Product Lessons from ML Home: Spotify’s One-Stop Shop for Machine Learning

Introduction
Building platforms is a hard business. Building platforms for discerning machine learning (ML) practitioners with bespoke needs and a do-it-yourself ethos is even harder. In today’s post, we will give you a peek into how we built ML Home, the internal user interface for Spotify’s Machine Learning Platform, and the product lessons we learned along the way in our quest to entrench it in Spotify’s ML ecosystem.
It’s a massive understatement to say that machine learning is at the heart of Spotify’s success story. Spotify has delivered beloved audio experiences such as Discover Weekly, Daily Mix, and Wrapped on the strength of ML-powered personalized recommendations. Today, almost every part of Spotify has some applied ML systems, and a significant and growing portion of our R&D teams consist of ML engineers and data scientists. In order to support ML systems at the scale and speed that our business requires, and to apply ML responsibly for our listeners, we have platformized sizable parts of the most common ML infrastructure within our Machine Learning Platform.
Overview of Spotify’s ML Platform
Since the beginning, our ambition for Spotify’s ML Platform was to connect the end-to-end user journey for ML practitioners. We subscribe to the “walking skeleton” model of product development, focusing from the start on end-to-end workflow and subsequently fleshing out functionality once we’ve proven value.
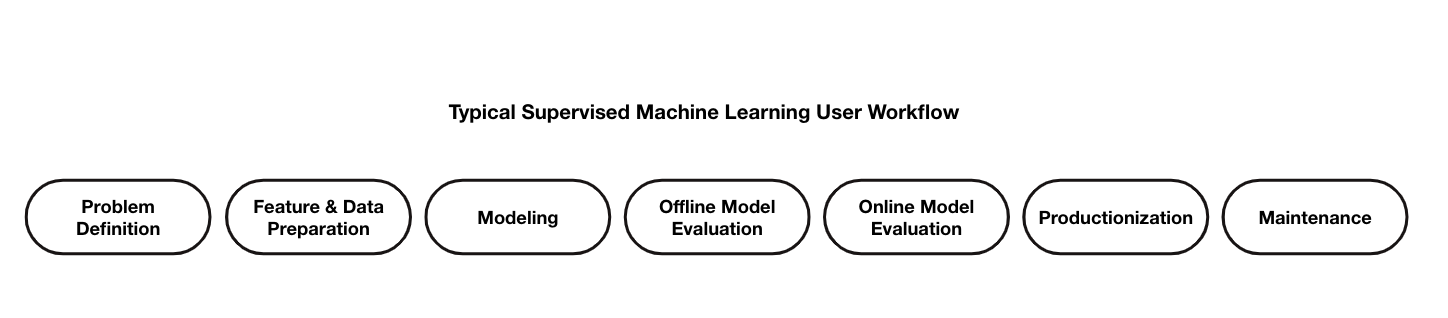
In late 2019 / early 2020, our ML Platform consisted of a few components that covered the (supervised) machine learning workflow experience for Spotify’s ML practitioners:
Spotify Kubeflow**,** which is our version of the open source Kubeflow Pipelines platform that helped us standardize ML workflows on the TensorFlow Extended (TFX) ecosystem
Jukebox,which is based on TensorFlow Transform and powers our feature engineering and management workflows
Salem, which is based on TensorFlow Serving and helps us standardize model serving and production workflows, and
Klio, which is our open source solution for audio processing with Apache Beam and Dataflow

The Product Opportunity
As we started to onboard more ML teams onto our platform, we identified two important gaps in our end-to-end support for ML workflows:
A centralized metadata layer,where we could define our platform entities / entity relationships (e.g., models, evaluations, training sets)
A metadata presentation layer, where users could store, track, and manage the metadata generated from their ML workflows, which is the focus of this blogpost
As the ML Platform team, we knew we wanted a tool where ML engineers could store ML project information and access metadata related to the ML application lifecycle, but weren’t entirely sure what that product would be. As we began exploring, we found that teams were using spreadsheets to track ML metadata and gave us hyper-specific feature requests for their individual problems. We also came away with broader unmet needs such as discovery of ML projects**,** support for ML team collaboration**,** and important productgaps within our own ML Platform tooling. These learnings informed the initial scope of our MVP (minimally viable product) and taught us our first product lesson.
Product Lesson 1: Balancing Product Vision and Product Strategy
For the first iteration of the product, we took a T-shaped approach. We focused on building horizontal solutionsfor needs we heard most commonly across all ML practitioner roles, such as being able to collaborate more effectively as an ML team. We also built a vertical solutionthat mapped to a specific platform tooling gap: better evaluation tooling for offline model training for ML engineers. We launched our MVP with an aspirational name and product vision: ML Home, one-stop shop for machine learning at Spotify.

The initial feedback we received on our MVP fell on two ends of the spectrum. Individual contributions struggled with the broad idea of a “one-stop shop” and wanted to know what concrete problems the product could solve for them today. Leadership wanted to know how many users we would serve over the long run and how big our impact could be.
Throughout the process of selling our MVP, we learned how difficult it is to balance product vision and product strategy without compromising one for the other. Had we scratched our broader vision based on the initial feedback and focused exclusively on the concrete needs (e.g., I want to see all my training pipelines in one view), we would have risked delivering a narrow point solution. On the other hand, if we over-indexed our roadmap on the broad, ambiguous needs (e.g. I want to collaborate more effectively with my team), we would have delivered a nice-to-have but not a must-have product.
By intentionally keeping our Product Vision broad and future-looking (one-stop shop), we gave ourselves the runway to think bigger about our solution space and our potential impact down the line. And by keeping Product Strategy concrete and iterative (offline evaluation tool), we were able to ensure that we solved concrete problems that over time helped us ingrain the product into our user’s daily workflows.
Product Lesson 2: The Limits of MVPs
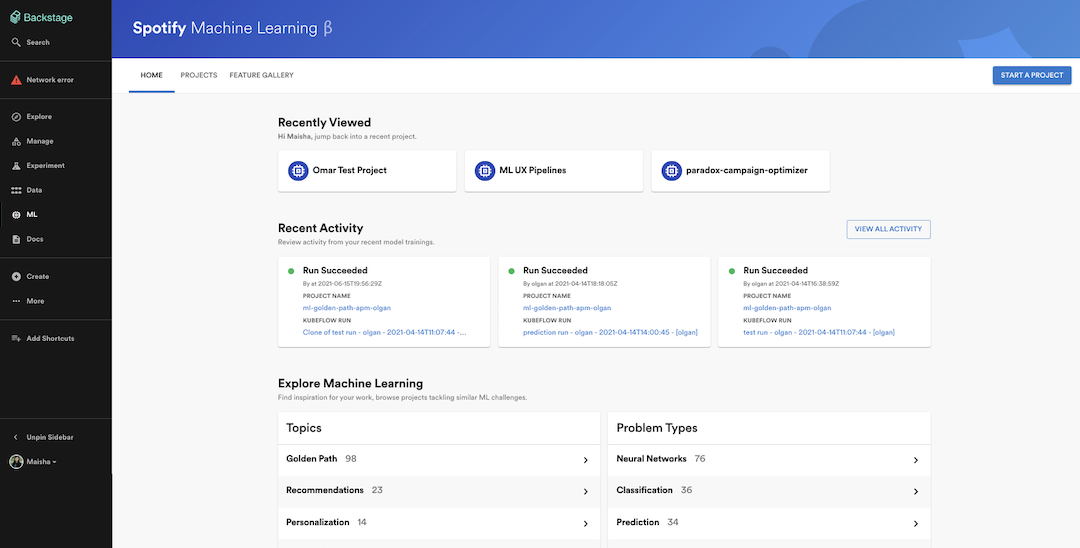
ML Home
As we wrapped up the feedback and adoption drive for the MVP, we learned our second product lesson. It is no secret that driving product adoption is hard, especially for products that are trying to replace existing solutions or market incumbents. We hit the ceiling of our MVP’s potential fairly quickly. We did not see a surge of adoption beyond the handful of users who were involved in the very early ideation process. Most users understood the value proposition of what we were building, but did not see enough depth to switch over from their existing tooling. In retrospect, our expectations of what we delivered and how valuable it would be did not match the depth of our users’ needs. It would have been easy at that stage to dismiss the product entirely, based on early adoption signals. That would have been a mistake.
As we plowed on with more detailed user feedback in our quest to drive more adoption, it became clear to us that we were misplacing our expectations on what role the MVP played in the product development process. The most valuable end goal of an MVP is to get enough of the vision and strategies out there to help validate or invalidate them. Our initial MVP helped us test and de-risk our work because we were able to get detailed validation of the workflows from ML teams and lay out the technical foundations for the product. It did not matter how many daily active users we had at that stage, as long as we had enough users (which we did) who saw the value in what we were building. These users continued to attend our user feedback sessions and helped us get the product to a higher and more valuable place.
Product Lesson 3: Knowing the true Differentiators
As we moved beyond the MVP phase and started to map out our next steps (focusing on some aspects of the product over others), we learned our third and perhaps most important product lesson. We realized that in order to provide a really valuable product to our users, we needed to not only reach feature parity with existing solutions, but also double down on ML Home’s unique differentiators. In short, ML Home as a product needed to be more compelling than the competing solutions.
For a while, we probed, debated, and stack-ranked specific features and workflows that we felt would be game-changing for our users. Our theory was that if we built a “compelling feature,” it would be able to singularly pass a threshold for users to adopt. In the end, we realized that the unique differentiators for ML Home actually came in the form of our other ML Platform offerings, not any one individual feature.
While some aspects of ML Home could functionally serve as a stand-alone product, by enriching it with training, evaluation, and system metadata generated from the rest of our ML Platform, it became a much more compelling product. ML Home’s unique differentiator isn’t any one silver-bullet feature but rather the gateway value it provides as the sum of our ML Platform capabilities.
Much of the work we did in this phase was building out our metadata service to consolidate our overall entities and concepts across the platform, but we also spent significant time building flexibility into the product’s interface. For example, annotation capabilities such as tagging and notes became key features that enabled teams to customize and mirror their own workflows. That, paired with a faster, slicker product experience and information-rich model comparisons, tipped the balance in our favor.
By the time we released the second version of ML Home, we had successfully onboarded more ML teams who were actively using the product in their daily workflows.
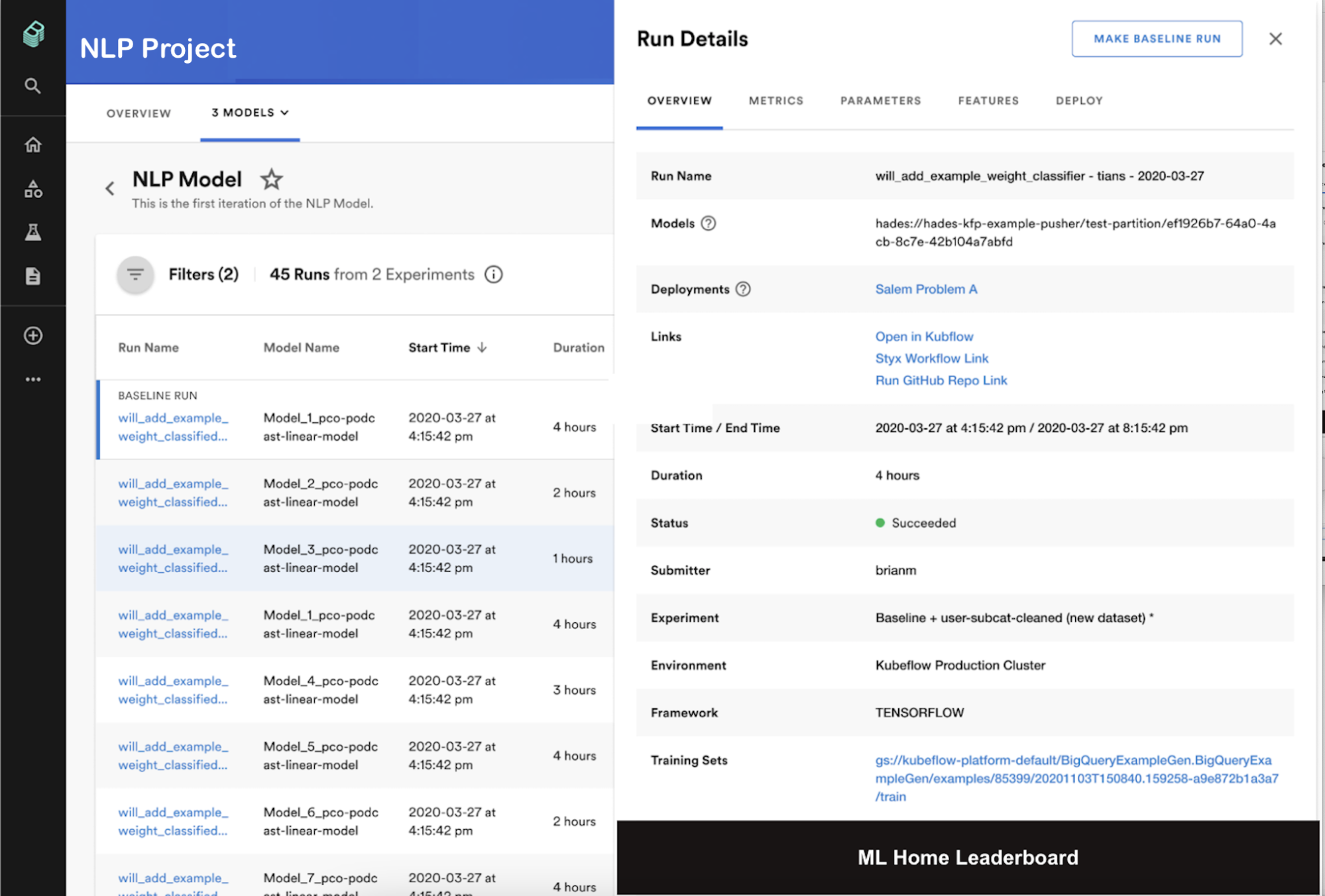
Sample ML Project in ML Home. For illustrative purposes only.
Scaling the Product to Our Vision
Getting closer toproduct-market fit taught us a lot about how to iterate moving forward. We knew that ML Home only served one typical ML workflow. However, in order to be an indispensable product for all ML practitioners, it needed to cover more ground. We also knew that tightly coupling ML Home’s capabilities to our existing ML Platform products resulted in a much higher rate of adoption than stand-alone solutions. Armed with these takeaways, we wireframed a broader vision for the product.
Today, ML Home provides Spotify’s ML practitioners with artifacts and workflow metadata of all models passing through individual components of our ML Platform. It includes capabilities such as the ability to track and evaluate offline experiments, visualize results, track and monitor deployed models, explore features, certify models for production readiness, and much more.
Through intuitive workflows and simplified information architecture, users are able to quickly spin up a project space to collaborate with their team and discover the 220+ ML projects across Spotify currently listed in ML Home.
We have seen a 200% growth in daily active users since we began our scaling efforts a year ago, and ML Home is now solidly entrenched in the daily workflows of some of the most important ML teams at Spotify. Despite its short tenure in Spotify’s Infrastructure landscape, ML Home is well on its way to becoming the one-stop shop for all things ML at Spotify.
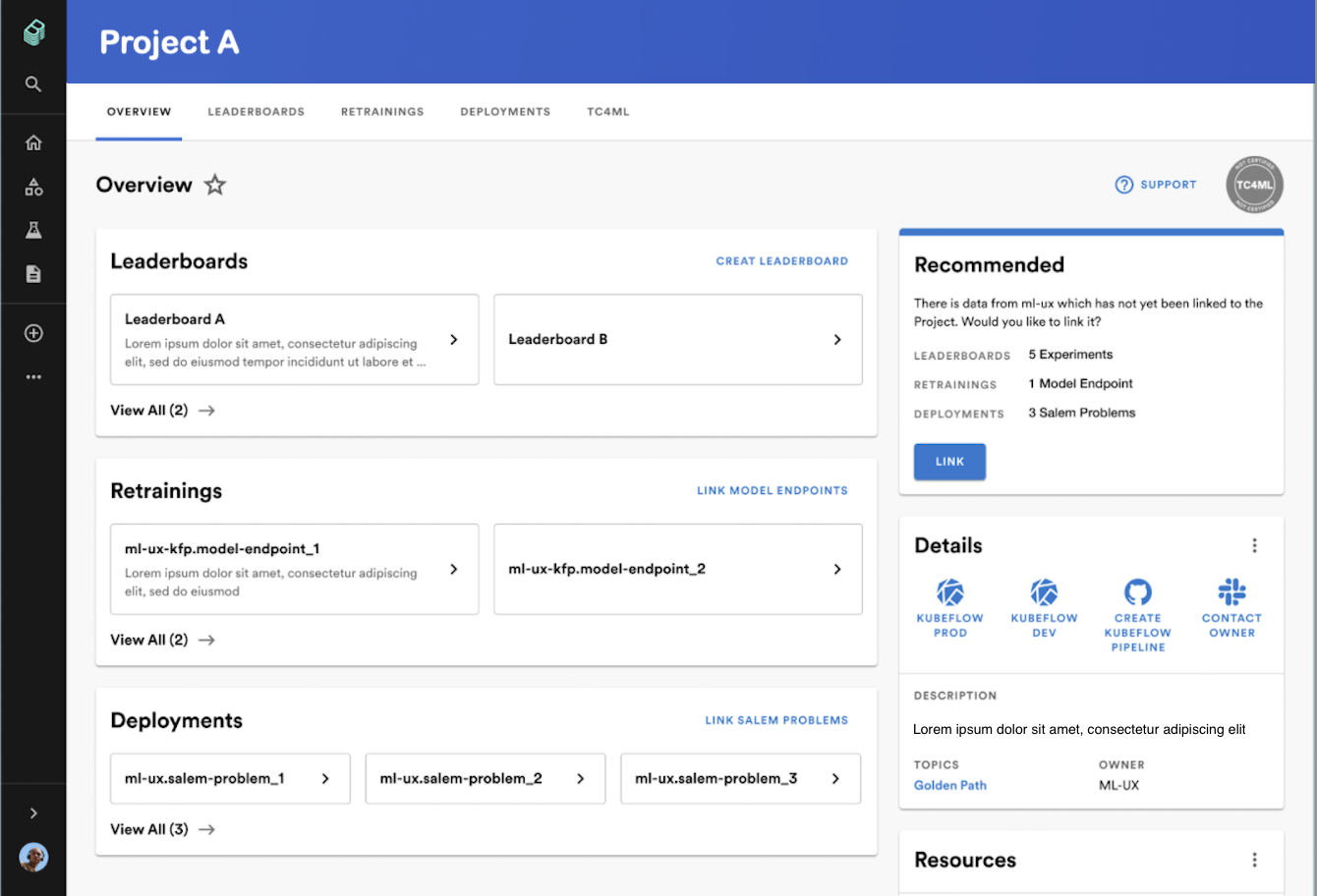
Conceptual rendering of ML Home. For illustrative purposes only.
Three Key Lessons
The saying goes that hindsight is 20/20, and it’s true. Looking back, these are the lessons that stick out the most from our product development process:
Product vision vs product strategy. It is difficult to strike the right balance between an inspiring vision that can support future solutions and a responsive product strategy that addresses today’s problems. But it is crucially important to not conflate the two in the early stages of product development.
Limits of MVPs. MVPs provide the most value as a validation and de-risking tool for product strategy and overall direction.
Know the true differentiators. It’s worth paying attention to what the real differentiators are for a product. It does not have to be a “compelling” feature; it can simply be opportunities found in the ecosystem that turn the tide for a product’s success.
Looking Ahead
ML Home is not done — not even close. We know this because, in the last year, Spotify’s ML community has proposed new and inventive ways to evolve the product. For exampleML engineers saw the potential to build on top of ML Home and proposed we build production readiness certification of ML models in the interface. In addition, we are exploring aspects such as explainability to advance model interpretability and observability to better understand model health. Then there are the ever-inspiring hack week projects that tell us that our product has taken root at Spotify. We are excited for what’s next!
If you are interested in building cutting edge machine learning infrastructure at Spotify, we are hiring for engineering and product roles across the board.
Acknowledgments
ML Home would not exist without the brilliant work of the ML UX team, our teammates from ML Platform, and the generous guidance from Spotify’s ML community. Since the list of individuals to thank would far exceed the words in this post, I will instead mention the individuals whose work made ML Home possible: Johan Bååth, Joshua Baer, Hayden Betts, Martin Bomio, Matt Brown, Keshi Dai, Omar Delarosa, Funmilayo Doro, Gandalf Hernandez, Adam Laiacano, Brian Martin, Daniel Norberg, James O’Dwyer, Ed Samour, Wesley Yee, and Qi Zheng.
SHARE THIS ARTICLE



