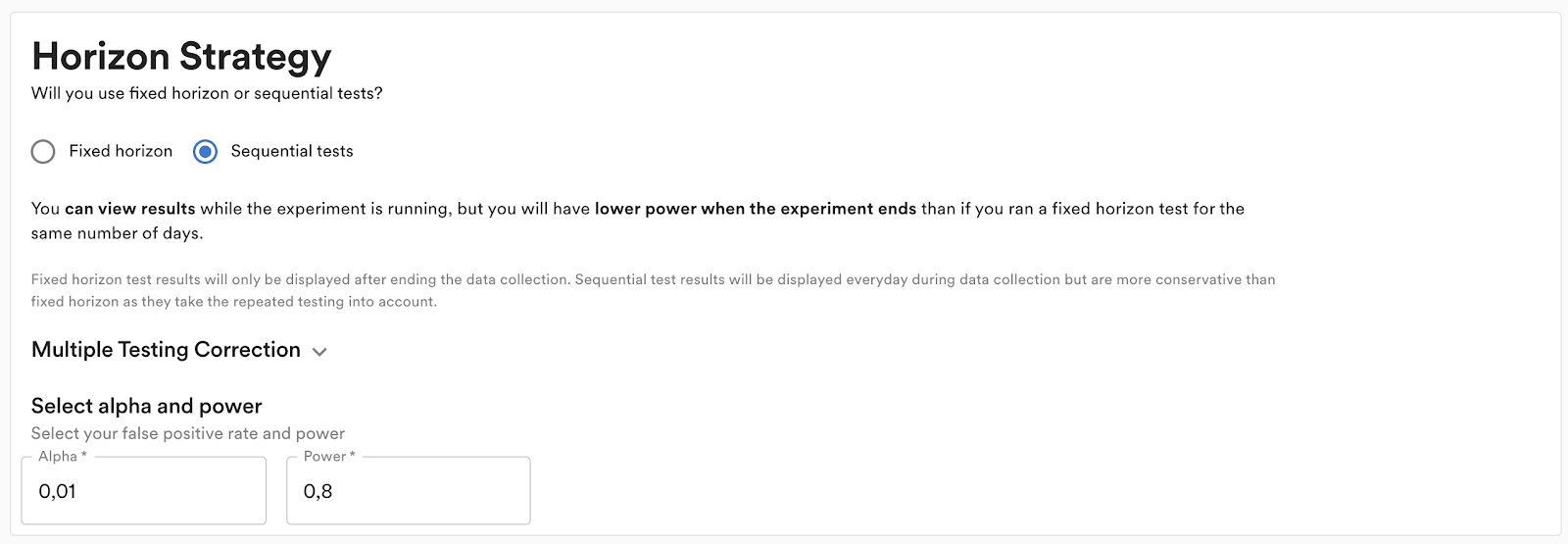
If the experimenter wants to see results as the experiment is running, they need to choose sequential testing. If they decide to do a fixed horizon test, the results will only be available once the experiment is stopped. Regardless, to minimize weekday biases we recommend that tests are always run for the planned period and are only stopped early if harmful side effects are detected. We also have an optional (but highly recommended) gradual ramp-up assignment of the experiment over a time period to further minimize possible weekday effects.
With a potentially large number of metrics, targeting, different statistical tests, and many treatment groups, it’s not always easy to calculate an accurate required sample size. For this reason we’ve built a sample size calculator and put it into the platform (it’s optional to use for fixed horizon tests, but required for sequential testing).
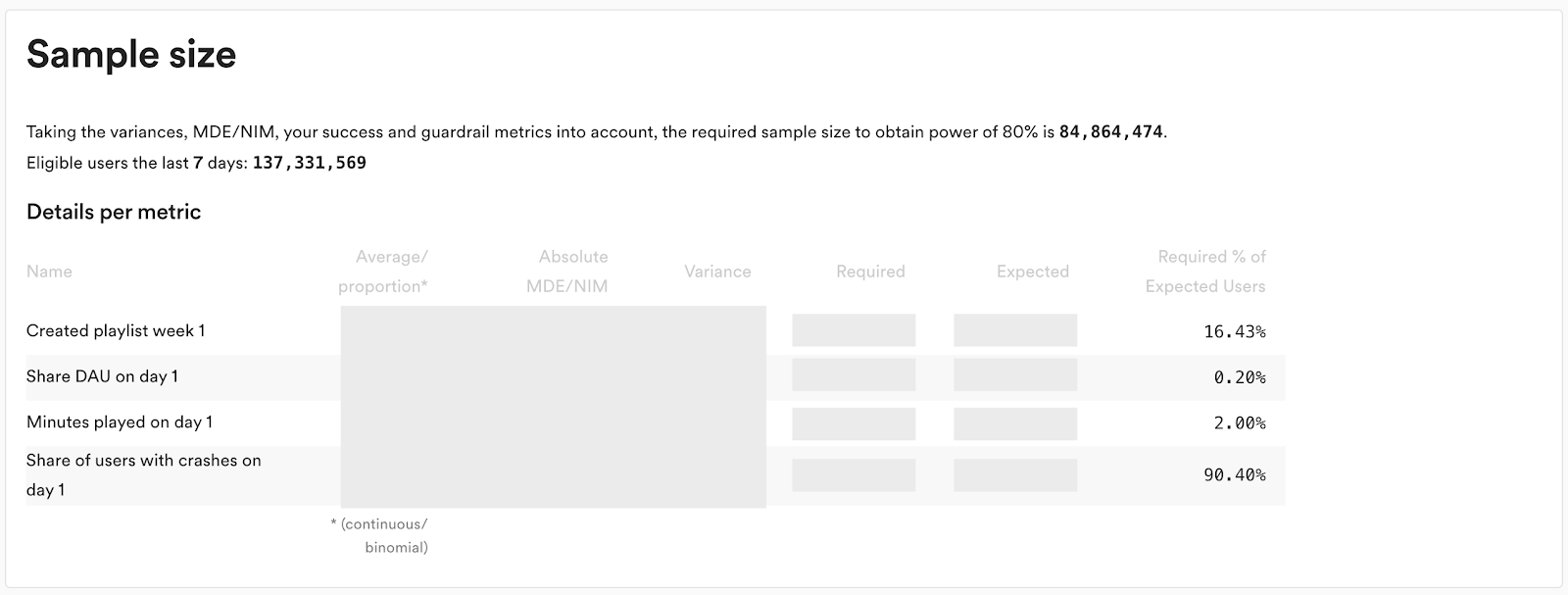
As can be seen above (numbers redacted), the sample size calculator shows how many users are needed to power the metric for the specified target population. The calculator automatically queries historical data for the specified target population to proxy the control group average and variance needed for the calculations.
Validity checks
Many things can go wrong when we run an experiment, and even subtle issues can have a big impact on the result. For this reason we’re continuously monitoring all running experiments for potential problems. If a problem is detected, we notify the owning team so that they can decide what to do.
We have the following checks in place:
Sample ratio mismatch: We make sure that the targeted proportion between the treatment groups align with exposure. If we see a statistically significant difference, we sound the alarm.
Pre-exposure activity: We see if there’s any difference in activity between the groups prior to the experiment starting.
Increases in crashes: We ensure that we do not see an increase in client crashes.
Property collisions: If two experiments use the same Remote Configuration properties (and are not exclusive to each other), we will warn that the experiments might not get the exposure that was expected.
For checks that require a statistical test, we deploy sequential testing and correct for multiple comparisons.
Rollouts
A use case supported by the Experimentation Platform, in addition to experimentation, is gradual rollouts. Once we learn that our change improves the user experience, we want to ship it, and with gradual rollouts we can do that while protecting against unexpected regressions.
There are two ways of doing rollouts: with or without statistical testing. If we select the latter, we will be able to select a set of guardrail metrics and deploy sequential testing so we can continuously monitor the progress. Every day we also provide one of three recommendations to the owning team:
We cannot detect any harmful effects, so the recommendation is to continue the rollout.
We have statistical evidence of harmful effects, so we recommend aborting the rollout.
We do not know yet, and we recommend continuing with caution or wait until we have more data.
The ability to get metrics for rollouts is fairly new so we’re still iterating on it, but we plan to make it the default option going forward.
Summary
We have spent the last two years rebuilding our experimentation capabilities at Spotify. The new platform is a step change in ease of use and capabilities, but we still feel it’s early for experimentation at Spotify.
We are constantly evolving our Experimentation Platform and practices. If you would like to know more, or if you’re interested in joining the team and contribute to our journey, do not hesitate to reach out.
Johan Rydberg, jrydberg@spotify.com / @datamishapExperimentation Lead
SHARE THIS ARTICLE



