Designing a Better Kubernetes Experience for Developers

TLDR; If you’re deploying a service with Kubernetes, you shouldn’t have to use all of your cluster management skills just to perform everyday developer tasks (like seeing which pods are experiencing errors or checking autoscaler limits). Backstage Kubernetes simplifies your deployment workflow by connecting to your existing Kubernetes implementation and aggregating the status of all your deployments into a single view — even across multiple clusters in multiple regions.
Navigating the complexity of Kubernetes
If you’re building a service today, you’re likely deploying it as a container, which is inside a pod, which is inside a cluster (alongside a bunch of other services that don’t belong to you), with deployments on different clusters spinning up and down all around the world. It can be hard to keep track of everything.
But despite widespread adoption of Kubernetes, all the tools for navigating this complexity have been focussed on the needs of cluster admins. This can make something as simple as checking the health of your service somewhat complicated.
That’s why we built a Kubernetes monitoring tool focussed on the needs of service owners and made it a core feature of Backstage, our open platform for building developer portals. We wanted to make the experience of managing services deployed on Kubernetes easier for all developers.
But first, how did we get here?
The rise of Kubernetes and DevOps
Since its release in 2014, Kubernetes has become one of the most widely adopted and important open source projects. Capabilities like autoscaling and cost optimisation through container scheduling used to be time-consuming and tricky to get right — now they’ve been democratised.
At the same time, the concept of DevOps has become mainstream. Developers now regularly perform tasks that were traditionally the domain of operations experts.
So, while everyday engineers can do more than ever before, their new powers have also come along with a new set of responsibilities.
New powers, shifting roles
When I first started using Kubernetes, cluster admins and service owners were one and the same: the people who built a cluster were usually the same people who owned the services that ran in the cluster. That’s not how it is today. As Kubernetes has achieved widespread adoption there has been a shift in Kubernetes usage as well as a shift in how Kubernetes is managed at the organisation level.
Now organisations tend to have a separate infrastructure team (sometimes not-so-ironically called the “DevOps” team) who build and maintain clusters for the feature developers and service owners. As the teams have become more specialized, the setups have become more advanced. For instance, the infrastructure team might set up Kubernetes clusters in multiple geographic regions in order to reduce end-user latency, wherever the user is in the world.
This is a better experience for the user, and it’s an optimization you might not have considered before Kubernetes existed or without a dedicated infrastructure team. But it also comes with productivity costs for the developer.
Frustration also scales
When your deployment environment reaches this kind of complexity and scale, the maintenance overhead for service owners increases. It forces them to use multiple kubectl contexts or multiple UIs just to get an overall view of their system.
It’s a small overhead — but adds up over time — and multiplies as service owners build more services and deploy them to more regions. Just checking the status of a service first requires hunting for it across multiple clusters. This can reduce productivity (and patience) company-wide.
Better tools for the job
We believed we could solve the problem through developer tooling. But we soon discovered the available tools weren’t suitable, because they:
- Don’t cater well for deploying to multiple Kubernetes clusters,
- Usually require that users have clusterwide permissions, or
- Display everything on a cluster and aren’t focused on the service the user cares about.
As we often do when we want to solve a problem involving infrastructure complexity, we wondered, why not build a custom plugin for Backstage, our homegrown developer portal?
Backstage Kubernetes: Manage your services, not clusters
Backstage provides vital information from Kubernetes — specifically focussed on the developer’s service. At a glance, the developer can see:
- The current status of their systems running in Kubernetes
- Including information aggregated from multiple clusters/regions
- Any errors reported by Kubernetes
- How close the system is to its autoscaling limits
- Container restarts
(Source: kubernetes.io)
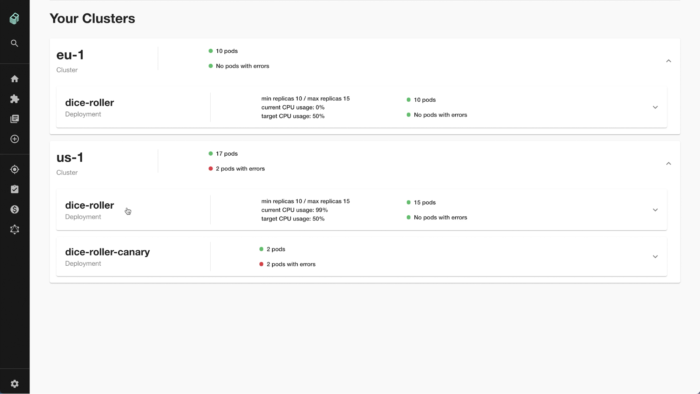
Figures above are for illustrative purposes.
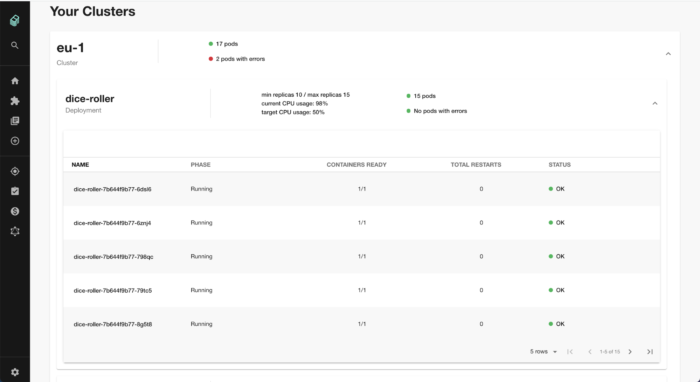
Figures above are for illustrative purposes.
Instead of spending 20 minutes in a CLI trying to track down which clusters your service has been deployed to, you get all the information you need to know at a glance. You can learn more about these features on the Backstage blog — or watch the demo video below to get an overview.
Everything about your service in one place
As a standalone monitoring tool, we think Backstage Kubernetes can improve the experience of any developer who deploys to Kubernetes. Combined with the other features of Backstage, developers get a complete solution for building and managing their services.
At the core of Backstage is its service catalog, which aggregates information about software systems together so you have a consistent UI and one tool for developers to use. For years, Backstage has provided one place for Spotify’s developers to see everything they need to know about their services (APIs, documentation, ownership, etc.). Now that includes the current status of their service, regardless of how many Kubernetes clusters they deploy to.
Now that Backstage is open source, we want to improve on what we have built internally and provide Kubernetes as a core component of Backstage for anyone to contribute to and benefit from.
Future Iteration
As we continue to grow and develop Kubernetes in Backstage with the community, we hope to offer support for Kubernetes resources beyond Deployments and Custom Resource Definitions.
Although at Spotify we currently use GKE extensively, Kubernetes in Backstage communicates directly with the Kubernetes API and is cloud agnostic, accordingly. It will work with other cloud providers, including AWS and Azure, as well as managed Kubernetes services, like Red Hat OpenShift.
To contribute or get more information on Kubernetes in Backstage, join the discussion on Discord!
Ask us anything: Matthew and the Backstage team will be hosting a Reddit AMA on March 3 at 4:00pm GMT. Send questions in r/kubernetes starting March 2.
A version of this article first appeared on The New Stack.
Tags: backend




