Changing the Wheels on a Moving Bus — Spotify’s Event Delivery Migration

At Spotify, data rules all. We log a variety of data, from listening history, to results of A/B testing, to page load times so we can analyze and improve the Spotify service. We instrument and log data across every surface that is running Spotify code through a system called the Event Delivery Infrastructure (EDI). Throughout this blog post we make a distinction between the internal users of the EDI, who are Spotify Engineers, Data Scientists, PMs and squads, and end users, who use Spotify as a service and audio platform.
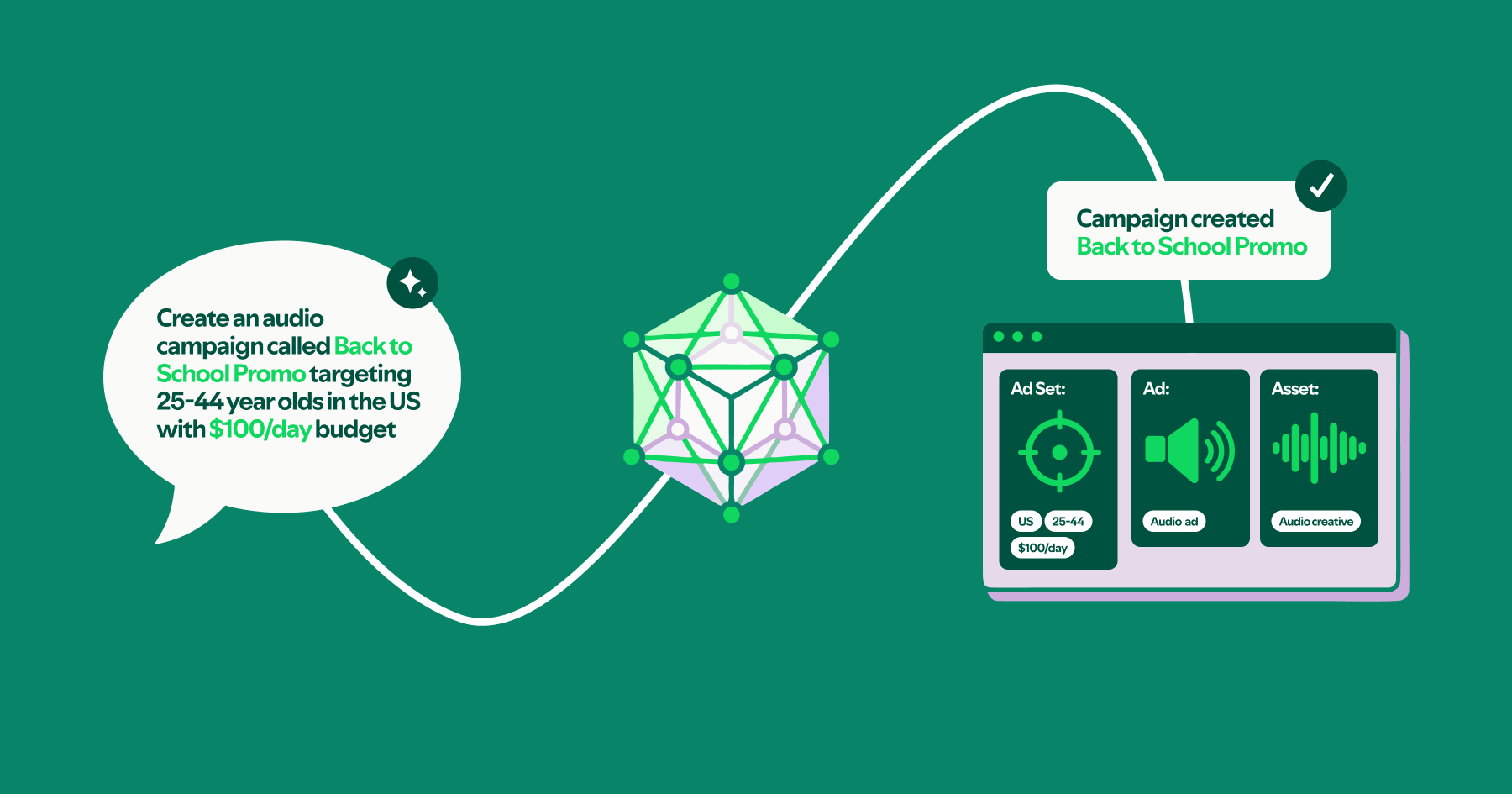
In 2016, we redesigned the EDI in Google Cloud Platform (GCP) when Spotify migrated to the cloud, and we documented the journey in three blog posts (Part I, Part II, and Part III). Not everything went as planned, and we wrote about our learnings from operating our cloud-native EDI in Part IV. Our design was optimized to make it quick and easy for internal developers to instrument and log the data they needed. We then extended it to adapt to the General Data Protection Regulation (GDPR), we introduced streaming event delivery in addition to batch, and we brought BigQuery to our data community. We also improved operational stability and the quality of life of our on-call engineers. The peak traffic increased from 1.5M events per second to nearly 8M, and we were ready for that massive scale increase. This increased the total volume of data which we ingested daily to nearly 70TB! (Figure 1).
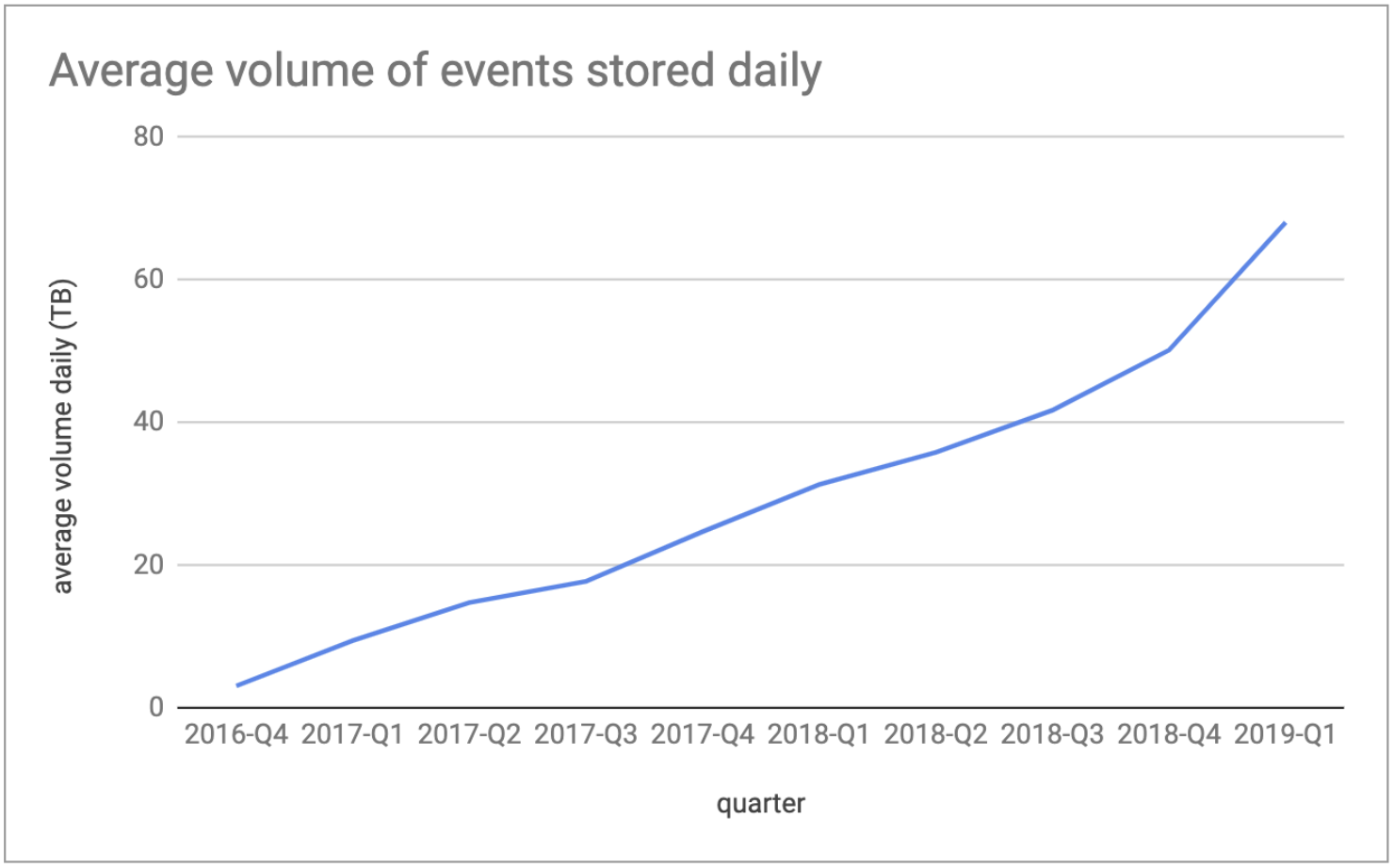
Figure 1: Average total volume (TB) of events stored daily by our ETL process (after compression).
However, with that high adoption and traffic increase we discovered some bottlenecks. Our internal users had feature requests and needed more from the system. Now our incomplete and low-quality data was degrading the productivity of the Spotify data community. Whoops!
What was hurting us?
When we designed and built the initial EDI, our team had the mission statement to “provide infrastructure for teams at Spotify to reliably collect data, and make it available, safely and efficiently.” The use cases we focused on were well supported, such as music streaming and application monitoring. As other use cases started to appear, the assumptions we made when building the system had to be revisited. During three years of operating and scaling the existing EDI, we gathered a lot of feedback from our internal users and learned a lot about our limitations.
Data loss
Most events generated on mobile clients were sent in a fire-and-forget fashion. This might seem surprising, but because end users can enjoy Spotify while offline, there are some complications around deduplication of data that is re-sent. For example, if we detect that we are missing a data point, we don’t necessarily know if it is actually lost, or just has not arrived yet due to the user being offline, in a tunnel, or maybe having a flaky network connection. This leads to a small percentage of data loss for nearly all the data we collect, which is not acceptable for some types of data. Furthermore, this problem is compounded for datasets generated from a combination of multiple event types in order to “connect the dots” in user journeys where, for example, a single lost event can compromise the whole journey. While we had some specific client code and algorithms to reliably deliver business-critical data exactly once, it was not done in a way that we could extend to all 600+ event types that we had at that time.
Control plane UX
The workflow for a customer to progress from “instrumentation to insights” took far too long. Under normal circumstances it would take a customer a week to go through this workflow and get their data. One issue was that multiple components in the EDI had to be schema aware. For example, the receiver service, which is the entry point of the infrastructure, uses the schemas to validate that incoming data is well formed. Due to some tech debt, it took a few hours to propagate the schemas for this validation. This was an eternity in terms of iteration time. Since this process was so painful, some teams tried to instrument their features or services, but then gave up. Some other teams would shoehorn their data into existing data events. This led to gaps in what was instrumented, and a data-quality nightmare.
Backwards compatible? Or stuck in the past?
For strategic reasons, it was critical, in 2016, that we build the EDI in GCP and migrate over as quickly as possible. A key decision we took to make this happen was to stay backwards compatible to minimize the migration time. That meant we had to stick with some historical design choices that we would not have if we had built this EDI from scratch. For example:
Tab-separated values (TSV): All data events were sent as TSV strings. The schemas were parsed and converted to Avro with a Python library created in 2007. The schema-aware tooling for parsing the TSV data was the main cause for the painful control plane UX mentioned earlier.
Stateful services: Data events were first stored on disk and then forwarded to the EDI. This made us resilient to crashes, but made us vulnerable to data loss if a machine was taken down. Furthermore, Spotify could not take advantage of auto-scaling mechanisms or Kubernetes (without difficult workarounds) because the EDI made our service ecosystem stateful.
Legacy perimeter: Since data events were forwarded from disk to our EDI, all events triggered by Spotify clients needed to be emitted from our perimeter servers. These servers had to keep events on disk and were tightly coupled to our legacy logging mechanism. This caused some pain to perimeter administrators and hindered architectural innovations. Besides the additional complexity in the perimeter, the shared ownership of different teams with different goals caused alignment problems.
The situation
We had hundreds of services sending events through a legacy EDI by logging data to disk. After being ingested by the infrastructure, events were consumed by hundreds of downstream data pipelines to produce derivative datasets (Figure 2). Our goal was to build a platform that takes advantage of the modern landscape in the cloud while also enabling legacy event types to be migrated easily. The workflow to create new events should be frictionless, while still following our data governance principles and applicable privacy laws.
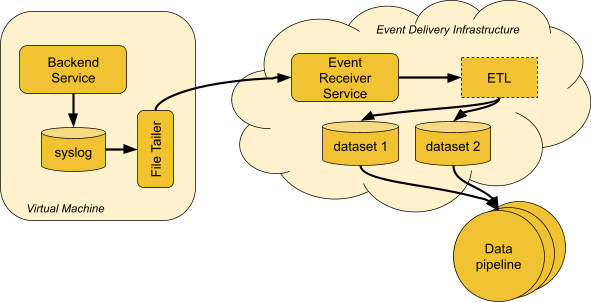
Figure 2: Events produced by our internal services go through the legacy EDI and are consumed by hundreds of data pipelines.
Transitioning event logging to a new infrastructure would need to take into consideration the long tail that mobile app updates have. A new version of our mobile apps takes several months to gain adoption from a high percentage of Spotify end users. We knew that we would have traffic coming to both the old and new EDIs for quite some time. Moreover, events emitted from embedded devices, such as TVs and speakers, would need special treatment as some of these devices are unlikely to ever be upgraded. We call this challenge “The Long Tail Problem”.
The strategy
We partially solved “The Long Tail Problem” by designing a data transformation pipeline that reads events from legacy clients, converts them, and feeds them from the legacy EDI into the new infrastructure (Figure 3). Since we were breaking backwards compatibility, we took the opportunity to update our data model. The transformation to the new data model would not have all the necessary information available, so missing or inaccurate fields were expected occasionally. But since this transformation only applied to legacy clients, it would decrease as end users upgraded to the latest version of Spotify. This traffic would become negligible, eventually.
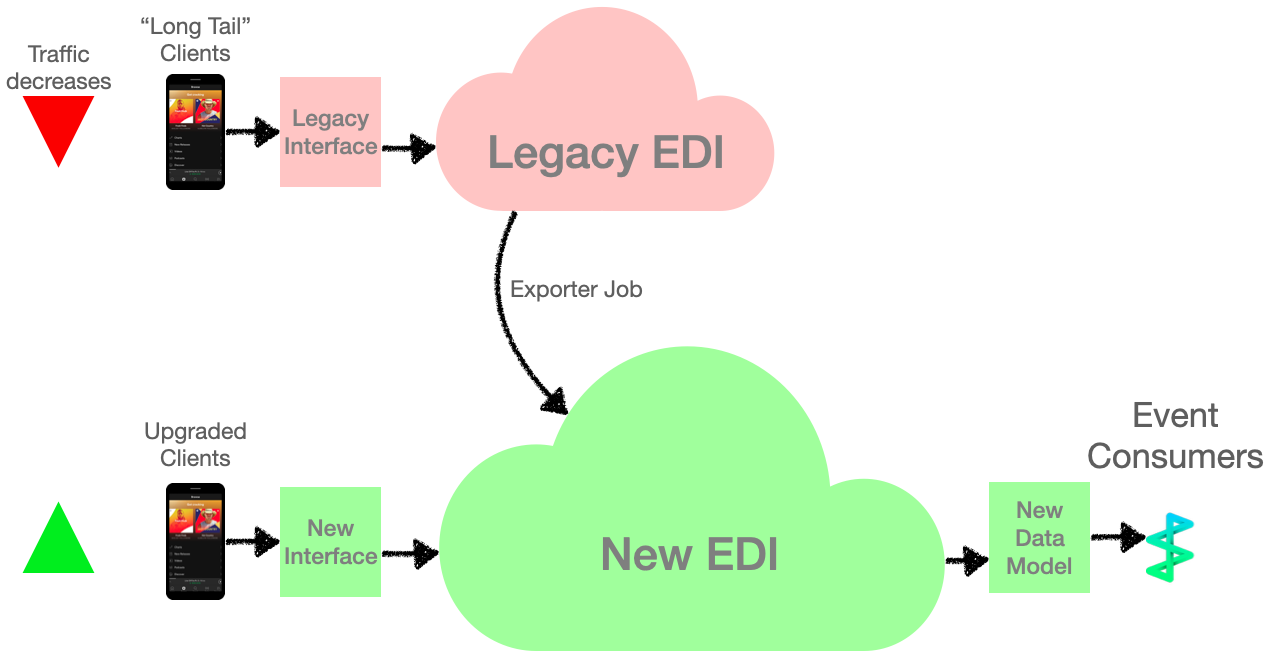
Figure 3: To handle clients which had not yet upgraded to the latest version, we implemented a job to export legacy data to the new EDI and transform it to our new data model.
We gave data producers two options to adopt the new EDI: either redesign their instrumentation using the new data model, or stick with what they have and turn on exporting data from the legacy EDI to the new EDI. After producers onboarded, event consumers would migrate to read data from the new EDI. If producers and consumers agree to use the exporter, they would first need to update any downstream pipelines to read from the new infrastructure before making client-side changes.
Get in production with real use cases ASAP
In order to validate our decisions, we had to find early adopters to start producing events with the new infrastructure. We presented the advantages and explained the limitations of our alpha product to potential interested teams. It was important to be able to experiment, break, and fix issues fast and safely without worrying about affecting critical production systems or data. Setting expectations with our internal users was important so we could make breaking changes when our assumptions were wrong.
Next, we found at least one real use case to migrate. We were looking for something specific, since different event types have different levels of importance, timeliness requirements, and downstream dependencies. We reached out to event owners to understand how their data was being used and how we could help them migrate.
Given a set of eligible event types, we identified use cases that were satisfied by the limited features we had built so far. Learning which features our internal users were missing also helped prioritize our roadmap. The more features we added to the new EDI, the more event types we could onboard. We periodically revisited our design decisions and assumptions in order to identify potential problems in the new infrastructure as quickly as possible.
Once we had a prototype that was working with real production traffic, we solidified the interfaces and data model and helped the alpha internal users adapt to the changes (Figure 4). This enabled us to decouple the significant work of migrating the 600+ event types which were running on the legacy infrastructure, and actually building the new EDI behind the abstractions.

Figure 4: New interfaces for the prototype infrastructure, so we could concurrently migrate internal users to the new Event Delivery Infrastructure while building it.
Just-in-time optimizations
Prematurely optimizing is generally a bad idea without motivating metrics. We always want to be as efficient as possible, but we had to prioritize and make trade-offs. Part of the challenge was to find a good balance between the desired efficiency of our infrastructure and the features we absolutely needed to release in order to accomplish our goals.
We learned from the first EDI that we needed to design for our targeted service availability from the start. Since transactional data collection was not required, there was no need for 100% delivery. We instead had to determine what level of service availability was acceptable and understand the trade-offs associated with that.
The design changes and decisions
We have two main interfaces to the EDI. The control plane is the starting point where internal users declare their events, design their schemas, and bind them to specific SDKs. The data plane receives events sent by those SDKs, divides them by event type, and makes them available as batch datasets or data-streaming topics. The events go through several other components that deduplicate, translate to our well-designed data model, and pseudonymize personal information. The output data is reliably stored for Spotify’s data community to consume and build data pipelines. Due to the evolving needs of internal users, as well as operational overhead and scalability concerns, we needed to make changes between the old and new infrastructure.
Client re-sends and new deduplication
In order to reduce event loss and improve reliability, we implemented client resends. Due to connection stability and offline mode, these resends may happen immediately, within a few minutes, or maybe several days later. They may never happen! It’s actually impossible to tell if an event has been lost in transport, or if a user has used Spotify and then dropped their phone in the ocean, causing data loss. The combination of resend strategies and flaky network connections complicates things and introduces duplicate events.
In the old infrastructure, we only deduplicate events within a small window of hours. However, due to the significant increase of duplicates, we hit some bottlenecks and decided to redesign the job. The biggest changes in the new job are the introduction of event message identifiers, and the adoption of Google’s Dataflow processing service instead of Hadoop. The event message identifiers were used to generate lookup indices and remove duplicates. This new strategy allowed us to look back across multiple weeks.
Receiver service — offline to online
The legacy EDI used files on disk to store events before they were sent to a receiver service. Spotify’s access point or other backend services would have their own availability guarantees, and we would read the data from disk eventually. In the new EDI, our receiver service needs its own availability guarantees, which was a paradigm shift in our infrastructure and for our team as SREs. Furthermore, those files on disk were a blocker for Spotify to leverage auto-scaling fleets.
In the new EDI, we have the receiver service as a highly available API used by SDKs to send events. In case of a receiver service outage, events would be temporarily stored on clients and, eventually, re-sent according to a predefined retry policy.
Managed Dataflow
We wanted the new EDI to leverage cloud-managed services as much as possible. By rebuilding the architecture to run in the cloud, we can offload management responsibilities to Google, and our team can focus on providing additional value.
When building the legacy EDI, we needed to migrate a heavy Hadoop job from our on-premise cluster to the cloud. The easiest way was to run the same job on Google’s managed Hadoop solution, Dataproc, so that’s what we did. In the new EDI, the new implementation of that job uses Scio (Scala API for Apache Beam) and runs on Google’s Dataflow instead. We considered Spark or Flink, but those had to run over Hadoop, which goes against our strategy to save us operational burden and cost.
By using Dataflow, we no longer needed to keep long-lived Hadoop clusters to execute our jobs. These clusters had to be big enough to process the largest job without issues, and were overkill for almost everything else. Maintaining these clusters was incredibly expensive. Conversely, Dataflow recycles clusters for every job and supports auto-scaling, allowing us to use and pay only for the resources we need.
Wrap-up
Once we decided to redesign our EDI, we evaluated new technologies and adopted new paradigms available to us in the cloud. We had been operating our old infrastructure for years, and that helped us to understand the main pain points and fragilities. We made decisions based on the technical direction of the company, the industry state of the art, and the known scalability issues with existing components.
We started by first designing new components for the new EDI, which we hacked together into a proof of concept and quickly evolved to a more robust prototype that could be used in production. Shipping as soon as possible was critical to validate the infrastructure end to end and catch issues fast. Having the internal users onboarded early was an important forcing function to keep quality and operational maturity high. Next, we solidified the interfaces to the prototype infrastructure and scaled up traffic by onboarding many noncritical event types. With the interfaces stable, we could improve or change out the internals without friction. This approach decoupled the mass migration from actually rebuilding the infrastructure and reduced wall-clock project time significantly.
As we neared the end of the migration, we had thrown out nearly all the old, obsolete infrastructure in favor of the state of the art. We successfully changed the wheels of the moving bus, and gave Spotify’s data community a smooth ride.
SHARE THIS ARTICLE