Load Testing for 2022 Wrapped

Wrapped is Spotify’s global annual year-end campaign that celebrates our listeners with a personalized review of their listening habits over the past year.
Last year, with more than 150 million unique engaged users across more than 111 markets, the Wrapped engineering team had the extraordinary challenge of supporting traffic across many regions and from different devices to ensure the Wrapped experience was a smooth one.
Each year, when Wrapped goes live, the Spotify team is faced with a “thundering herd problem”. Millions of people, all over the world and across all time zones, start watching their data stories on-platform, typically at the same time in the morning of the launch. And at that time, our infrastructure for supporting that volume is put to the test. To this end, we’ve leveraged our internal tools to stress test our system with the scale of traffic that we will experience, particularly on day one of launch.
Wrapped Backend Architecture
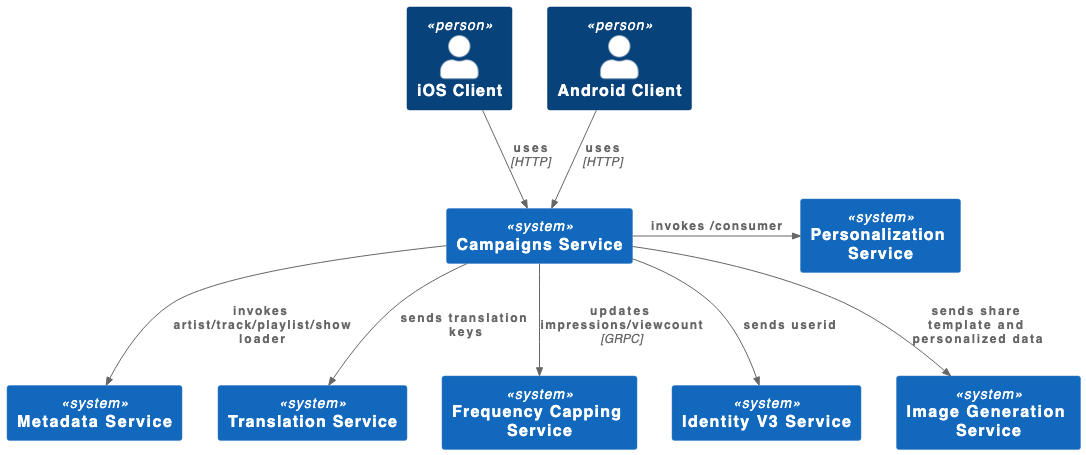
Our main backend service, called “campaigns service,” sends personalized and localized data to the mobile clients to deliver Wrapped to millions of users. In the first three to four hours, when the experience goes live, we see some of the most demanding traffic of the campaign, on the order of tens of millions of users. So we need to properly load test and stress test our system to make sure our service, and the upstream services that it depends on, can stand the load.
Enter “Moshpit”
Moshpit is Spotify’s internal Backstage plugin for load testing our backend services. The tool was initially developed as a Spotify Hack Week project, but it has since evolved into a robust load-testing tool that can send payloads to any internal Spotify service over multiple network protocols (HTTP and gRPC among them). As a part of the Backstage ecosystem, it seamlessly integrates with all backend services created and hosted on Backstage.
The load-testing tool works as a driver to send any kind of payload you can create in any format you wish. Spotify internally uses Protocol Buffers as our de facto messaging format, so Moshpit uses this format encoded in binary to mock real-life payloads to any service.
Moshpit is also configurable with any initial ramp-up time (say, 60 seconds), overall duration time (usually 5 to 12 minutes), latency between payloads, and a target requests-per-second for service to send payloads.
These settings are all tunable with a web UI and are typically very easy for the developer to use to drive payloads toward their service in an easy and configurable way.
Usually, the main challenge a developer faces with using Moshpit is sourcing the test payload to send to our service. The challenge lies in sourcing a sample set that is both diverse enough and actually representative of a live real-world load.
In this case, our payload structure is fairly simple, consisting of the Spotify user ID and the Accept-Language header, among other fields. To meet our requirements, we decided to use internal employee IDs for several reasons:
Some of our data pipelines for external users take longer to complete leading up to launch, but employees’ Wrapped data pulls are ready sooner in the development cycle for internal test sessions.
The smaller list of employee Spotify accounts is easier to collect and manage than a bigger and equally diverse set of external Spotify user accounts to test with.
Our thousands of employees are distributed across a wide range of countries and regions, with their unique and diverse listening data and language preferences are a good sample of end users.
Testing plan
Once we have a good sample of users across many different countries, the following is our general plan of attack:
Notify upstream owners.
The main backend service that serves the personalized, localized data uses several key upstream services, notably metadata service, translation service, image generation service, and personalization data service. All these are owned by separate squads within Spotify. Before blasting thousands of requests per second to those services and potentially setting off pager duty alerts, we need to give advance warning to each squad of our test plans so they can prepare.
Tweak our internal routing to remove employee flags for some upstream services.
In certain services, we can’t accurately load-test and simulate real-world conditions, because the employee flags in our request tell some of our backend services not to cache any data from the response. This causes extra latency that is typically not seen in our production load. For these reasons, we have to manually remove the employee flag in our requests to certain services.
Scale pods horizontally for each load-test session.
We need to provision enough pods for our services to scale, but also ensure that upstream services have enough pods.
Record each load-test session.
We look at our load-test sessions on Grafana and make sure latency, packet drop rates, and horizontal pod autoscaling are appropriate and our CPU/memory resources are adequate as we vary our test loads across the U.S., E.U., and Asia regions. We test across different data-center regions and scale up to the expected production traffic. We also monitor and check upstream services to make sure they’re OK with the load.
Scale up load-testing leading to launch for expected production traffic.
For this year, roughly on the order of tens of thousands requests per second for the U.S. , E.U. and Asia were expected for our main service. Recording all of our runs, the cpu/memory utilization, and how many replicas we had scaled up to in each test help other developers who jump in on the effort to know what was done and what still needs to be done.
What we’ve learned
Implementing a thorough load-test plan is only but a critical part of ensuring that the launch of a massive campaign like Spotify Wrapped is successful. Here are some of the key ingredients that we emphasize for success:
Ensure you test with a diverse variety of payloads that represent real-world load
In our case, this means a diverse set of users from many different countries and languages, as well as fetching unique top artists, tracks, playlists, and podcasts that will really stress test the backend and the data pipeline for obscure or irregular data that our code can’t process.
Provision not only for your service but also for upstream services when you scale your tests
This includes rate-limiters and classic Kubernetes scale-up resources (resource quotas, horizontal pod autoscaling configs, availability of machines). Coordination needs to be emphasized when scaling up tests that have upstream effects.
Think worldwide
You need to test multiple regions and make sure all your components are scaled up across the world (object storage, database, caches, upstream services).
Test all endpoints and regions
We have a multitude of endpoints in addition to our main service that serves the personalized data for the data stories. It’s important to test all of them thoroughly, and sometimes in parallel runs and across multiple regions, if possible. This ensures that the resources you provisioned scale up across all endpoints and in all regions simultaneously.
Conclusion
In the end, 2022 Wrapped was a huge success, with millions of users being able to enjoy their personalized Wrapped experience without any significant technical issues. This is no small feat with a campaign of this size and scope, but with tight coordination between all backend, data, and client engineering teams, we were able to make sure we had enough elastic capacity, warm-up time, and careful monitoring in place to withstand the anticipated rush of our fans.
SHARE THIS ARTICLE



