Introducing Natural Language Search for Podcast Episodes

Beyond term-based Search
Until recently, Search at Spotify relied mostly on term matching. For example, if you type the query “electric cars climate impact”, Elasticsearch will return search results that contain everything that has each of those query words in its indexed metadata (like in the title of a podcast episode).
However, we know users don’t always type the exact words for what they want to listen to, and we have to use fuzzy matching, normalization, and even manual aliases to make up for it. While these techniques are very helpful for the user, they have limitations, as they cannot capture all variations of expressing yourself in natural language, especially when using natural language sentences.
Going back to the query “electric cars climate impact”, our Elasticsearch cluster did not actually retrieve anything for it… but does this mean that we don’t have any relevant content to show to the user for this query?
Enter Natural Language Search.
Natural Language Search
To enable users to find more relevant content with less effort, we started investigating a technique called Natural Language Search, also known asSemantic Search in the literature. In a nutshell, Natural Language Search matches a query and a textual document that are semantically correlated instead of needing exact word matches. It matches synonyms, paraphrases, etc., and any variation of natural language that express the same meaning.
As a first step, we decided to apply Natural Language Search to podcast episode retrieval, as we thought that semantic matching would be most useful when searching for podcasts. Our solution is now deployed for most Spotify users*.* Thanks to this technique, one can retrieve relevant content for our example query:

Example of Natural Language Search for podcast episodes.
It is noticeable that none of the retrieved episodes contains all of the query words in their title (that’s why Elasticsearch was not picking them up). However, those episodes seem quite relevant to the user’s query.
To achieve this result, we leveraged recent advances in Deep Learning / Natural Language Processing (NLP) like Self-supervised learning and Transformer neural networks. We also took advantage of vector search techniques like Approximate Nearest Neighbor (ANN) for fast online serving. The rest of this post will go into further detail about our architecture.
Technical solution
We are using a machine learning technique called Dense Retrieval, which consists of training a model that produces query and episode vectors in a shared embedding space. A vector is simply an array of float values. The objective is that the vectors of a search query and a relevant episode would be close together in the embedding space. For queries, we use the query text as input to the model, and for episodes, we use a concatenation of textual metadata fields of the episode such as its title, description, its parent podcast show’s title and description, and so on.
During live Search traffic, we can then employ sophisticated vector search techniques to efficiently retrieve the episodes whose vectors are the closest to the query vector.

Shared embedding space for queries and podcast episodes.
Picking the right pre-trained Transformer model for our task
Transformer models like BERT are currently state-of-the-art on the vast majority of NLP tasks. The power of BERT mainly comes from two aspects:
Self-supervised pre-training on a big corpus of text — the model is pre-trained on the Wikipedia and BookCorpus datasets with the main objective of predicting randomly masked words in sentences.
Bidirectional self-attention mechanism, which allows the model to produce high-quality contextual word embeddings.
However, the vanilla BERT model is not best suited for our use case:
Its self-supervised pre-training strategy is mostly focused on producing high-quality contextual word embedding, but off-the-shelf sentence representations are not very good, as shown in this paper on SBERT, “Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks”.
It was pre-trained on English text only, whereas we wanted to support multilingual queries and episodes.
Therefore, after a few experiments, we chose as our base model the Universal Sentence Encoder CMLM model, as detailed in the paper “Universal Sentence Representation Learning with Conditional Masked Language Model”. It has the following advantages for us:
The newly introduced self-supervised objective Conditional Masked Language Modeling (CMLM) is designed to produce high-quality sentence embeddings directly.
The model is pre-trained on a huge multilingual corpora of more than 100 languages, and is publicly available on TFHub.
Preparing the data
Once we have this powerful pre-trained Transformer model, we need to fine-tune it on our target task of performing Natural Language Search on Spotify’s podcast episodes. To that end, we preprocess different types of data:
From our past search logs, we take successful podcast searches and create (query, episode) pairs. Those successes mostly come from previous queries and their returned results through Elasticsearch.
Also from our past search logs, we examined user sessions to find successful attempts at search queries after an initial search came up unsuccessful. We used those query reformulations to create (query_prior_to_successful_reformulation, episode) pairs.With this data source, we hope to capture in our training set more “semantic” (query, episode) pairs with no exact word matching between the query and the episode metadata.
To further extend and diversify our training set, we generate synthetic queries from popular episode titles and descriptions, inspired by the paper “Embedding-based Zero-shot Retrieval through Query Generation”. More specifically, we fine-tuned a BART transformer model on the MS MARCO dataset, and used it to generate (synthetic_query, episode)pairs.
Finally, a small curated set of “semantic” queries was manually written for popular episodes.
All types of preprocessed data are used for both training and evaluation, except for the curated dataset that is used for evaluation only. Moreover, when splitting the data, we make sure that the episodes in the evaluation set are not present in the training set (to be able to verify the generalization ability of our model to new content).
Training
We have our model and our data, so the next step is the training. We use the pre-trained Universal Sentence Encoder CMLM model as a starting point for both the query encoder and the episode encoder. After a few experiments, we chose a siamese network setting where the weights are shared between the two encoders. Cosine similarity is used as the similarity measure between a query vector and an episode vector.
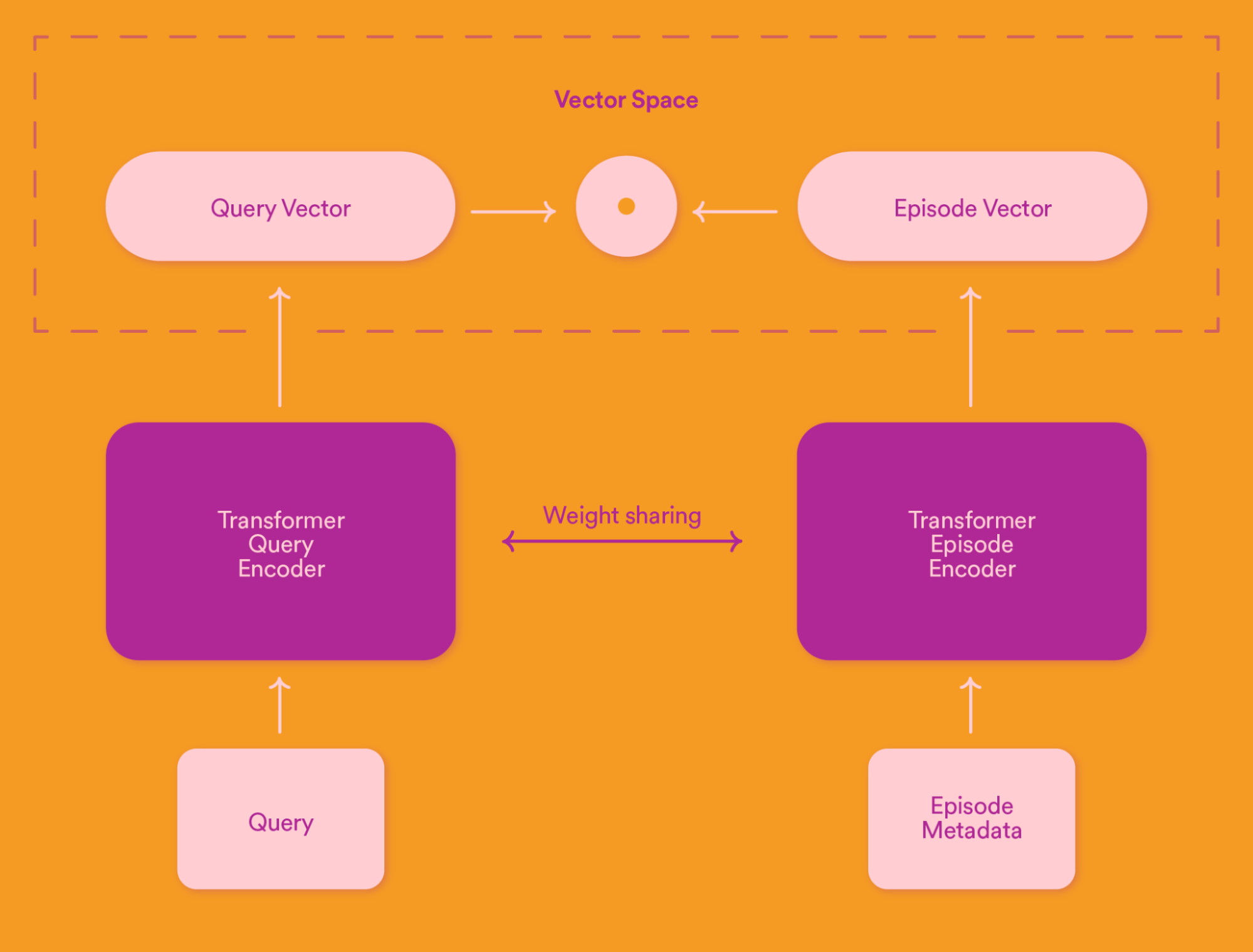
Model architecture: bi-encoder Transformer in a siamese setting.
In order to effectively train our model, we need both positive (query, episode) pairs and negative ones. However, we only mined positive pairs in our training data. How then can we generate negative pairs to teach the model when not to retrieve an episode given a query?
Inspired by multiple papers in the literature like “Dense Passage Retrieval for Open-Domain Question Answering (DPR)” and “Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook”, we used a technique called in-batch negatives to efficiently generate random negative pairs during training: for each (query, episode) positive pair within a training batch of size B, we take the episodes from the other pairs in the batch as negatives for the query of the positive pair. As a result, we’ll have B positive pairs and B2 – B negative pairs per batch. For computational efficiency, we encode the query and episode vectors for each training data positive pair once, and then compute the in-batch cosine similarity matrix from those vectors:

Cosine similarity matrix: q i (respectively e i ) represents the embedding of the i-th query (respectively episode) in a batch of size B .
In this matrix, the diagonal part corresponds to the cosine similarity of positive pairs, while the other values are cosine similarities of the negative pairs. From there, we can apply several losses to the matrix, like a Mean Squared Error (MSE) loss using the identity matrix as the label. In our latest iteration, we took a step further and used techniques like in-batch hard negative mining and margin loss to substantially improve our offline metrics.
Offline evaluation
In order to evaluate our models, we use two kinds of metrics:
In-batch metrics: Using in-batch negatives, we can efficiently compute metrics like Recall@1 and Mean Reciprocal Rank (MRR) at the batch level.
Full-retrieval setting metrics: In order to also evaluate our model in a more realistic setting with more candidates than in a batch, during training, we periodically compute the vectors of all episodes in our eval set and compute metrics like Recall@30 and MRR@30 using the queries from the same eval set. We also compute retrieval metrics on our curated dataset.
Integration with production
Now that we have our fine-tuned query encoder and episode encoder, we need to integrate them into our Search production workflow.
Offline indexing of episode vectors
Episode vectors are pre-computed for a large set of episodes using our episode encoder in an offline pipeline. Those vectors are then indexed in the Vespa search engine, leveraging its native support for ANN Search. ANN allows retrieval latency on tens of millions of indexed episodes to be acceptable while having a minimal impact on retrieval metrics.
Moreover, Vespa allows us to define a first-phase ranking function (that will be executed on each Vespa content node) to efficiently re-rank the top episodes retrieved by ANN using other features like episode popularity.
Online query encoding and retrieval
When a user types a query, the query vector is computed on the fly by leveraging Google Cloud Vertex AI where the query encoder is deployed. Our main reason for using Vertex AI is its support for GPU inference, as large Transformer models like ours are usually more cost-effective when running on GPU even for inference (this was confirmed by our load test experiments with a 6x cost reduction factor between T4 GPU and CPU). Once the query vector is computed, it is used to retrieve from Vespa the top 30 “semantic podcast episodes” (using our previously described ANN Search). A vector cache is also used to avoid computing the same query vectors too often.
There is no silver bullet in retrieval
Although Dense Retrieval / Natural Language Search has very interesting properties, it often fails to perform as well as traditional IR methods on exact term matching (and is also more expensive to run on all queries). That’s why we decided to make our Natural Language Search an additional source rather than just replace our other retrieval sources (including our Elasticsearch cluster).
In Search at Spotify, we have a final-stage reranking model that takes the top candidates from each retrieval source and performs the final ranking to be shown to the user. To allow this model to better rank semantic candidates, we added the (query, episode) cosine similarity value to its input features.
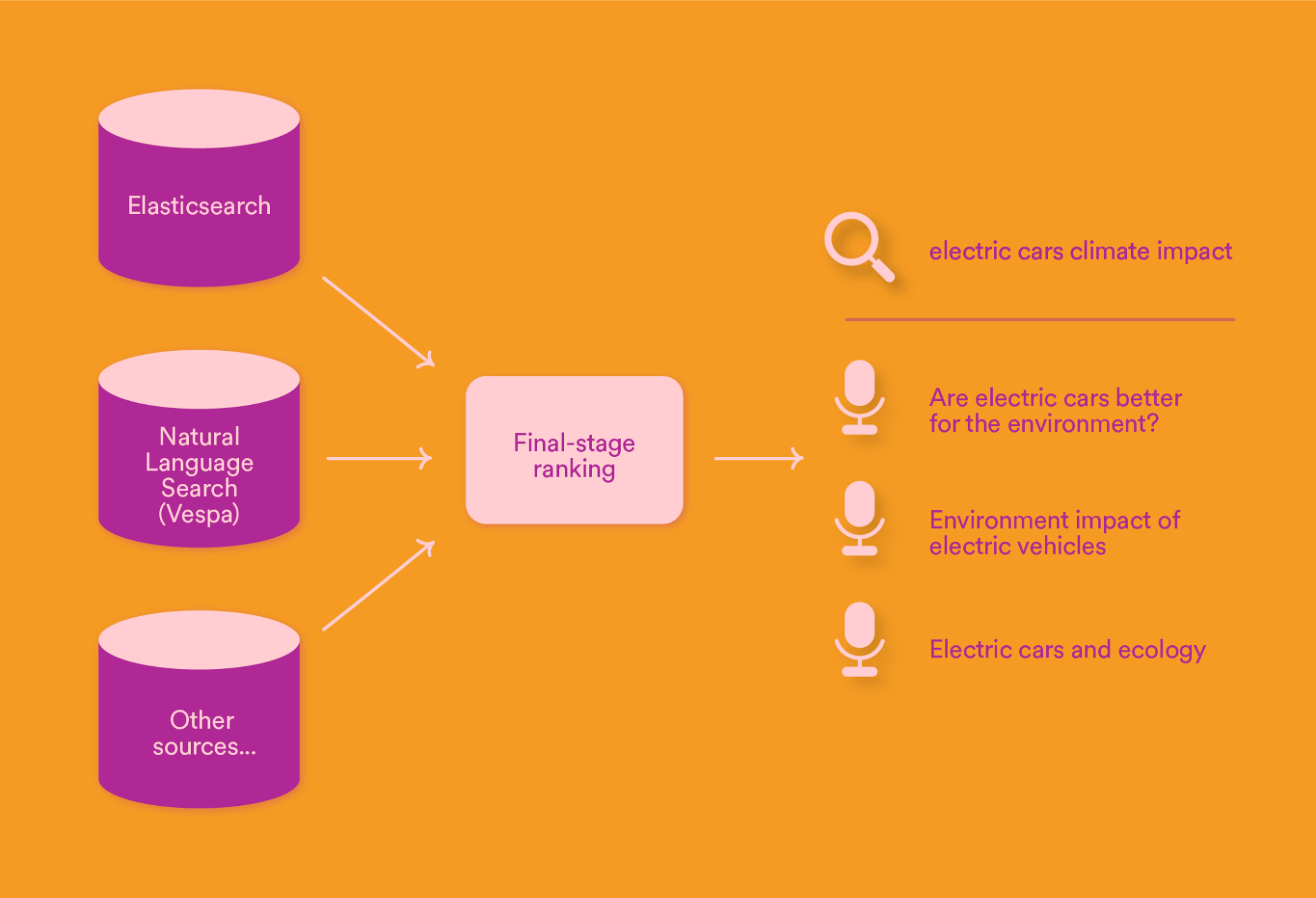
Multi-source retrieval and ranking.
Conclusion and future works
Using this multi-source retrieval and ranking architecture with Natural Language Search, we successfully launched an A/B test that resulted in a significant increase in podcast engagement. Our initial version of Natural Language Search has now been rolled out to most of our users, and new model improvements are already on their way.
Our team is excited about this successful first step, and we already have several ideas for future works ranging from model architecture improvements, better blending of dense and sparse retrieval, and increasing coverage. Stay tuned!
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
SHARE THIS ARTICLE