A Look Behind Blend: The Personalized Playlist for You…and You

What does it take to go from an idea for a new playlist, to shipping that playlist to Spotify users all around the world? From inception, to prototyping, to QAing, and finally shipping, releasing a new playlist at Spotify is a long process full of new learnings every time.
We recently launched a new playlist initiative, Blend, where any user can invite any user to generate a playlist wherein the two users’ tastes are combined into one shared playlist. Prior to Blend, the team worked on similar products, Family Mix and Duo Mix. These products create shared playlists for users on the same Family or Duo plan. The products were well received, so we decided to expand this product line, creating a version of opt-in, automatic, shared, personalized playlists that could work for any two users.
Anytime we want to make a new playlist at Spotify, we’re aiming to do something different that we haven’t been able to accomplish before. This means we can’t always lean on our past experiences, and often encounter new challenges that require new solutions. With Blend in particular, we were taking concepts from Family Mix and Duo Mix, and expanding them to a much larger user group. A major complication we saw here was the increase of scale in the number of users we had to deal with. We dealt with unique challenges both in the content creation process, and in the invitation flow, to create a Blend.
Most playlists are composed of a number of attributes and characteristics. For example, with Discover Weekly, our main attribute is discovery. For Daily Mix, our attributes are familiarity and coherency. When we are working with multiple users, however, we have the challenge of taking more attributes into account. Is the playlist:
Relevant: Does the track we’re selecting for that user reflect their taste? Or is it just a song they accidentally listened to once?
This is especially important for track attribution — if we put a user’s profile image next to a song, we need to make sure that this specific user would agree the song listed is representative of their taste.
Coherent: Does the playlist have flow, or do the tracks feel completely random and unrelated to each other?
Equal: Are both users in the Blend represented equally?
Democratic: Does music that both users like rise to the top?
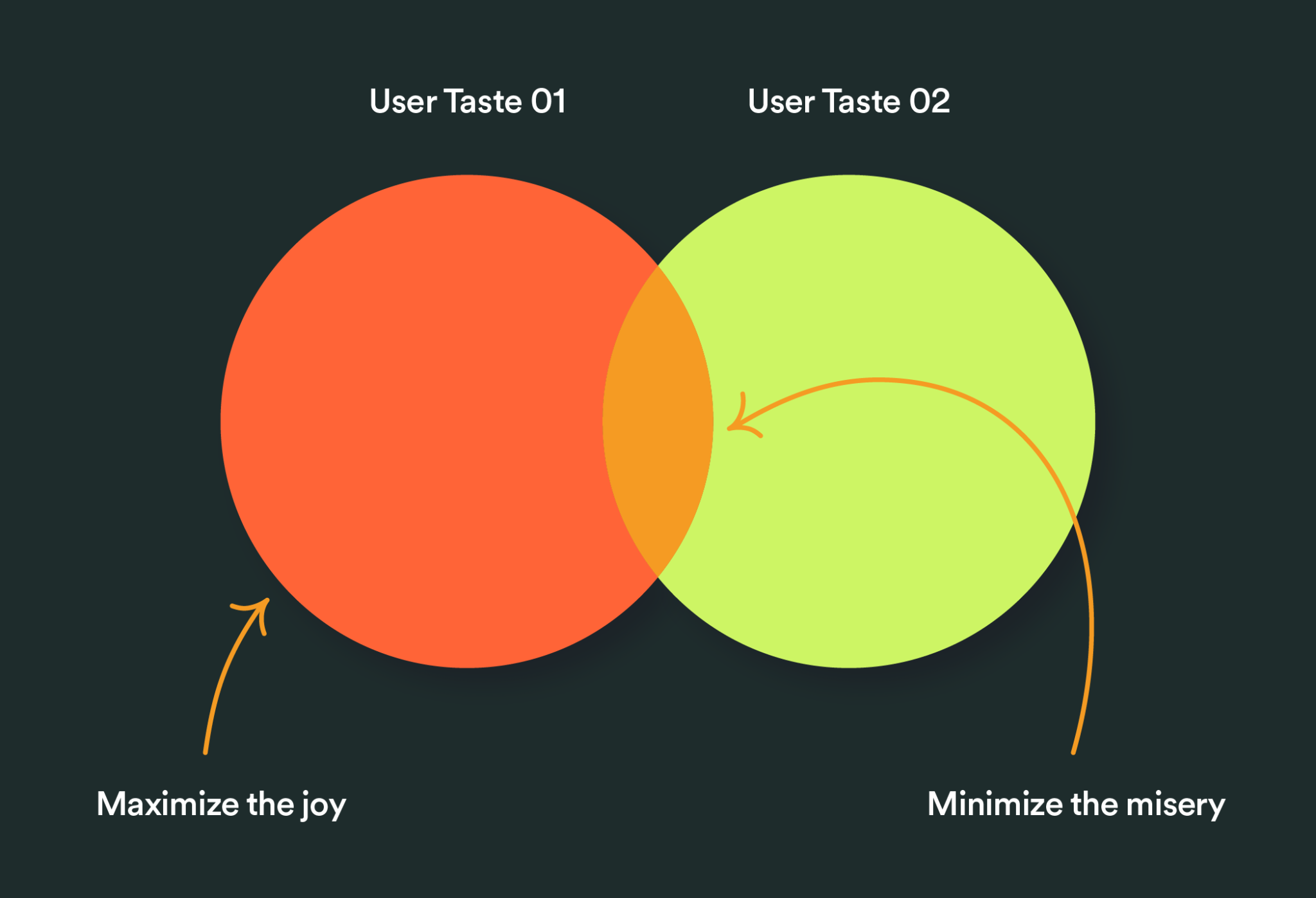
One of the core decisions we made for this product was whether it was better to “minimize the misery” or “maximize the joy”. In other words, is it better to pick everyone’s favorite tracks, even if other people in the group wouldn’t like them, or is it better to pick the tracks that everyone is likely to like, even if their favorite songs never get selected? “Minimize the misery” is valuing democratic and coherent attributes over relevance. “Maximize the joy” values relevance over democratic and coherent attributes. Our solution is more about maximizing the joy, where we try to select the songs that are most personally relevant to a user. This decision was made based on feedback from employees and our data curation team.
It’s a bit simpler to create a Blend with users with similar taste since they listen to a lot of the same music. However, if we have two users with no common music listening history, it’s significantly more difficult to create a perfect Blend. We needed an approach that worked for both types of pairs, while also taking into consideration how any changes to the Blend algorithm impacts all combinations of users.
Between fetching data for both users in the Blend, and trying to come up with the ideal sequence balancing for all of our attributes, creating a Blend is a pretty heavy process. When we tried to come up with the best algorithm, we weren’t so concerned about our latency. Once we were happy with Blend quality, and started to think about scaling the service, we realized how bad our latency had gotten while iterating on the algorithm. We spent a lot of time trying to make the service as fast as possible. What we learned is that our code base had some hot spots in it: some sections of the code were run over 50 times per Blend generation, while other sections of the code were only run once. If we tried to optimize sections of the code that weren’t run many times, we didn’t make much of an impact in our latency. However, when we made improvements to our hot spots, we were able to make a huge difference. The biggest example here was swapping the order of two function calls within an if statement, taking advantage of Java’s short circuiting. This simple code change reduced our latency to 1/10 of its original time.
We were able to make content quality improvements by using both qualitative and quantitative methods. While we normally rely on testing our own playlists when we make changes, we also needed to make sure that we checked several different types of Blends (for example: test a high taste overlap Blend and a low taste overlap Blend). We created some offline metrics to measure how our attributes performed. We also work closely with a Data Curation team, often referred to as the “humans in the loop”. The Data Curation team evaluates and ensures content quality for recommendation systems.
For example, when the team wanted to make a change to make the playlist more coherent, we:
Tested our own playlists — the team had implemented the change for about a month before we evaluated it. During this time, we were able to get a good feel for whether we preferred the change or not.
Performed a heuristic review, where our Data Curation team reviewed a number of Blends with a variety of taste overlap scores.
This process helps identify issues with usability and comprehensibility associated most closely with content quality and with the user experience.
Utilize a tool called a “Content Recommendation Scorecard”.
Score each track over a number of attributes such as relevance and coherence.
From the Content Recommendation Scorecard, we were able to see that the new approach more strongly met our criteria in terms of the attributes we wanted to optimize for.
The review built enough confidence for the team to roll out the new approach to all users.
Creating a social playlist presented a new set of challenges in creating a new playlist algorithm. We had to try to optimize for many attributes: relevance, coherence, equality, and democratic decisions. We also had to consider both high taste overlap users and users who don’t have much taste overlap.
While building out the Blend product, we wanted a way to communicate information to the users about what similarities and differences they have in their music taste. This led to us building out Blend Data Stories, where we can show the users’ information like the artist that brings them together and their taste match score. This year, during the Wrapped Campaign, we gave users a Wrapped Blend experience. We modified the Blend Data Stories to use data from Wrapped, to show users information like their top mutual artists and top mutual genre of the year.
We’re still working hard to improve Blend, and build a product that allows our users to feel closer through music, while thinking of more fun ways to grow the social experience in Spotify. If this type of work sounds interesting, our Personalization team is hiring!
SHARE THIS ARTICLE


