October 23, 2017
Big Data Processing at Spotify: The Road to Scio (Part 2)
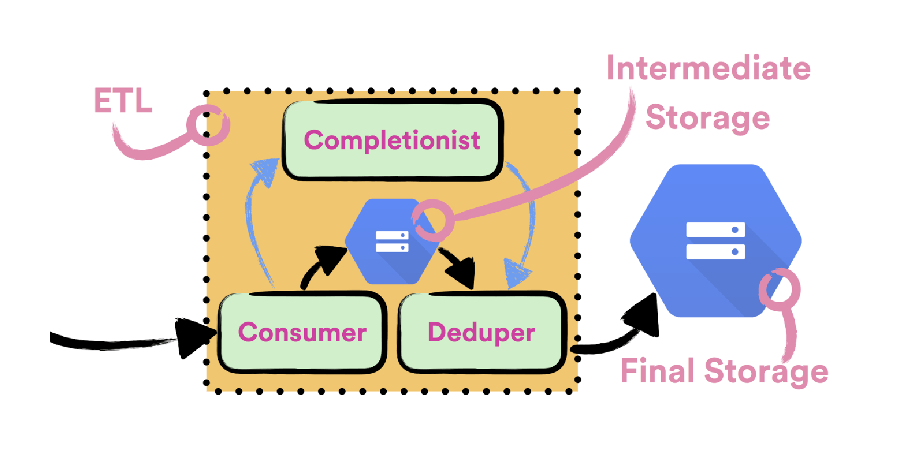
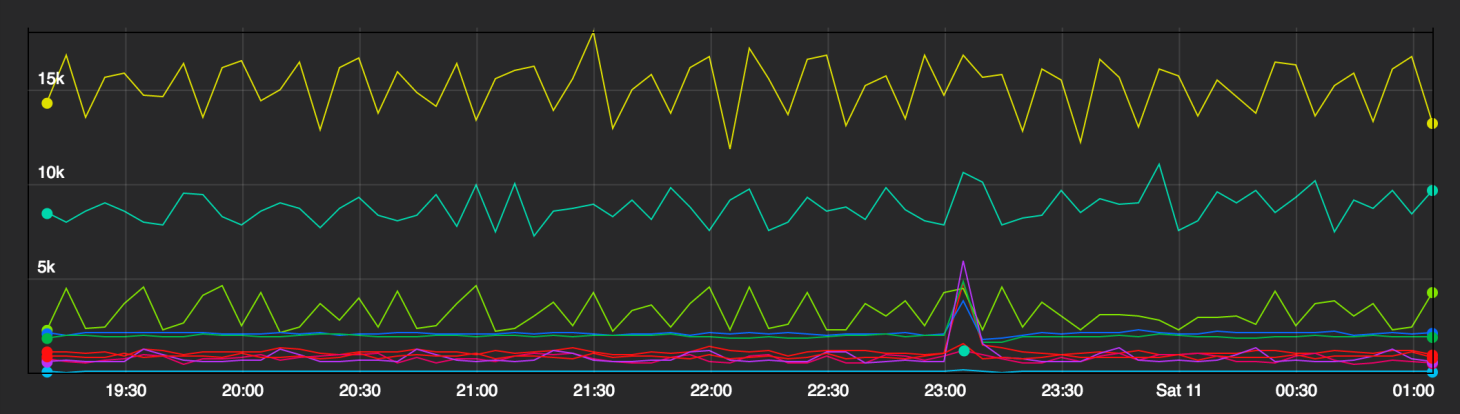
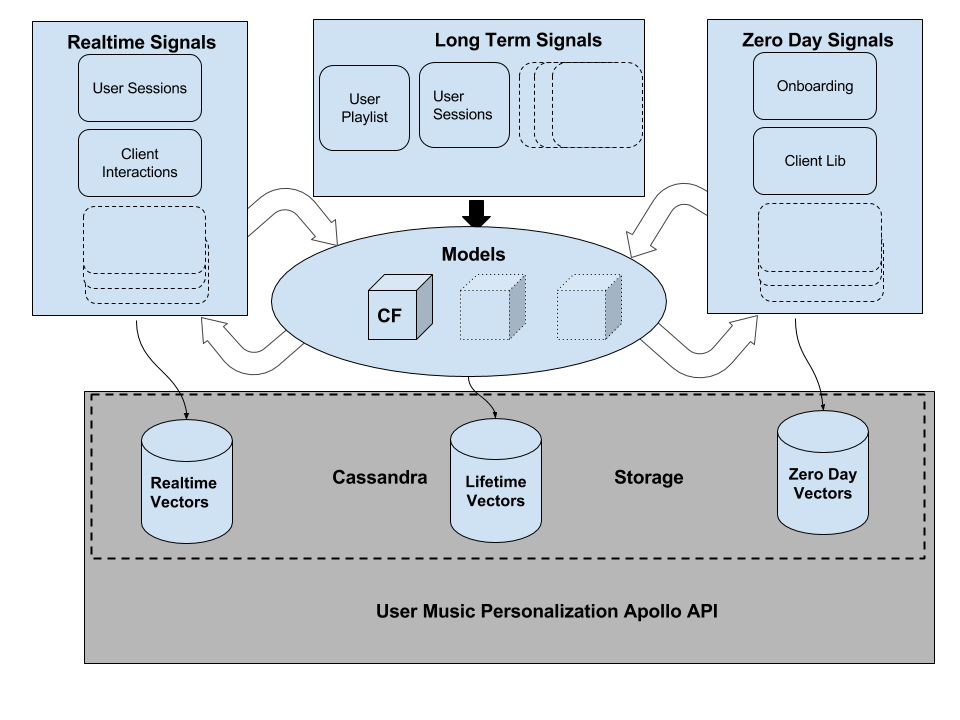
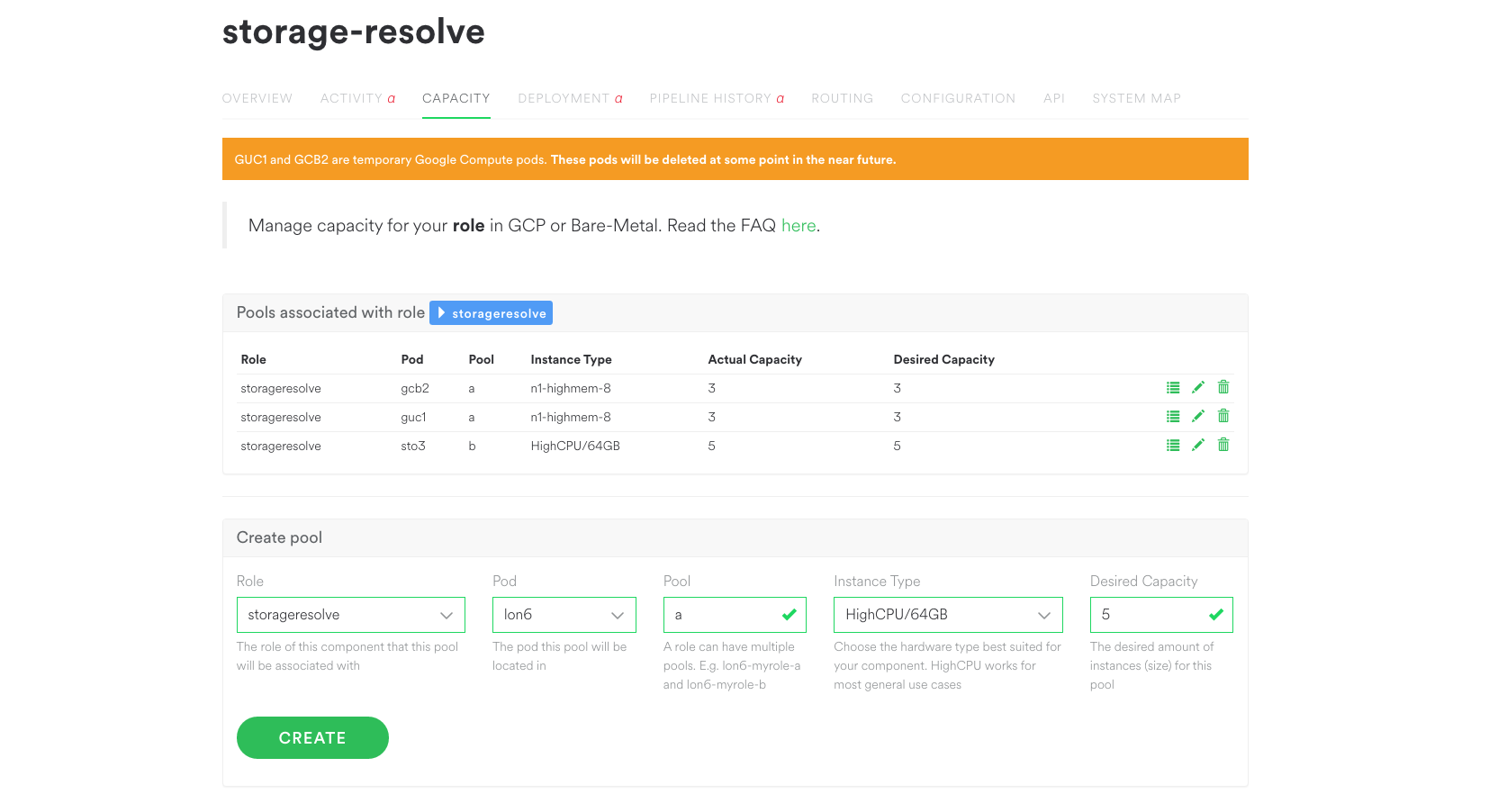
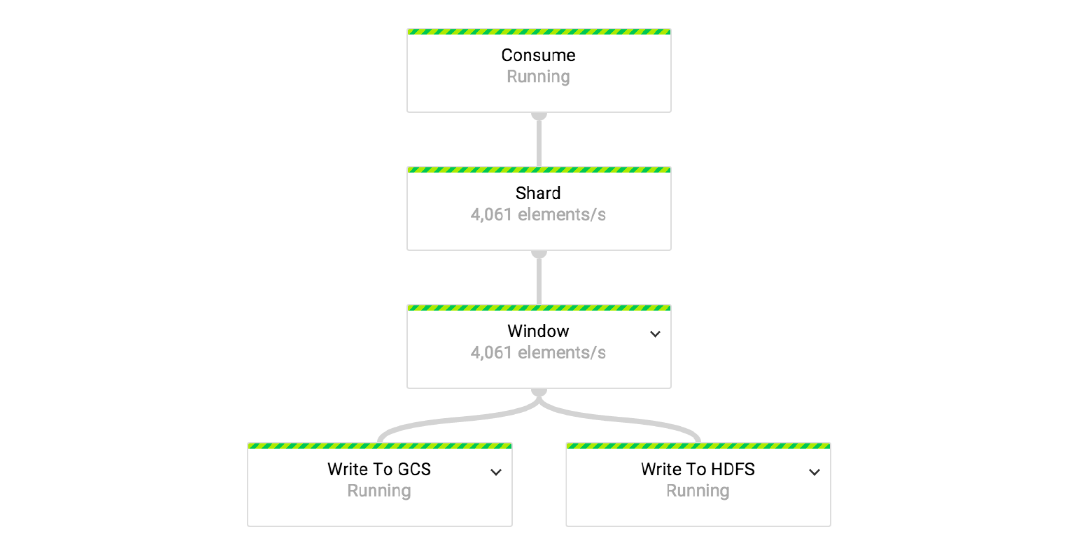
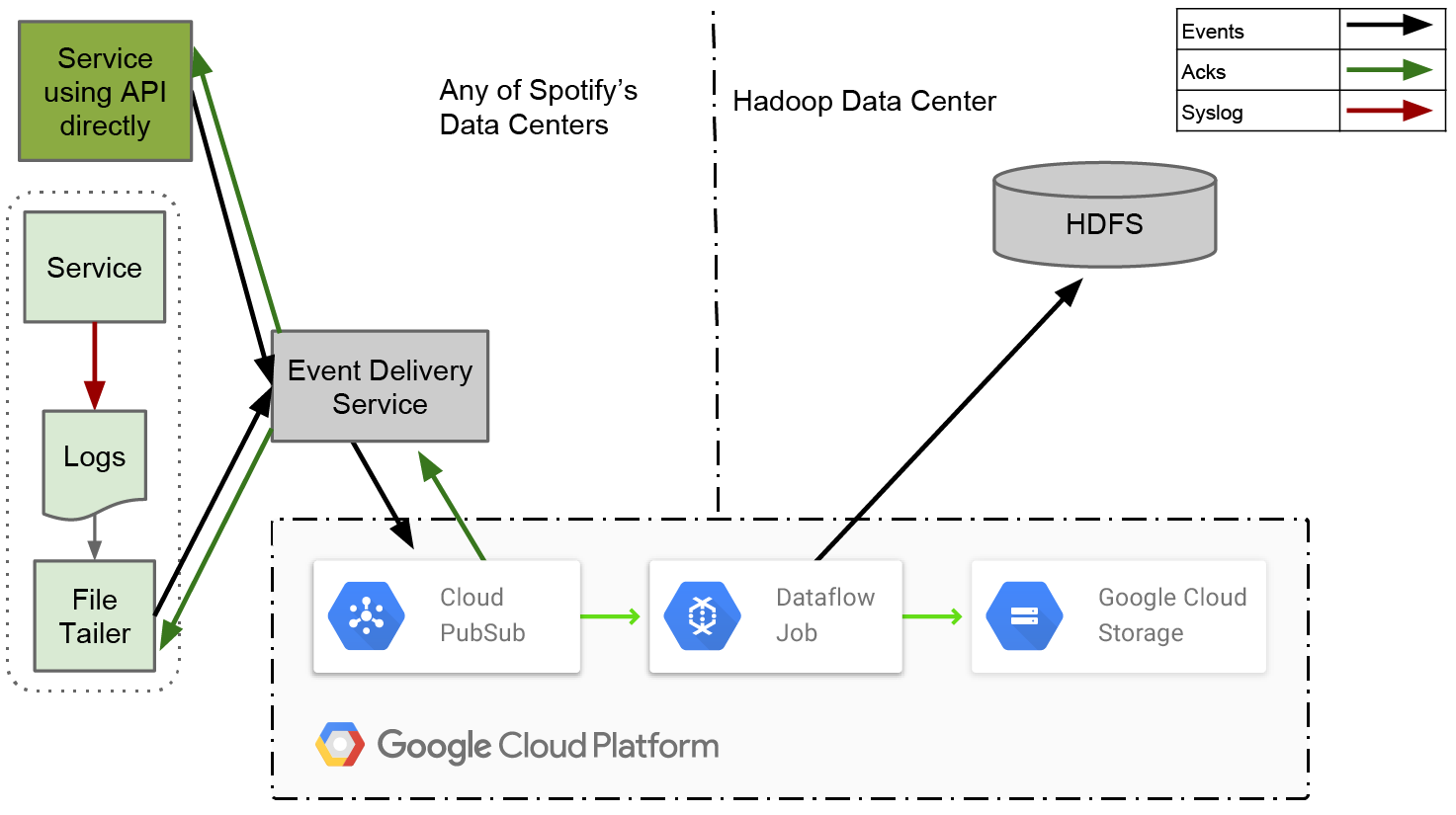
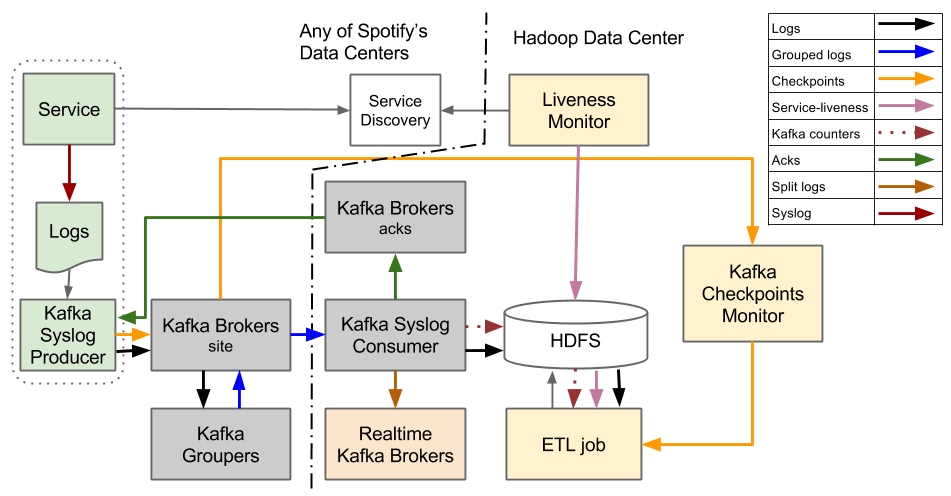
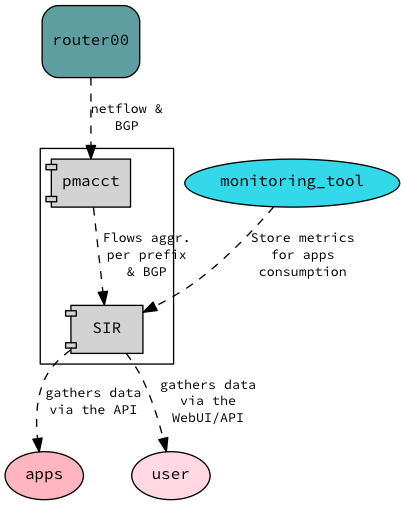
In this part we’ll take a closer look at Scio, including basic concepts, its unique features, and concrete use cases here at Spotify [...]
Published by Neville Li