Fleet Management at Spotify (Part 2): The Path to Declarative Infrastructure

This is part 2 in our series on Fleet Management at Spotify and how we manage our software at scale. See also part 1 and part 3.
At Spotify, we adopted the declarative infrastructure paradigm to evolve our infrastructure platform’s configuration management and control plane approach, allowing us to manage hundreds of thousands of cloud resources across tens of thousands of different services at scale.
Our on-premise origins
A few years ago, Spotify underwent a transition from being entirely hosted in our own on-premise data centers to instead running on the Google Cloud Platform (GCP). As part of this transition, we employed a “lift and shift” model, where existing services, their architecture, and the relationships with the underlying infrastructure were mostly preserved.
This meant that the particular infrastructure choices developers made in the cloud varied a lot depending on the use case and team. As we learned more about running in a cloud environment, our best practice recommendations also evolved with our learning. For example, while we were running on premises, it was considered best practice to host your own Apache Cassandra cluster, deliver messages via Apache Kafka, run custom Elasticsearch or PostgreSQL instances, or install Memcached on dedicated VMs. The cloud provides managed equivalents for all of these — Google Cloud Bigtable and Cloud Pub/Sub, or running Memcached on top of Kubernetes, for example. As a result, the infrastructure that had been created over the years started forming a long tail — snapshots in time of whatever was considered the best practice of its day, along with the mistakes made along the way.

The problem was exacerbated with the continued growth of the company. While our engineering teams grew at a somewhat constant rate, the amount of software being created and infrastructure being provisioned grew exponentially compared to the number of developers. It became increasingly common for a team of developers to need to own dozens to hundreds of codebases (in Spotify lingo, “components”), and through acquisitions and reorgs, transfers of ownership became increasingly common, where the team owning a codebase had lost the knowledge about the architectural and infrastructural choices that had led up to its current design.
Sorely missing was a mechanism for bringing existing infrastructure up to our latest and greatest standards, as well as for putting our fleet into a state where the fragmentation of infrastructure choices would be low enough that our internal platform organization could support the total footprint of our infrastructure.
Our journey into the cloud
In the on-premise world, where individual machines were usually precious pets, we relied on hostcentric configuration management tools like Puppet and, in some cases, Ansible. It was also incredibly common for teams to host their own infrastructure — some examples of that were mentioned above. However, this approach wouldn’t hold up in a cloud environment, due to a number of factors:
In a cloud environment, we generally encourage using cloud-managed alternatives to self-hosted infrastructure.
A lot of configuration is neither service nor infrastructure resource specific. IAM configuration, network and firewall configuration, relationships between entities such as subscriptions, backups, cross-region replication rules, etc., don’t necessarily map well to one particular service, VM instance, or similar.
There aren’t any long-running compute instances that can employ the slow and steady host-oriented reconciliation model that Puppet or Ansible employs. A VM or Kubernetes Pod might get re- or descheduled at any point in time, and the long bootstrapping process for spinning up new instances of Puppet-managed VMs was considered unacceptable to support the shifting traffic patterns of the Spotify data centers.
Hence, we were looking for a new solution that would give us control of all infrastructure at Spotify and allow us to depart from the host-oriented configuration management of the past. We still wanted to retain the ability to apply company-wide policies, guide users to best practices, etc., so we looked for a solution to align on as a company. A number of constraints quickly emerged:
We needed to support a GitOps workflow, where infrastructure configuration is checked in with source code, can be peer-reviewed, and provides an audit trail.
In order to understand the fleet of infrastructure — i.e., all the infrastructure resources out there — we needed to find a solution that would support runtime introspection, where we could, for example, enumerate all the databases that exist at the company, identify the ones that might violate a certain policy, identify the owning team, etc. In some cases, a break-glass process might even be necessary, where an SRE team could go in and alter the configuration for an infrastructure resource immediately, bypassing a GitOps workflow.
In order to be able to apply automated changes to our infrastructure, the configuration needed to be data (e.g., JSON/YAML) rather than code (e.g., Starlark, HCL, TypeScript, etc., popular choices for infrastructure configuration). It is very hard (i.e., Halting Problem hard) to change code so that evaluating it results in the desired infrastructure output but changing configuration-that-is-data is trivial.
The solution we identified also had to be able to be a destination for all of the existing infrastructure at Spotify. We didn’t start from a blank slate; rather, Spotify had many hundreds of thousands of cloud resources before we went on this journey. Hence, whatever solution we picked would need to support some form of “import” workflow, where existing infrastructure could be encoded via configuration files while not affecting the current state of the infrastructure resources in any way.
We believed that a decent starting point would be to simply model raw cloud resources but that this would lead to a huge configuration footprint in the long run. Instead, we saw this as a stepping stone to introducing bespoke custom resources, allowing us to encapsulate and bundle/compose lower-level resources and eventually get rid of all raw cloud resource declarations.
Commonly used solutions would not meet all of the requirements set above; for example, Terraform would not meet requirements 2 and 3.
The solution we decided to bet on was to use Kubernetes for modeling infrastructure resources, which ended up meeting all of the requirements set above. We called the resulting product simply “declarative infrastructure.”
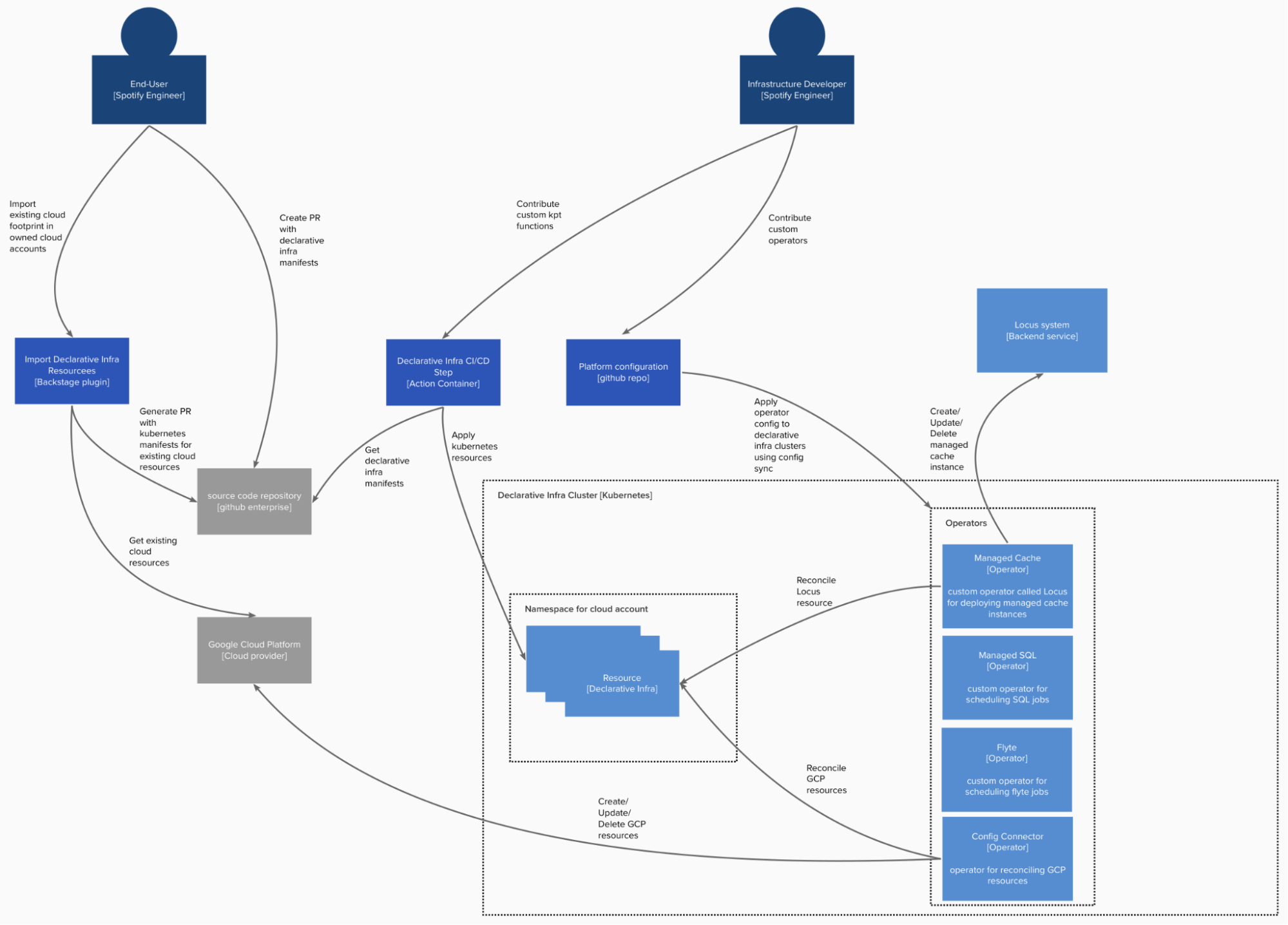
Architecture
Implementing declarative infrastructure using Kubernetes
We applied support for declarative infrastructure resources in Kubernetes by leveraging custom resources. Each kind of infrastructure resource, whether it be a raw cloud primitive or bespoke custom resource, is modeled with a custom resource definition (CRD). The resources are continually reconciled by operators, which attempt to bring the state of the world (GCP; our managed cache system, Locus, which declaratively deploys a Memcached instance; the Flyte system, among others) in line with the infrastructure declarations.
We opted to run the declarative infrastructure platform on dedicated Kubernetes clusters. This was mainly to reduce the risk of impacting other Spotify services running on the main workload clusters. The declarative infrastructure operators can be fairly demanding on the API server, in contrast to workloads for Spotify stateless services, which tend to be demanding on the worker nodes. The platform currently has 3,000-plus GCP projects and approximately 50K GCP resources.
Kubernetes manifests are typically ingested from source code repositories into the Kubernetes cluster through the CI/CD process, where one of the steps in the build process is the declarative infrastructure step, which is a Docker image that performs some light transformations and validation on the manifests using kpt and then applies them to the relevant Kubernetes cluster.
For simplicity and isolation, a dedicated service account is used per source code repository in the CI/CD system. Additionally, a Kubernetes namespace is created per GCP project (a one-to-one relationship). This enables us to limit access for repositories only to manage resources in GCP projects explicitly granted access.
Users create the Kubernetes resource manifests in their source code repo through various mechanisms:
Existing cloud resources are imported with the import Backstage plugin, which queries resources from the relevant cloud account and generates a pull request with the corresponding manifests using Config Connector. With Spotify’s large existing Google Cloud footprint, this facilitates fast adoption of the declarative infrastructure platform.
A Backstage plugin generates an appropriate infrastructure manifest with current best practice, based on answers to some questions.
An IDE plugin with autocomplete makes crafting the YAML for the manifests easier.
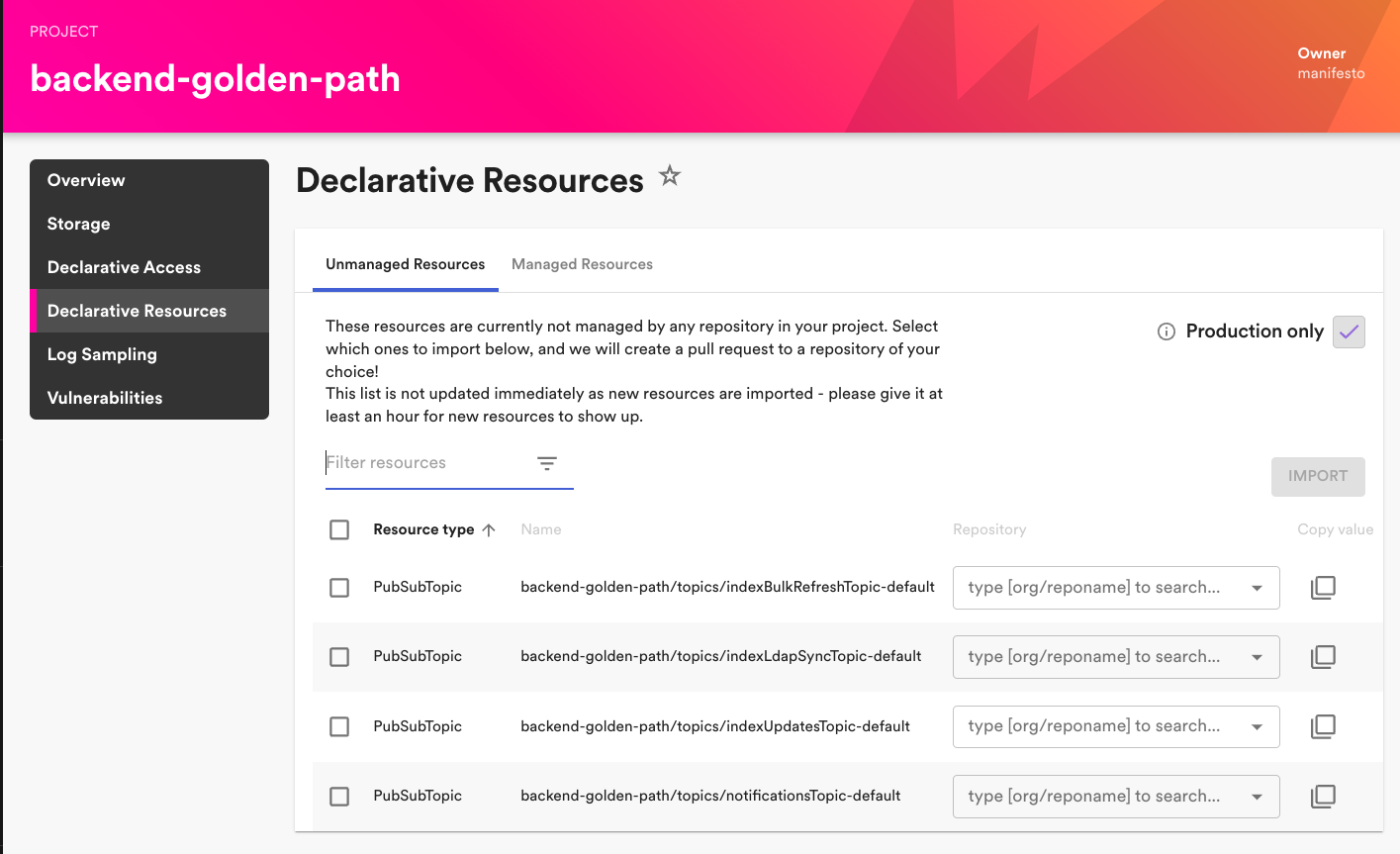
Import resources Backstage plugin.
During the build, the manifests are applied, and then the declarative infrastructure build step waits for the Kubernetes resources to be reconciled (for example, waits for a managed cache instance to be created) and surfaces any feedback to the user on the success or failure of this operation in the build logs and pull request.
Review builds also perform light validation and a dry run against the cluster and surface feedback to the user, on which resources will be added/updated/removed.
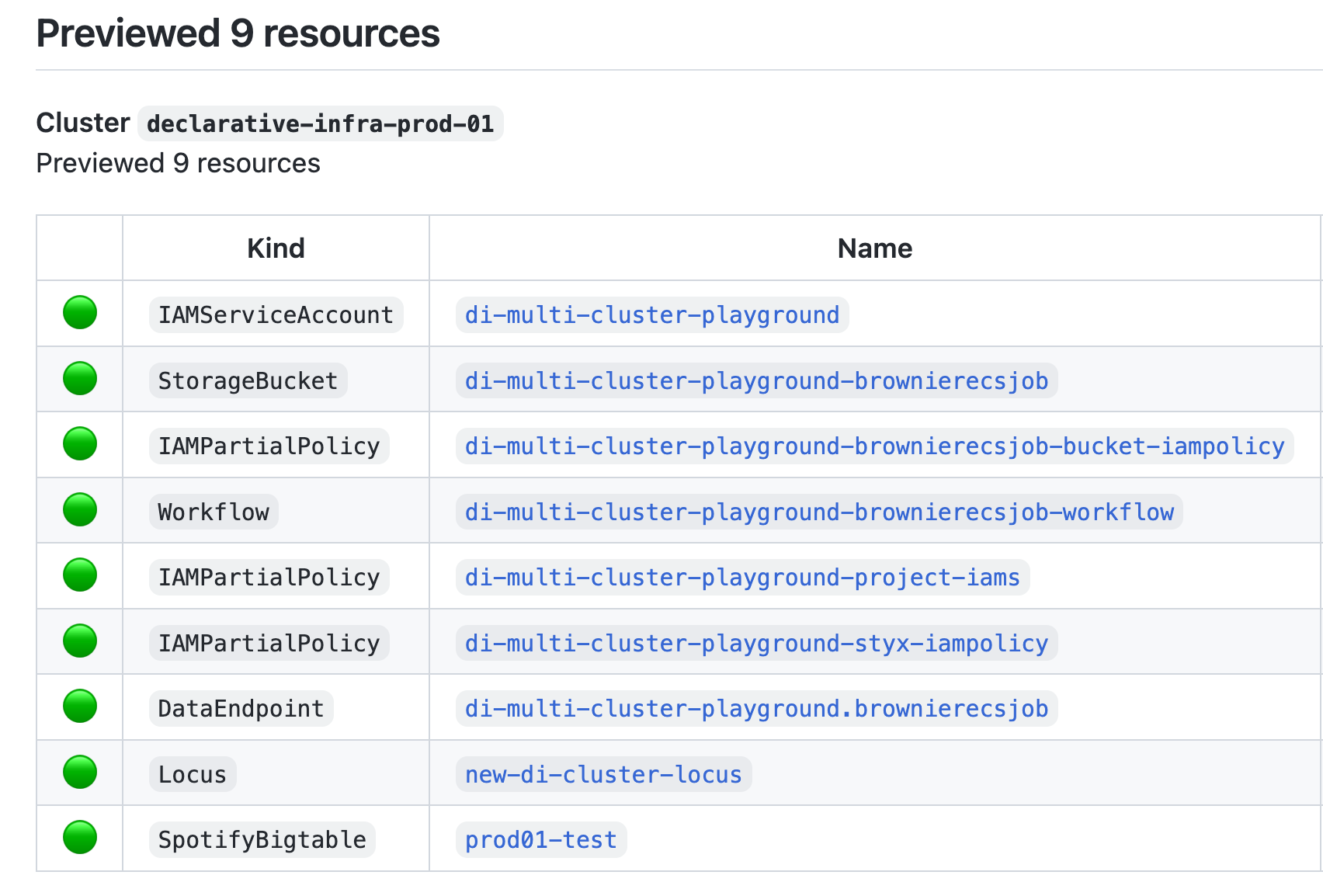
Example of feedback showing successful review build for resources.
Kubernetes operators react to all changes of the resources, handling creating, updating, and deleting the infrastructure being managed by a resource when the Kubernetes resource is deleted.
To avoid any accidental changes and to be able to scale our tooling to the whole organization, regardless of experience level or competence, we decided to limit the default permissions for users through RBAC to only get resources, and added a break-glass mechanism for updates and deletes. The break-glass mechanism also enables teams to make emergency changes without needing to wait for the full code review/build process. A break-glass account is created per namespace, and the owning team has access to impersonate.
One of the main benefits in managing declarative infrastructure on Kubernetes is the extensibility that this allows. Infrastructure developers contribute to the platform by building custom operators. This enables powerful, high-level abstractions for infrastructure needs, such as managed databases, managed caches, data jobs, and other use cases. We currently have approximately 20 internally built operators.
Here is an example resource for a managed cache instance. Runtime insights can be gathered by inspecting the status for the declarative infrastructure resource.
apiVersion: caching.spotify.com/v1alpha2
kind: Locus
metadata:
name: my-locus-instance
namespace: my-gcp-project
spec:
numShards: 6
podSpec:
cpu: 10
memorySizeGb: 16
regions:
- europe-west1
- us-central1
- asia-east1
- us-east1
- europe-west4
status:
conditions:
- lastTransitionTime: "2023-03-17T15:13:46.690585664Z"
message: this resource is up to date
observedGeneration: 1
reason: UpToDate
status: "True"
type: Ready
observedGeneration: 1
ready: "True"Another example is the data endpoint resource (used to define a dataset), which can in turn create and manage the lifecycle of the underlying cloud storage resource. On another team that creates Flyte projects through CRDs, the operator also creates Google service accounts, attaches role bindings to them, and fixes the workload identity for multiple namespaces. This kind of interaction, with multiple resources, takes away a lot of complexity that can happen in scripts and enables a new set of automation on the platform side.
The declarative infrastructure platform can also be extended by infrastructure developers implementing kpt functions or adding gatekeeper validating/mutating webhook configurations. The advantage of gatekeeper over kpt is that this logic will be applied regardless of how resources are applied to the cluster. Kpt functions only run client-side in the declarative infrastructure action container and can easily be bypassed.
Looking into the future
We are excited to continue to add features to the platform.
For end users, we want to improve the developer experience such that:
It is easy to create cloud resources without having to craft YAML declarations or rely on importing existing cloud resources.
A tighter integration with Backstage makes it possible to view the runtime state of resources without having to manually query the cluster.
For infrastructure developers, we will work on improving the operator dev experience for other infrastructure teams to build on top of the platform.
Acknowledgments
Building this platform was a team effort. Many thanks to the Manifesto squad, the Core Infra R&D studio, and contributors from other parts of the organization.
Apache Cassandra and Apache Kafka are either registered trademarks or trademarks of The Apache Software Foundation in the United States and other countries.
Postgres, PostgreSQL and the Slonik Logo are trademarks or registered trademarks of the PostgreSQL Community Association of Canada, and used with their permission.
Elasticsearch is a trademark of Elasticsearch B.V., registered in the U.S. and in other countries.
Google Cloud Bigtable is a trademark of Google LLC.
KUBERNETES is a registered trademark of the Linux Foundation in the United States and other countries, and is used pursuant to a license from the Linux Foundation.
SHARE THIS ARTICLE



