The Rise (and Lessons Learned) of ML Models to Personalize Content on Home (Part I)

At Spotify, our goal is to connect listeners with creators, and one way we do that is by recommending quality music and podcasts on the Home page. In this two-part blog series, we will talk about the ML models we build and use to recommend diverse and fulfilling content to our listeners, and the lessons we’ve learned from building the ML stack that serves these models.
Machine learning is central to how we personalize the Home page user experience and connect listeners to the creators that are most relevant to them. Like many recommendation systems, the Spotify Home page recommendations are powered by two stages:
Stage 1: Candidate generation: The best albums, playlists, artists, and podcasts are selected for each listener.
Stage 2: Ranking: Candidates are ranked in the best order for each listener.
In Part I of this series, we’ll focus on the first stage — the machine learning solutions we’ve built to personalize the content for listeners’ Home pages and, specifically, the lessons we’ve learned in building, experimenting, and deploying these models.
Home @ Spotify
The Home page consists of cards — the square items that represent an album, playlist, etc. — and shelves — the horizontal rows that contain multiple cards. We generate personalized content for listeners’ Home pages, algorithmically curating the music and podcasts that are shown to listeners in the shelves on Home. Some content is generated via heuristics and rules and some content is manually curated by editors, while other content is generated via predictions using trained models. We currently have a number of models running in production, each one powering content curation for a different shelf, but we will be discussing three of those models in this post, including: |
|

The Podcast Model: Predicts podcasts a listener is likely to listen to in the Shows you might like shelf.
The Shortcuts Model: Predicts the listener’s next familiar listen in the Shortcuts feature.
The Playlists Model: Predicts the playlists a new listener is likely to listen to in the Try something else shelf.
| Since we launched our first model to recommend content on Home, we have worked to improve our ML stack and processes in order to experiment and productionize models more quickly and reliably. |

The road to simplicity and automation
As anyone who may have contributed to operationalizing an ML model knows, moving a model from experimentation to production is no easy feat. There are numerous challenges in managing the data that goes into a model, running and tracking experiments, and monitoring and retraining models. While we have always tried to keep our ML infrastructure simple, and as close to the sources of features as possible, it has become drastically easier for our squads to deploy and maintain models now than when we started.
At a high level, an ML workflow can be broken down into three main phases: 1) data management, 2) experimentation, and 3) operationalization.
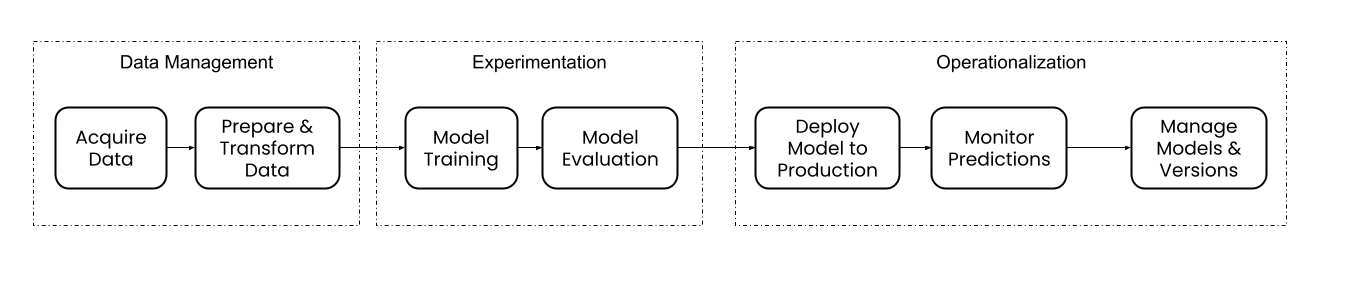
It’s common to iteratively work on the training and evaluation phase until a final model version is selected as the best. This model is then deployed to production systems and can start making predictions for listeners. Similar to most production systems, models (and the services/pipelines that serve them) should be monitored closely. To keep a model up to date (which is more important for some tasks than others; more to come on this), retraining and model versioning are the last steps in our workflow. This part of our stack and workflow has had significant changes since our first model — making batch predictions (offline) of content listeners are likely to stream — to now, where all our models are served in real time. The figure below shows where our machine learning stack started and where we are now:
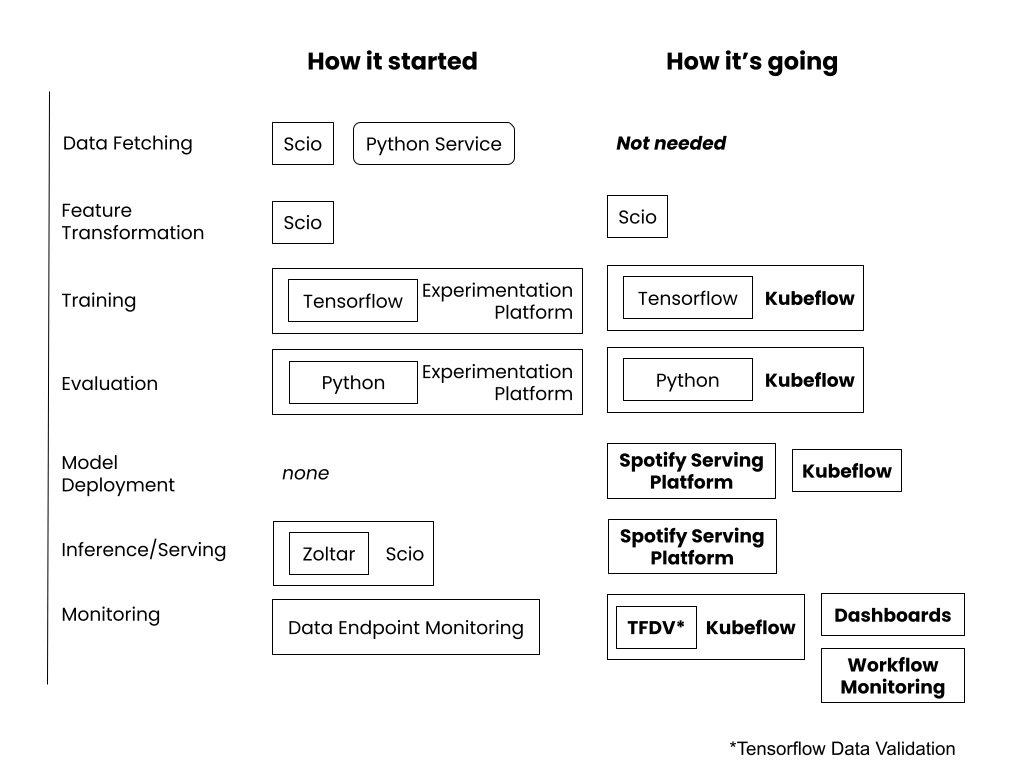
Our current ML stack automates a lot of the processes involved in maintaining models in production (with online serving): we have automated feature logging instrumented in our serving infrastructure, with both scheduled Scio pipelines to transform these features and Kubeflow pipelines to retrain weekly. We have also implemented data validation of our training and serving features (as well as validation between subsequent training datasets) to verify our features are consistent and follow the same distributions at training and inference times. In our Kubeflow pipelines, we have components that check the evaluation score and automatically push the model to production if the score is above our threshold. With this stack, we monitor and alert on the automatic data validation pipeline, as well as the online deployments of our models — allowing us to handle any issues as soon as they arise.
With a lot of effort and many lessons learned, our ML stack has evolved to make these processes automated and more reliable, enabling us to iterate faster to improve our models and increase our engineering productivity.
How we unified training and serving data
When we first start to think about a problem, we always dig into the data first — what data would be useful? What data is available? And then we take a really close look at the data that will be used for features, characterizing what is in the dataset and identifying the edge cases in the data. We feel fairly confident about the contents of the data used for our training features as well as what the transformed data looks like, but features fetched and transformed at serving time are an entirely different story.
Batch training data and batch predictions
Historically, we have had one set of infrastructure for fetching and transforming features during experimentation (training) and a different set of infrastructure for fetching and transforming features for making predictions (serving).
Then we started to make online predictions (… with the wrong data)
When we changed the Podcast Model from making batch offline predictions to serving in real time, we set up a new service that could support this — this new service had to fetch and transform features, make the prediction, and respond to the request. The important part here is that the feature processing and transformation was now in a different place than where the corresponding training feature processing took place. And, unfortunately, models are like black boxes, so testing the output is difficult, if not impossible. A while ago, we discovered that we had been transforming one of the model’s features slightly differently at training time than at serving time, leading to potentially degraded recommendations — and there was no way to detect this, so it continued to happen for four months.Think about this for just a second. Such a simple part of our stack — at most, a few lines of code — was doing the wrong thing and impacted the recommendations produced by our model. Our short-term fix was to simply change the one line of code in our prediction service that was causing the issue, but we knew long term that we needed to either have a single source of data for both training and serving, or we needed to ensure that data was produced and transformed the same way in both stages.
One transformation implementation to rule them all
Our first approach was to make any feature processing and transformation occur in the same code path, so that training and serving features would be processed identically. Taking the Shortcuts Model as an example again, our goal was to get rid of the Python service that transformed training features — this service was always running and constantly checking, on all days, to see if it was a Monday; if so, then it would request data from the necessary service (at a rate-limited 5 requests/second) and transform them into features; ideally, this would have been implemented as a pipeline, but we couldn’t schedule and orchestrate it because the process took more than 24 hours. There were many reasons we wanted to migrate away from this approach, but logging features when the only data source for features is a different service (owned by a different squad) proved difficult. Using our serving infrastructure’s feature logging capabilities, we could automatically log already transformed features, which could later be used for training. At this point, all of our features for training and serving were being transformed by code in the Java service. And we now use this feature logging for all of our models both to solve this problem, and also because it reduces the amount of additional infrastructure we need to support.
But wait, we can do more by validating our data
The second approach we took to ensure our training and serving features did not differ was to use Tensorflow Data Validation (TFDV) to compare training and serving data schemas and feature distributions on a daily basis. The alerting we have added to our data validation pipeline allows us to detect significant differences in our feature sets — it uses the Chebyshev distance metric, which compares the distance between two vectors, and can help alert us to drift in training and serving features.
While we knew that understanding what is in our data is crucial, we quickly learned that it’s easy to make mistakes when moving models to production because the data often uses a different processing library. We didn’t expect many data differences, but validating and alerting on issues lets us know if something changed, and how we should remediate the issue.
Stay tuned for Part II as we take a closer look at how we evaluate our models using offline and online metrics, why it’s so important to actually look at the recommendations we are making, and the challenges we faced in our journey to CI/CD in model retraining.
SHARE THIS ARTICLE



