Solving MapReduce Performance Problems With Sharded Joins
Sometimes the answer to a sluggish data pipeline isn’t more power in the Hadoop cluster, but a shift in technique. We hit one of these moments recently at Spotify. One of our critical ad analysis pipelines had issues. First it was slow. Then a few days later it was dead, unrunnable at less than 20GB memory/reducer.
We traced the problem back to a single bottleneck: one expensive join and a handful of overloaded reducers. We solved things by switching up our join strategy, in the process cutting memory usage by over 75%. Here’s how.
Reducer Overload
At one stage in our pipeline, we performed a large join between raw ad impression logs and a smaller set of ad metadata. Some of our ads have far more impressions than others; the nature of this join was such that several reducers were processing an unreasonable number of rows while others in the cluster sat idle.
This kind of bottleneck tends to happen with “skewed” data, where a handful of keys make up a disproportionate number of logs. A standard join maps all logs with the same key to the same reducer. If too many logs hit a single reducer, the reducer chokes.
So the problem was really the data, not the cluster.
We needed a solution that would distribute the join across reducers to lighten the load. And it had to work in Apache Crunch, our platform for writing, testing, and running MapReduce pipelines on Hadoop.
Enter the Sharded Join
As we shifted focus from the initial memory problem to the underlying data problem, we settled on a simple solution: to “shard” the join. A sharded join aims to distribute the load of a single expensive join across the cluster so no one reducer gets overloaded.
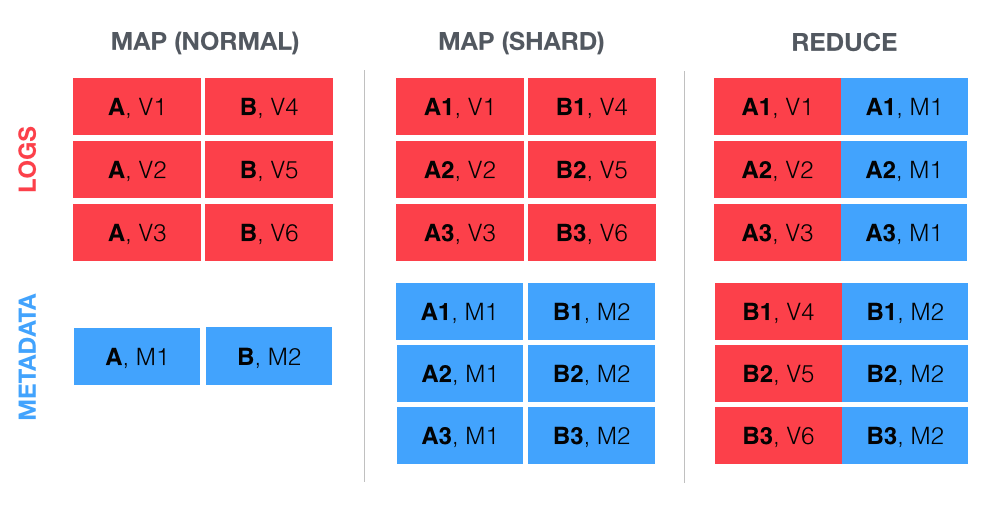
Consider a join between a larger dataset Logs (with multiple values, or multiple logs, per key) and a smaller metadata set Metadata (which has just one value, or one log, per key). A sharded join splits up the key space by:
In Logs: Dividing key/value pairs into groups by combining each log’s key with some random integer. The output of this looks like ([A1, V1], [A2, V2], [A3, V3]), where “A1” represents a combination of key “A” and a random number and “V1” represents an unchanged log value. All values are unique here; we’re dividing into groups.
In Metadata: Replicating key/value pairs by creating multiple copies of each unique key, one for each possible value of the random integer. Output looks like ([A1, M1], [A2, M1], [A3, M1]).

While this setup increases the number of total mapped logs, the average reducer load is decreased. In the example above, the normal map would have sent three logs and a metadata row to each of two reduce tasks; the sharded map breaks up the job by sending just one log and one metadata row to each of six separate tasks.
This reduces memory requirements per reducer and removes the bottleneck.
How to do this in Apache Crunch?
If you’re fancy and use Crunch, you’ve got a nice built-in sharded join strategy waiting for you. Use of that strategy would look like this:
PTable one = ;
PTable two = ;
JoinStrategy strategy = new ShardedJoinStrategy(num_shards);
PTable> joined = strategy.join(one, two, JoinType.INNER_JOIN);…and our first step was to implement this sharded join from the standard Apache Crunch library. However, we soon hit an underlying bug in the Crunch library affecting our specific implementation of the sharded join. Unable to use the built-in implementation, we fell back to constructing the join ourselves.
This turned out to be a good opportunity to review basics. When all else fails…
Do it From Scratch
If you’re stuck using vanilla MapReduce or are unable to use the built-in sharded join, here’s the DIY approach. Code below is in Crunch, but the pattern holds regardless of what you’re using.
First we split the key space from the large dataset into shards using a random integer. In Crunch, we can do this with a standard MapFn, which is a specialized DoFn for the case of emitting one value per input record (while a DoFn is the base abstract class for all data processing functions).
We store the output in a built-in Crunch collection called a PTable, which consists of a map. Here our key is a Pair.
PTable, Value> shardedValues = largeDataset.parallelDo(
new MapFn, Pair, Value>>() {
final private Random rand = new Random();
@Override
public Pair, Value> map(
Pair largeDatasetPair) {
int randnum = rand.nextInt(NUM_SHARDS) + 1;
return Pair.of(Pair.of(largeDatasetPair.first(), randnum), largeDatasetPair.second());
}
} , tableOf(pairs(strings(), ints()), specifics(Value.class)));When determining the number of shards to use, think about your current and ideal reducer memory usage. Two shards will approximately halve the number of logs joined per reducer and affect memory accordingly. The cost of sharding is an increase in total reduce tasks and an increase in mapped metadata logs.
Then we replicate metadata values using a DoFn and an Emitter, allowing us to output multiple values per log:
PTable, MetadataValue> replicatedValues = metadataSet.parallelDo(
new DoFn, Pair, MetadataValue>>() {
@Override
public void process(Pair metadataSetPair,
Emitter, MetadataValue>> pairEmitter) {
for (int i = 1; i <= NUM_SHARDS; ++i) {
pairEmitter.emit(Pair.of(Pair.of(metadataSetPair.first(), i), metadataSetPair.second()));
}
}
}, tableOf(pairs(strings(), ints()), specifics(MetadataValue.class)));Finally, we join and filter:
JoinStrategy strategy = new DefaultJoinStrategy();
PTable> joined = strategy.join(one, two, JoinType.LEFT_JOIN)
.whateverElseYouNeedToDo(); // Remove the sharded int values from keys hereThis splits up the ad logs, joins them in small batches, then restores them to their initial state.
The sharded join can work wonders on reducer load when combining a large, skewed dataset with a smaller dataset. Our shift in focus from the initial memory overload to the data bottleneck allowed us to settle on this simple solution and get the job back in line. Pipeline revived.
SHARE THIS ARTICLE



