Tag archive: Apache Crunch
Jan 9, 2015
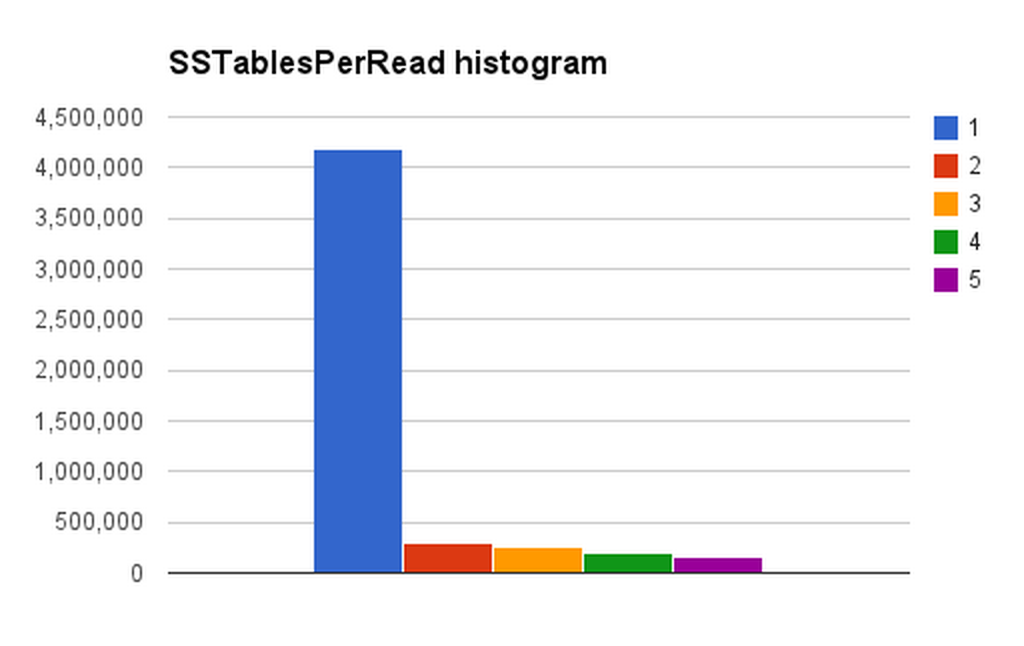
Personalization at Spotify using Cassandra
At Spotify we have have over who have access to a vast music catalog of over 30 million songs. Our users...
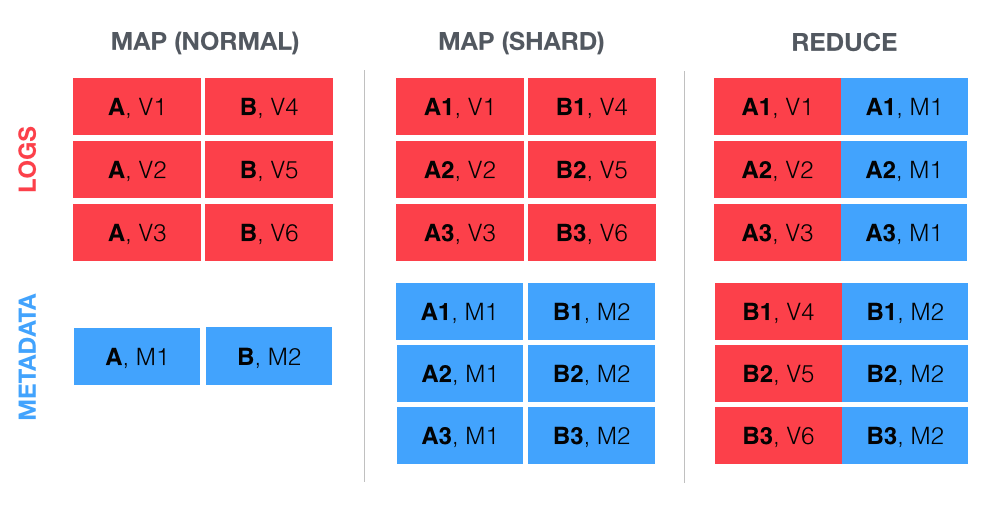
Dec 19, 2014
Solving MapReduce Performance Problems With Sharded Joins
Sometimes the answer to a sluggish data pipeline isn’t more power in the Hadoop cluster, but a shift in...

Nov 27, 2014
Data Processing with Apache Crunch at Spotify
All of our lovely Spotify users generate many terabytes of data every day. All the songs that are listened...