Why We Switched Our Data Orchestration Service

TL;DR Within Spotify, we run 20,000 batch data pipelines defined in 1,000+ repositories, owned by 300+ teams — daily. The majority of our pipelines rely on two tools: Luigi (for the Python folks) and Flo (for the Java folks). In 2019, the data orchestration team at Spotify decided to move away from these tools. In this post, the team details why the decision was made, and the journey they took to make the transition.
Our current orchestration stack
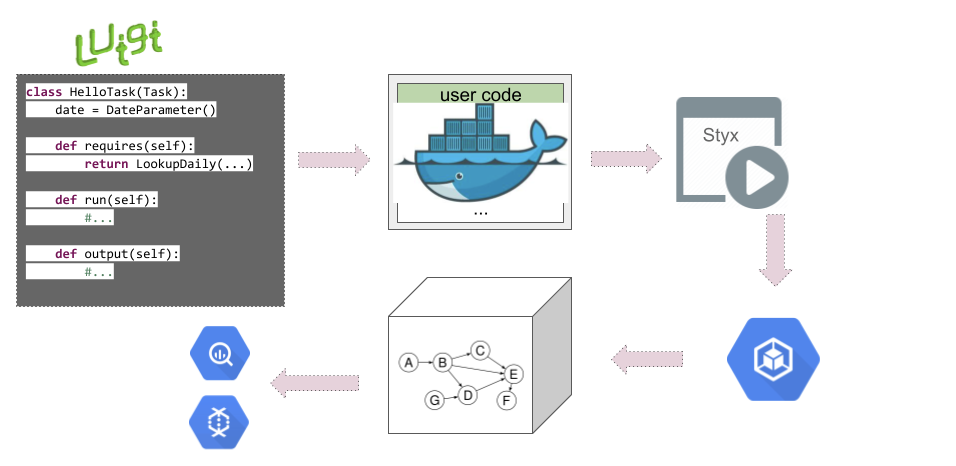
How Luigi works at Spotify .
With Luigi and Flo, we define workflows as recursively dependent tasks. All different tasks, libraries, and logic gets packaged into a Docker image, which is deployed as is to Styx with an entry point to the root task to run. Styx handles scheduling and execution, so when it is time, it will start the Docker image in our GKE cluster.
At runtime, the graph of dependencies is discovered and tasks are run in the defined order. In this stage, the workflow also sends lineage data if it is instrumented to do so.
The tasks might start a dataflow or BigQuery job and publish data to different locations.
Problems we needed to solve
Luigi and Flo are shipped as libraries that the users then consume. There are a few issues with this approach:
Maintenance burden: We need to implement, maintain, and update features on two different libraries offering the same capabilities.
Support burden: We need to push updates to all users, but users don’t always upgrade to the latest version. This makes it hard for us, as a platform team, to roll out fixes and new instrumentation to the entire fleet of 1,000+, and growing, repositories. Monitoring change adoption and managing the fragmented versioning impacts platform and productivity of data engineers.
Lack of insights: The workflow container is a black box to the platform, and it is only possible to collect insights on task graphs, blocking upstreams only after an execution has taken place. This leads to considerable overhead wherein a portion of GKE cluster time is spent polling for missing dependencies.
In 2019, starting this journey, it was evident that there were a number of areas where we could bring (potentially significant) improvements by investing in our scheduling/orchestration offering. We believed, though, that not all of them would have the same impact on our users and our ability to operate in an impactful way.
That said, our prioritized goals for the next-generation orchestration were, and still are, to:
Make upgrades as frictionless as possible. By pushing as much functionality as possible down to the platform teams, it allows us platform teams to own more of the foundational parts. This makes it possible to add features and fixes automatically to all. In the platform mission, we are strong believers that we add value by making things easier. We want to limit the amount of time spent by users on the maintenance of our tool. This allows them to focus and excel in their core domain of expertise.
Enable the development of platform automation functionality. A few examples of automation requested by our users are: opt-in for downstream backfill triggering, various event-triggered actions, canceling workflow execution after a user-defined alert, notify downstream consumers in case of workflow failure/delay. To enable those features we need to have visibility on the tasks and workflows, which we currently don’t have with the Luigi/Flo setup running everything in a Docker image.
Our vision on how to solve this has been to move away from the library/tool paradigm to build the orchestration logic into a service. More specifically, we proposed a new orchestration paradigm where:
Orchestration of tasks within a workflow is performed by a managed service.
Business logic (task code) is run in an environment controlled by the platform.
Users define workflows and tasks using SDKs distributed by the platform teams.
How did we reach our preferred solution?
In our elimination process, we took into account the following factors:
Effort needed to migrate (or not) existing workflows
Development effort and time to market (a new in-house development vs. a ready-made product that we adapt and integrate into our ecosystem)
Maintenance burden (e.g., Google-managed vs. self-managed)
Extensibility of the solution
Ability to inspect what is done within a workflow (explicit definition vs. Docker image)
Multiple language support
The solution we found: Flyte
There are a number of options to perform workflow orchestration. We have done extensive comparisons of a few other systems to get a feeling of what the state of the art is in the industry.
We came to the conclusion that Flyte was the best option because of its extensibility to integrate Spotify tooling, support for multiple languages, and scalability.
The product was actively being developed with a lot of support from the Flyte team, and we’ve been very happy with its progress thus far. The Flyte team had also shared their plans to release Flyte to the open source community, making it a great opportunity for Spotify to be a contributing partner and to give back to the community — something we’re passionate about.
Some of the reasons why Flyte is the best option for Spotify are that it:
Has a similar entity model and nomenclature as Luigi and Flo, making the user experience and migration easier.
Uses Task as a first-class citizen, making it easy for engineers to share and reuse tasks/workflows.
Has a thin client SDK by moving more to the backend: this makes the maintenance of the overall platform much simpler than our existing offering with two libraries (Python, Java) both holding the logic.
Is decoupled from the rest of our ecosystem, enabling mixing and matching in the service layer according to our strategy.
Is extensible to provide more SDKs for orchestration.
Has an extensible backend to support different types of tasks.
Is an existing tool with a platform approach, so that we do not have to develop the service in-house.
Is scalable and battle hardened, as it was already running with similar constraints that we have at Spotify.
Is an open source project actively developed and maintained: Spotify can get a lot of support to get started, and can become a contributing partner.
This is how Flyte integrates into the Spotify ecosystem.
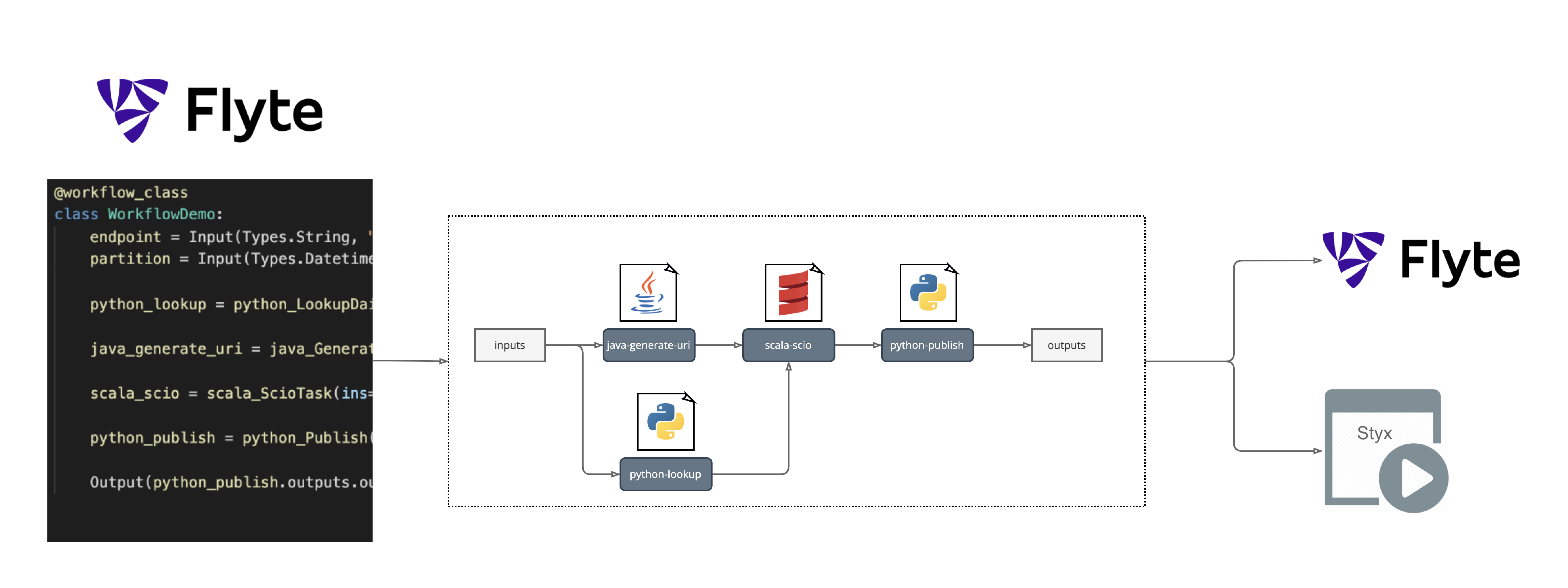
Defining a workflow with Flyte.
The actions described in workflows are visible by the platform team, and we can register workflows in the Flyte system (Flyte Admin) and in our own scheduler (Styx), making the integration smooth.

Execution still triggered by Styx .
What’s next ?
The Flyte journey at Spotify is still ongoing — we’re happy to be running critical pipelines, but we still need to migrate all the existing ones from Luigi to Flyte, which will be an interesting challenge to detail in a follow-up blog post.
If you want to join us to work on products to help Spotifiers build reliable data pipelines, take a look at our career website. We’re looking for talented engineers to help us make a change in that space!
Acknowledgments
The Flyte journey would never have started without the Union team building Flyte and passionate engineers within Platform — Hongxin Liang, Nelson Arapé, Gleb Kanterov, Sonja Ericsson, Babis Kiosidis, Lucía Pasarin, Nian Tang, Julien Bisconti. I want to extend this thank you to early users who helped us build and iterate on our implementation — the financial engineers and platform teams. We are grateful for your help and energy.
SHARE THIS ARTICLE



