Fleet Management at Spotify (Part 1): Spotify’s Shift to a Fleet-First Mindset

This is part 1 in our series on Fleet Management at Spotify and how we manage our software at scale. See also part 2 and part 3.
TL;DR Instead of performing 10 major software upgrades to our infrastructure every year, what if we did 10,000 small ones? Across our entire codebase? That’s the idea behind Fleet Management: by building automation tools that can safely make changes to thousands of repos at once, we can maintain the health of our tech infrastructure continuously (instead of slowly and laboriously). More importantly, removing this low-level work from our developers’ to-do lists allows product teams to focus on solving problems way more interesting than migrating from Java 17.0.4 to 17.0.5. A healthier, more secure codebase, plus happier, more productive engineers. What’s not to like? In this first post about Fleet Management at Spotify, we describe what it means to adopt a fleet-first mindset — and the benefits we’ve seen so far.
The problem of maintaining speed at scale
Since shipping the very first app, Spotify has experienced nearly constant growth, be that in the number of users we serve, the size and breadth of our catalog (first music, then podcasts, now audiobooks), or the number of teams working on our codebase. It’s critical that our architecture supports innovation and experimentation both at a large scale and a fast pace.
Many small squads, many more components
We’ve found it powerful to divide our software into many small components that each of our teams can fully design, build, and operate. Teams own their own components and can independently develop and deploy them as they see fit. This is a fairly regular microservice architecture (although our architecture predates the term), applied to all types of components, be those mobile features, data pipelines, services, websites, and so on. As we’ve scaled up and expanded our business, the number of distinct components we run in production has grown and is now on the order of thousands.

The number of Spotify engineers (green) vs. the number of software components (violet). Components grew at a much faster rate over time.
The small stuff adds up quickly
Maintaining thousands of components, even for minor updates, quickly gets arduous. More complex migrations — e.g., upgrading from Python 2 to 3 or expanding the cloud regions we’re in — take significant engineering investment from hundreds of teams over months or even years. Similarly, urgent security or reliability fixes would turn into intense coordination efforts to make sure we would patch our production environment in a timely fashion.
The graph below shows the progression of a typical migration, in this case upgrading our Java runtime, pre–Fleet Management at Spotify. All in all, this single migration took eight months, about 2,000 semiautomated pull requests, and a significant amount of engineering work.
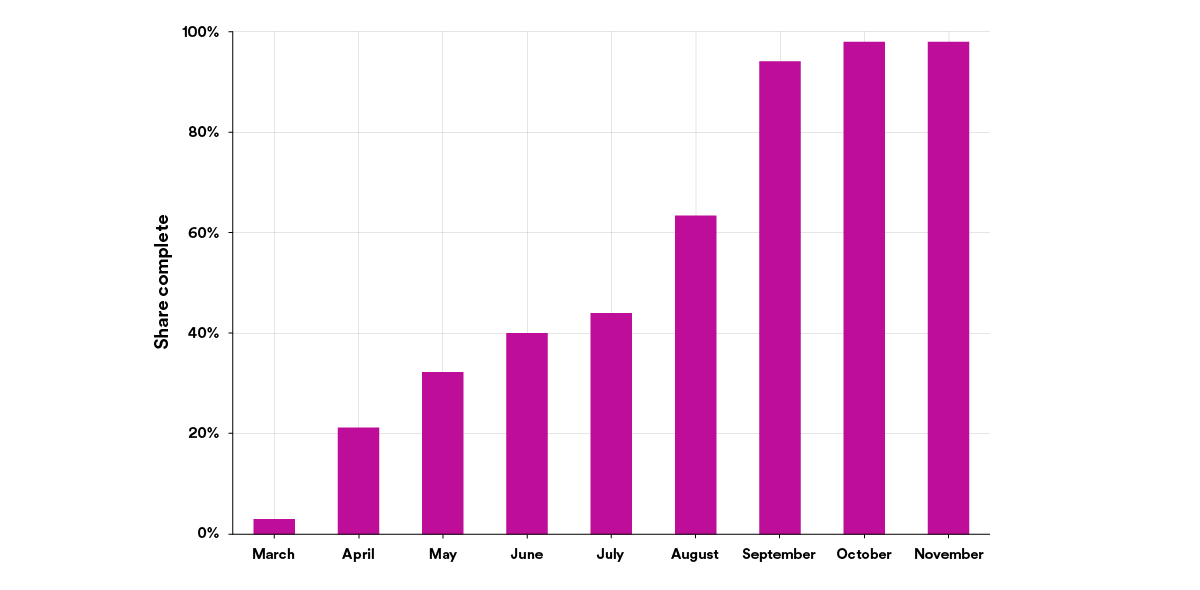
A slow, hard slog: In the days before Fleet Management, we typically measured software migrations, like this update to our Java runtime, over many months.
In addition to the toll this takes on a developer’s time, it also takes its toll on developer experience: this type of maintenance is boring and repetitive toil. It’s exactly the type of work you want to automate.
Time to shift our thinking from squad first to fleet first
All in all, these insights led us to pursue a change in how we think about our software and to consider how we could apply changes across our entire fleet of components, rather than one by one. We call this fleet-first thinking, and the practices and infrastructure to support it Fleet Management.
While we’ll mostly cover the technical aspects of this work in this post, it’s worth noting that changing to a fleet-first way of thinking also includes a big shift in our engineering culture and in the responsibilities of our infrastructure teams. It means that making a change or fixing a problem is not just for your team, but across all of Spotify’s code. Conversely, as the owner and operator of a component, you now receive changes to your components where you are not in the loop before the changes are merged and deployed.
How we apply fleet-first thinking to Spotify’s infrastructure
Let’s consider what is required in order to safely make changes across a fleet of thousands of components and around 60 million lines of code. (In total, we have >1 billion lines of code in source control, with about 60 million being considered production components and thus in scope for Fleet Management.) Here are the four big questions we need to answer:
1. What code are we changing?
First, we need ways to identify where changes have to be applied. Luckily, this was mostly available already. We have basic code search, and all our code and configuration is ingested into Google’s BigQuery, allowing for fine-grained and flexible querying. Similarly, our production infrastructure is instrumented and similarly ingested into BigQuery, allowing us to query for library dependencies, deployments, containers, security vulnerabilities, and many other aspects. This is very powerful and useful for precise targeting of changes. We are currently exploring semantic indexing of our code to enable even more fine-grained targeting — e.g., identifying API call sites across the entire codebase.
2. Is everything we’re changing under version control?
Next, we need to make sure everything we want to make changes to is under version control, in our case, in Git. It goes without saying that this was already the case for our code and configuration, but a fair share of our cloud resources — things like storage buckets, service accounts, and database instances — were not yet in Git, as we were halfway through our migration (back) to a fully declarative infrastructure. That story is for another day, but for the purposes of this post, just know we needed to finish up this work.
3. How do we actually make the changes?
After that, we need a mechanism to author, apply, and roll out changes in a safe way. In short, this mechanism must be able to identify where to apply a change (e.g., match a particular piece of code in a repository), apply it to the repository (e.g., automated code refactoring), and verify that it works (e.g., through a CI build). Lastly, the mechanism has to orchestrate how these changes are merged and deployed and to monitor to ensure we can safely abort in case of failures during build or deployment time.
It’s worth noting that automated code refactoring at this scale quickly gets complicated. Hyrum’s law states that “with a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.” We have found this to be a very apt observation and certainly true for us as well.
Spotify currently uses a polyrepo layout with thousands of GitHub repos — although we have good reasons to believe that the same set of practices and tools outlined here will be applicable should we move to a monorepo in the future. Either way, once you have very large codebases, this type of specialized tooling is necessary to safely and efficiently make fleet-wide changes — see, for example, Google’s paper on C++ refactoring. We’re already seeing this for our largest repositories, currently with around 1 million lines of code.
4. How can we increase trust in changes nobody reviews?
Lastly, we want to be able to complete a fleet-wide change within hours or a few days, and without asking a large amount of our developers to do the work. This requires that changes can be automatically verified, merged, and deployed — without a human in the loop.
While we generally have high-quality test automation, we needed to improve test coverage for some components, and in some cases, add container-based integration testing. Also, many components did not have automated canary-based testing during deployment. We rely heavily on our test automation, and the vast majority of our components do not use any type of manual testing or staging environment. Exceptions are typically those that must be verified end to end with one of our partners or that have additional compliance requirements.
To gain further confidence that we could always deploy from the main branch in Git, we also implemented a regular rebuild and redeployment of all components. This ensures that every component gets rebuilt and redeployed at least once per week, reducing the risk of build or deployment failures due to code rot.
Results: The proof is in the repos
We’re now at a stage where we fleet-manage >80% of our production components, in particular our data pipelines and backend services. We have completed >100 automated migrations over the last three years and automatically update external and internal library dependencies for components on a daily basis. Our automation has authored and merged >300,000 changes, adding approximately 7,500 per week, with 75% being automerged.
Happier, more productive developers
We estimate we have reduced developer toil, freeing up an order of magnitude of hundreds of developer years for more fun and productive work. We also see this in the sentiment analysis, where more than 95% of Spotify developers believe Fleet Management has improved the quality of their software.
A more secure codebase
Our fleet of components is now also in a healthier state than before. For example, components are up to date with the internal and external libraries and frameworks they use. This has significantly reduced the number of known security vulnerabilities deployed in the fleet and the number of reliability incidents as we consistently ensure that every component is up to date with bug fixes and improvements.
As an example, we were able to deploy a fix to the infamous Log4j vulnerability to 80% of our production backend services within 9 hours. (It then took a few days to complete the rollout to our, at the time, unmanaged services.)

Nearly instant peace of mind: After merging our initial fix for Log4j, 80% of our components were patched before the first day of the rollout was even over.
New features, faster
Similarly, this also means that we can make new features and improvements in our internal frameworks available to our developers more quickly than ever before. For example, a new version of our internal service framework used to take around 200 days to reach 70% of our backend services through organic updates (see the graph below). Now that number is <7 days, meaning that if you work on our internal infrastructure platforms, you can iterate and ship new features much faster.
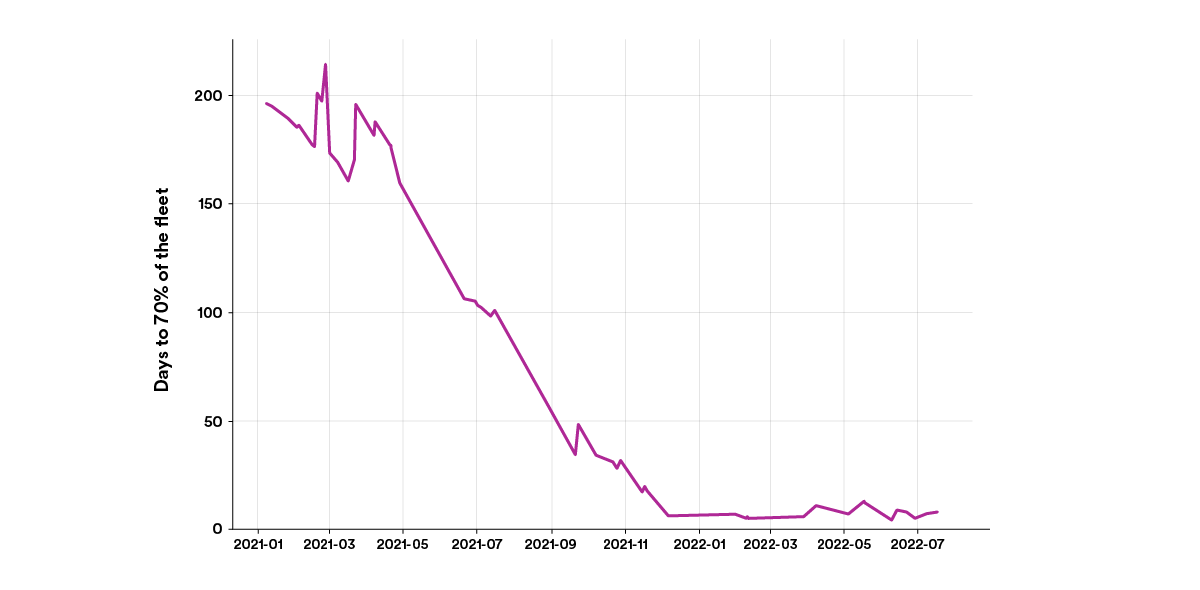
A week instead of months: Updates to this framework used to take about 200 days to reach 70% of the fleet — now it takes about 7 days.
Stepping up our repaving game
Lastly, >75% of our production environment is repaved (rebuilt and redeployed from source code) weekly, reducing the risk of persistent build/deployment failures, mitigating security vulnerabilities, and ensuring components are up to date with Git.
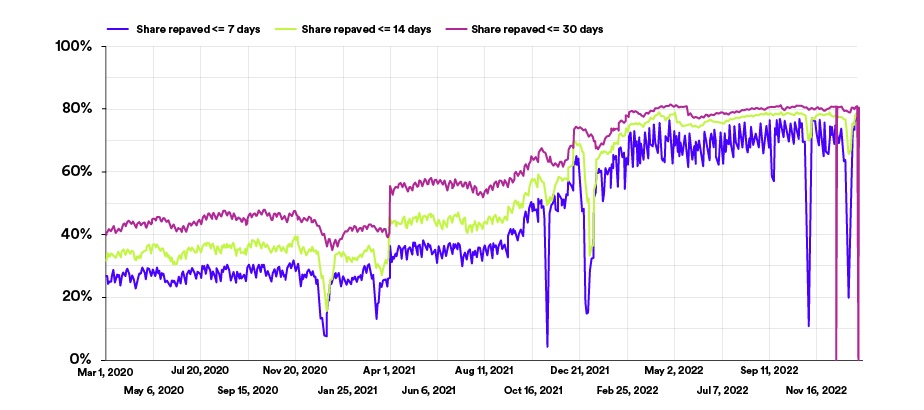
More components, repaved more frequently.
The future of Fleet Management at Spotify
While we’ve made good progress so far, we have lots of improvements to make and challenges remaining.
Continuing adoption
We are gradually onboarding the remaining long tail of components ontoFleet Management. These are typically components that are not built using our technology standards and thus require more development work before they can be fully managed, as well as additional component types. As mentioned above, fleet first is also a major change in our infrastructure teams’ responsibilities. We will continue onboarding teams to be fleet first and to automatically and safely roll out their changes to the fleet, until this is the default for all teams.
More complex changes
We also want to be able to take on increasingly complex fleet-wide changes. We’re now experienced in managing library and container dependencies and in making simpler configuration and code refactoring changes. Next, we want to gradually increase the complexity of the changes we’re confident in rolling out, in particular with the automatic merging and deployment described above.
Increased standardization
One factor that highly influences the complexity of making fleet-wide changes is how similar components in the fleet are. If they use the same frameworks and similar code patterns, making changes to them at scale becomes significantly easier. Thus, we want to limit the fragmentation in our software ecosystem by providing stronger guidelines to our developers on, for example, what frameworks and libraries are recommended and supported and by supporting onboarding existing components to the expected state for our software. We have over the last year doubled the share of components that fully use our standard technology stacks and plan to continue expanding the stacks and driving this adoption over the coming years.
Improved tooling
Lastly, we’ll focus on simplifying our Fleet Management tooling and continuing our long-term strategy to raise the platform abstraction level we expose to our developers. We want every developer at Spotify to be able to easily and safely perform a fleet-wide change.
Look out for more posts
Now that we’ve outlined the benefits of adopting a fleet-first mindset, how did we actually implement it? In future posts in this series, you will get to learn more about the way we implement declarative infrastructure at Spotify and the other infrastructure changes we made to support Fleet Management. In the meantime, you can learn more about our shift to fleet-first thinking on Spotify R&D’s official podcast — NerdOut@Spotify
SHARE THIS ARTICLE



