Fleet Management at Spotify (Part 3): Fleet-wide Refactoring

This is part 3 in our series on Fleet Management at Spotify and how we manage our software at scale. See also part 1 and part 2.
For the third part of this Fleet Management series, we’ll discuss what we call “fleet-wide refactoring” of code across thousands of Git repos: the tools we’ve built to enable fleet-wide refactoring and make it an everyday occurrence, how we rolled them out, and lessons we’ve learned along the way.
Why do we need fleet-wide refactoring?
As mentioned in Part 1 of this series, Spotify’s codebase is spread out across thousands of Git repos. We use a polyrepo layout — each repo contains one or a small number of related software components out of the thousands of components we run in production (the codebase for our desktop and mobile clients is laid out differently, in monorepos). This layout has grown out of wanting each individual team to have strong ownership of their components, independently developing and deploying them as they wish.
While having many repos favors individual team autonomy, much of the source code in those repos has dependencies on other parts of our codebase living in other repos. For example, a large percentage of our backend services is built on an internal service framework and set of core libraries, and most batch data pipelines are written using Scio. Updating every one of these repos for every change or bugfix in the framework or core libraries would require a big effort, and, in the past, this could not be done quickly — as mentioned in the previous post, it would usually take 6+ months for each new release of the backend service framework to reach 70%+ adoption in our backend service fleet.
As the number of components we run in production has grown — at a faster rate than the number of engineers — making changes that touch all or most of our fleet of components has become more difficult.
To change our development practices to be fleet-first, in 2021, we decided to invest in creating the tooling and infrastructure to enable fleet-wide refactoring. Our vision is that engineers should think of and be able to make changes to our entire fleet of components at once, rather than improving them one at a time. For example, a team that produces a library or framework that other teams use should no longer think of their work as done when they cut a new release and announce it is ready to be used — the work is done when they’ve updated all of Spotify’s code to use that new release. Rather than sending an email asking other teams to make a code change by some deadline, platform teams should now take on the work of making that change fleet-wide across our entire codebase, no matter how many repos it affects or who owns those repos. Someone discovering a performance optimization should feel empowered to make that optimization everywhere.
To make these types of changes easy and common while still having code in thousands of repos, we needed to remove “the repo” as a barrier or unit of work and to encourage engineers to stop thinking in terms of “my code” and “your code”.
This work has broken down into two main areas:
Managing the dependencies of most components with automation and making it very easy for engineers to update the particular version of a library used across the entire fleet
Enabling engineers to easily send pull requests to hundreds or thousands of repos and managing the merge process
Actively managing dependencies with automation
When we decided to invest in fleet-wide refactoring, we had already been using a BOM (“Bill of Materials”) in our Apache Maven–based backend services and libraries for about a year. A BOM specifies the to-be-imported version for many artifacts in a single artifact. Our BOM (which we call “the Java BOM”) was created to reduce the amount of headaches when upgrading libraries in a backend service, since we have so many libraries that depend on each other — for example, Guava, Google Cloud libraries, grpc-java, our own internal frameworks, etc. By creating a single artifact that can control what version of many other libraries is used, we can upgrade individual repos to use newer dependencies by updating just a single line in the pom.xml file.
Using a BOM to control what specific version of often-used dependencies is pulled into each component also allows us to vet which versions of which libraries are compatible with each other, saving individual engineers from having to do that themselves across many components and teams. Compared with other tools like Dependabot, using a centralized dependency management manifest such as our Java BOM allows us to seamlessly upgrade many libraries at once while making sure that they are all compatible with each other. Every time anyone at Spotify proposes an update to our BOM to update the specific version of a library or add a new library, we run a series of tests to check the compatibility of all libraries against each other.
One of the first decisions in our fleet-wide refactoring effort was to accelerate the use of our Java BOM in our Maven-based backend services. Instead of teams opting in to using the BOM, we would automatically onboard all backend components to use the BOM, generating pull requests (PRs) for every repo. In addition, we decided we would automatically merge these PRs into those repos as long as all the tests have passing scores (more on this below in “Getting automated code changes into production”).
Today we have a very high adoption rate of the BOM in our production backend services — currently 96% of production backend services use our Java BOM and 80% are using a BOM version less than seven days old (a streak we’ve kept up for 18 months). With this high adoption, engineers at Spotify can update the version of a dependency via a single pull request to the BOM repo and be confident that it will automatically roll out to nearly all backend services in the next few days. This provides a very convenient distribution mechanism for teams who own libraries that others depend on — as long as the changes are backward compatible.
We focused first on automated dependency management for our backend components due to their large volume (thousands in a microservice architecture). We’ve since repeated this effort for our batch data pipelines using Scio. 97% of Scio-using pipelines use an sbt plugin that manages the version of most libraries used by the pipeline code (acting similar to a BOM), and 70% of pipelines on average are using a version of the artifacts less than 30 days old. We are now looking to repeat this “BOM-ification” for our Node-based web components (internal and external websites) and Python-using components, to centralize and better control versions of all of the dependencies being used.
Being able to easily manage and update the dependencies that our fleet of software components uses has had enormous security benefits. As mentioned in Part 1, when the infamous Log4j vulnerability was discovered in late 2021, 80% of our production backend services were patched within 9 hours. There has been another benefit to having a majority of components use the same versions of commonly used dependencies — it is easier to write code refactorings for the entire fleet when most components are using the same versions of dependencies.
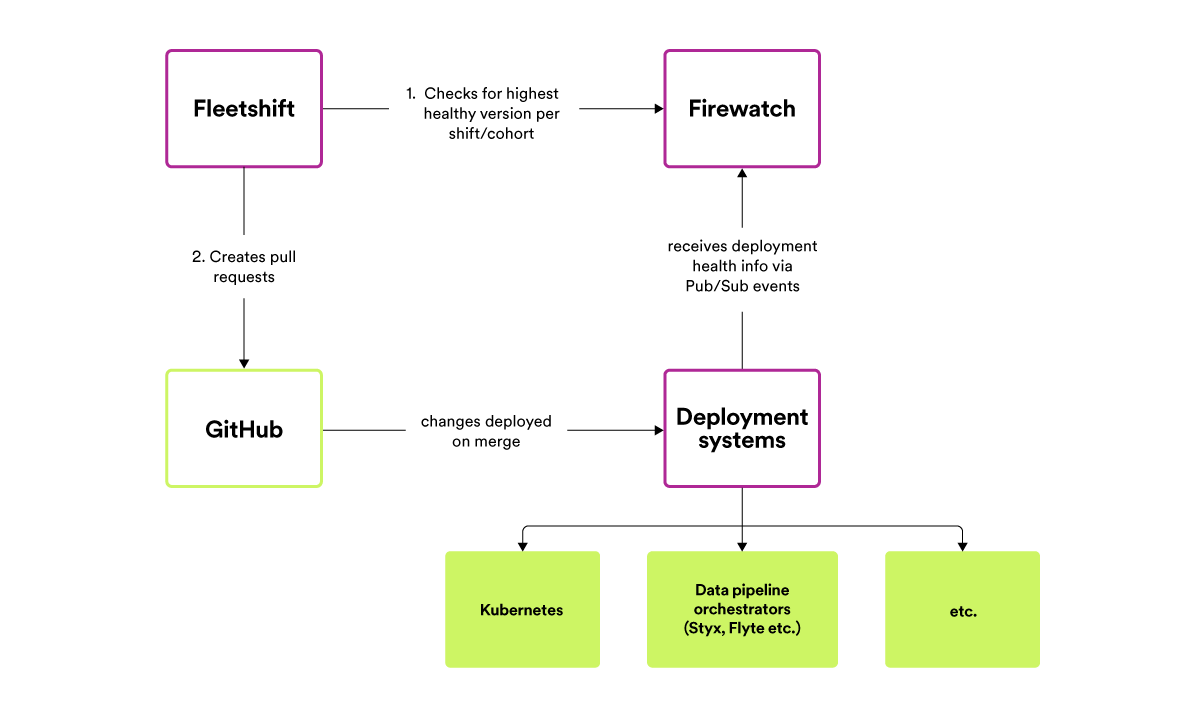
Fleetshift: the platform we use to change code in many repos at once
The engine we use to automate fleet-wide code changes across all our repos is an in-house tool called “Fleetshift”. Fleetshift was originally a hack project created by a single engineer as a successor to a long line of homegrown scripts for generating bulk pull requests, and was then adopted by the fleet-wide refactoring initiative and made a standard tool, similar to the BOM.
We treat Fleetshift as a platform — a single team owns it and other refactoring tools, and this team focuses on making the process of a fleet-wide change ever easier, while other teams use these tools to actually execute their fleet-wide code changes. This separation in ownership and responsibility is important to scale up the number of automated fleet-wide changes and to embrace the fleet-first mindset company-wide. Each team at Spotify that produces a platform, library, SDK, API, etc., is the best team to handle and automate the rollout of that change to the entire fleet — we don’t want to have a single “refactoring team” responsible for rolling out other teams’ changes, as that would create a bottleneck and adversely affect how many fleet-wide changes we can realistically make.
Fleetshift makes fleet-wide code changes by essentially running a Docker image against each repo. An engineer wanting to make a fleet-wide code change needs to supply a Docker image that will refactor the code, using either off-the-shelf tools (such as sed, grep, etc.) or writing custom code. Once the refactoring is ready, the Docker image is handed over to Fleetshift to run against each of the targeted repos. Fleetshift clones each repo and executes the Docker image against the checked-out code — noting any changed/added/removed files and creating a Git commit for the change — and then generates a pull request to the original repo. The author of the shift specifies the commit message and PR title/description in the shift configuration so that the receiver of the automated change can understand what is being changed and why. Authors can track the progress and other details of their shift on our internal platform, Backstage.
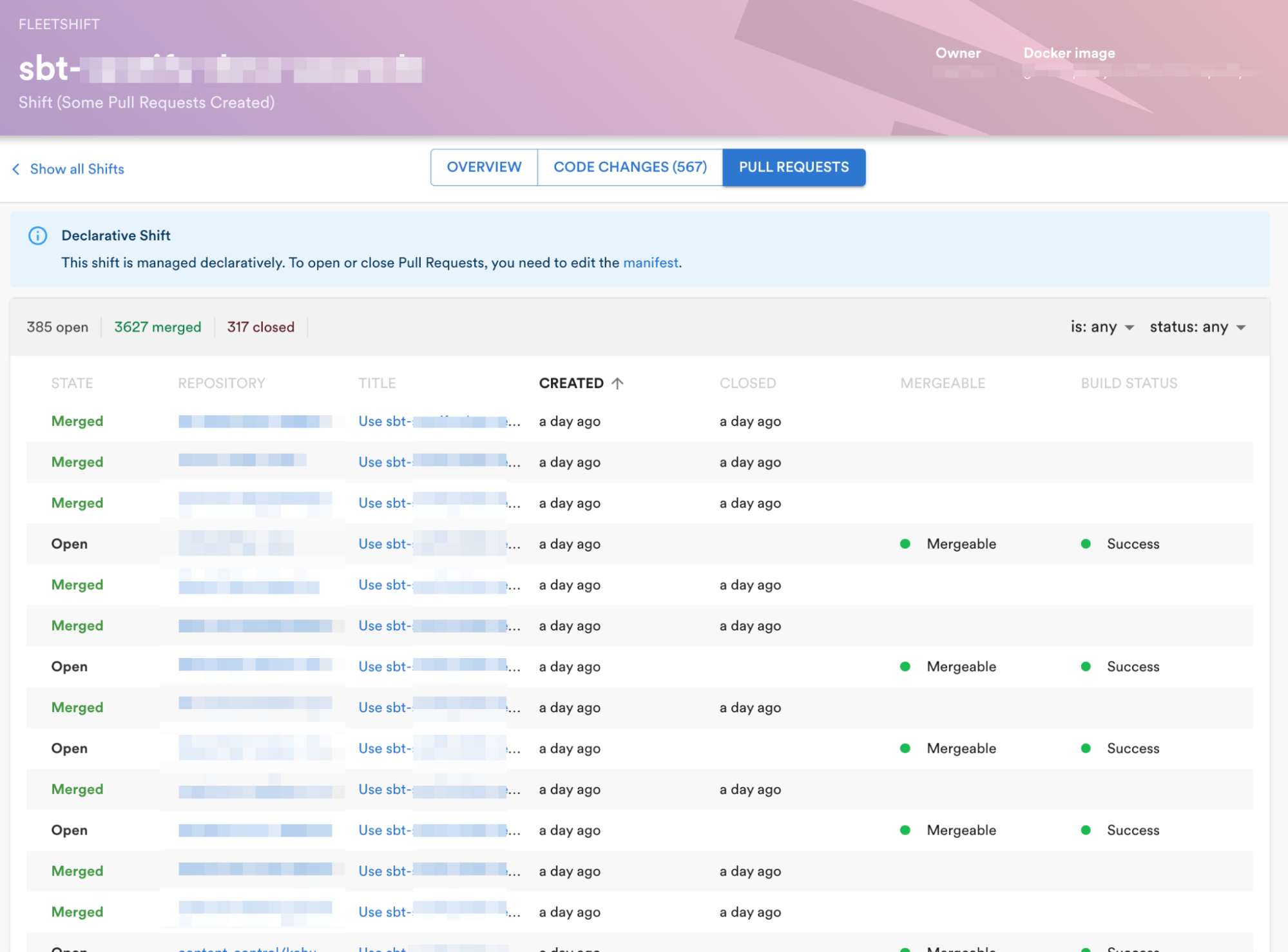
Example of tracking the progress of a shift on Backstage.
The innovation in Fleetshift is to use our large existing Kubernetes infrastructure (several thousand nodes across dozens of clusters) to do the work of cloning repos, executing code transformations and pushing changes back to our GitHub instance. Previous generations of in-house tools like this would do all of the work on an individual engineer’s laptop, creating an impediment for any engineer brave enough to attempt a fleet-wide code change. Fleetshift runs code transformations on repos as Kubernetes Jobs, leveraging the parallelism and autoscaling inherent in Kubernetes to make it equally as easy for an engineer to kick off a code transformation targeting ten or a thousand repos. Code transformation/refactoring jobs run on what are effectively the spare cycles of the same computing infrastructure that powers Spotify’s backend.
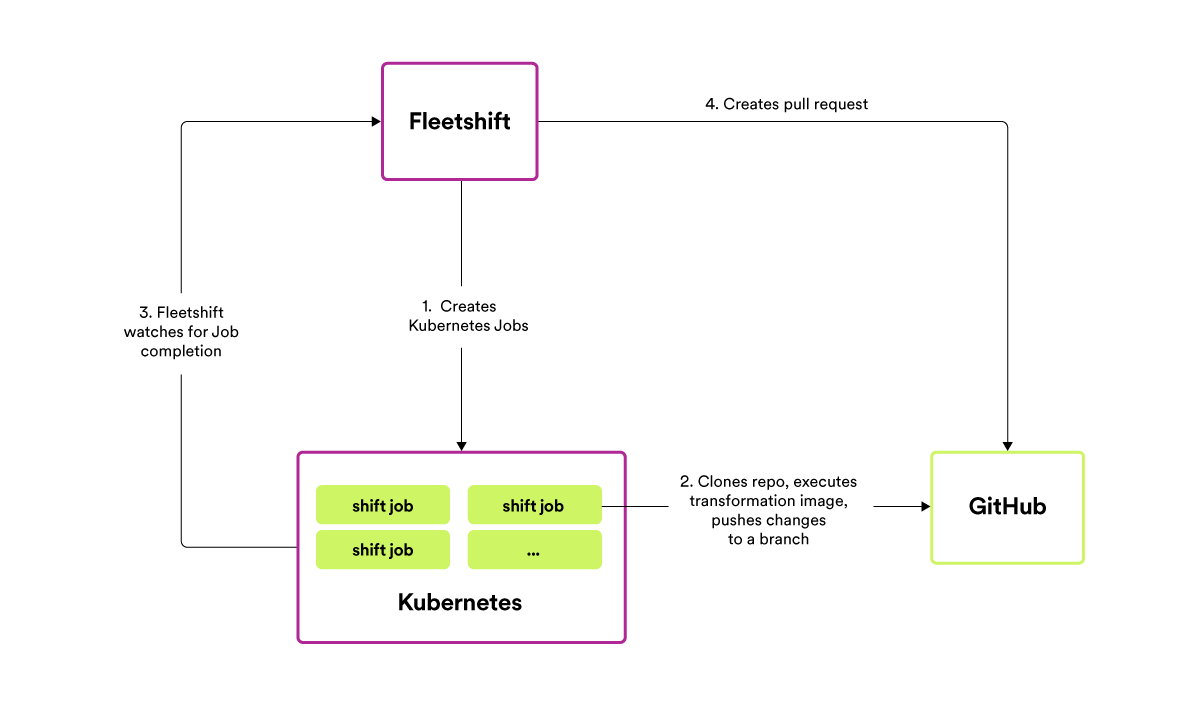
Simplified diagram of how Fleetshift generates code changes and pull requests.
Another innovation in Fleetshift is to model the code transformation that the author wants to make as a Docker image. Fleetshift supports any type of code change, as long as you can write the code to make that change and put it into a Docker image. The tools that we use today to power our fleet-wide refactorings run the spectrum from shell scripts that make relatively simple changes to using OpenRewrite and Scalafix for making sophisticated AST-based refactorings.
Shifts can be run once or configured to run daily (every weekday). Recurring shifts are useful for continual changes, such as the shift that updates the Java BOM version in each backend component every day or that updates all consumers of our internal base Docker images to the latest release every day.
Shifts are modeled as a custom Kubernetes resource, and Fleetshift itself acts as an operator built on top of our declarative infrastructure tooling. The shift resource is stored as a YAML file in a GitHub repo just like any other code at Spotify so that launching or iterating on a shift means making pull requests, getting code reviews, etc.
apiVersion: fleetshift.spotify.com/v1
kind: Shift
metadata:
name: update-foobar-sdk-to-v2
namespace: fleetshift
spec:
container:
image: example-shift:1.2.3
pullRequest:
title: update foobar-sdk to v2
commitMessage: update foobar-sdk to v2
description: |
The PR updates the foobar-sdk from v1 to v2 and refactors code calling now-removed methods in v2 to use their counterparts instead.
You can see a full changelog [here](link).
If you have any questions please reach out to #foobar-team-channel
targetRepos: [ ... ]An example shift resource.
To find which repos to run their shift against, authors can use either GitHub search for basic queries or BigQuery for more sophisticated searches. (We ingest all of our source code from GitHub into BigQuery daily to allow for searching and joining against other datasets — for example, to find all repos containing production data pipelines calling a particular method and also using version 2.3 of some library.) The list of repos to target can be configured directly in the shift resource or can be stored in a BigQuery table, which is useful for recurring shifts that run daily and might need to target a different set of repos each day (as characteristics of the source code in those repos change over time).
Similar to our Java BOM, Fleetshift already existed and was used by a handful of teams when we decided to invest more heavily in fleet-wide refactoring. In order to lower the amount of friction first-time users might encounter, the Fleetshift platform owners also maintain a set of reusable Docker images that others can use or build on for their particular fleet-wide code refactoring. Common building blocks include Docker images for mutating YAML files, bumping the version of a specified Docker image to the latest release, and doing Java AST-based refactoring with OpenRewrite. We also maintain a knowledge base and documentation hub on how to accomplish certain types of refactoring tasks in various languages so that all teams who have a need to change code fleet-wide can learn from each other.
Getting automated code changes into production
To effectively change code across all of our repositories, it is not enough to be able to use automation like Fleetshift to generate hundreds or thousands of pull requests at a time — the changes also need to be merged. A typical engineering team at Spotify might maintain a few dozen repos, with those repos receiving varying amounts of attention depending on how stable or active each component is. It might take weeks or months for an automated code change sent to a large number of repos to see the majority of the pull requests be merged by the owners. If our goal is to make it a common everyday activity for engineers to refactor code across the whole company — increasing the amount of bot-created code changes — we also want to avoid overwhelming engineers with the need to review all the changes to all their repos. This is an issue we saw even before we decided to make fleet-wide refactoring easy, when using open source tools like Dependabot or homegrown scripts to send pull requests — getting the long tail of pull requests merged to complete the fleet-wide change takes a lot of following up and asking teams to review and merge the PRs.
Our solution is to remove the need for manual human reviews — we’ve built the capability for authors to configure their automated refactoring to be automatically merged, as long as the code change passes all tests and checks.
To do this, we built another new infrastructure service — creatively named “automerger” — which contains the logic of how and when to perform an automerge. While GitHub now has a built-in automerge feature for pull requests, writing the code ourselves allows us to specify exactly how and when we want changes to be automerged. We invert control on who decides what is automerged, from the repo owner to the change author, and we also control the rate at which changes are merged to avoid overwhelming our CI/CD systems. Additionally, to reduce the chances of surprises or incidents, we only automerge changes during working hours for the repo-owning team, and never on weekends and holidays.
We will only automerge a change into a repo as long as it passes all the tests, but if the tests of the repo are not sufficient to test certain types of bad changes, this is a signal to the owner that they should be adding more and better tests to their repo. To help teams track the readiness of their individual components for automerging, we created new Soundcheck programs and checks in our internal Backstage instance. Teams use these to monitor the code health of the components they own and whether or not they are meeting our standards for testing, reliability, and code health. For example, these checks allow owners to track which components are using our Java BOM (or other centralized dependency management manifest), which components might be missing integration tests, or if their backend service is not using health checks on their deployments.
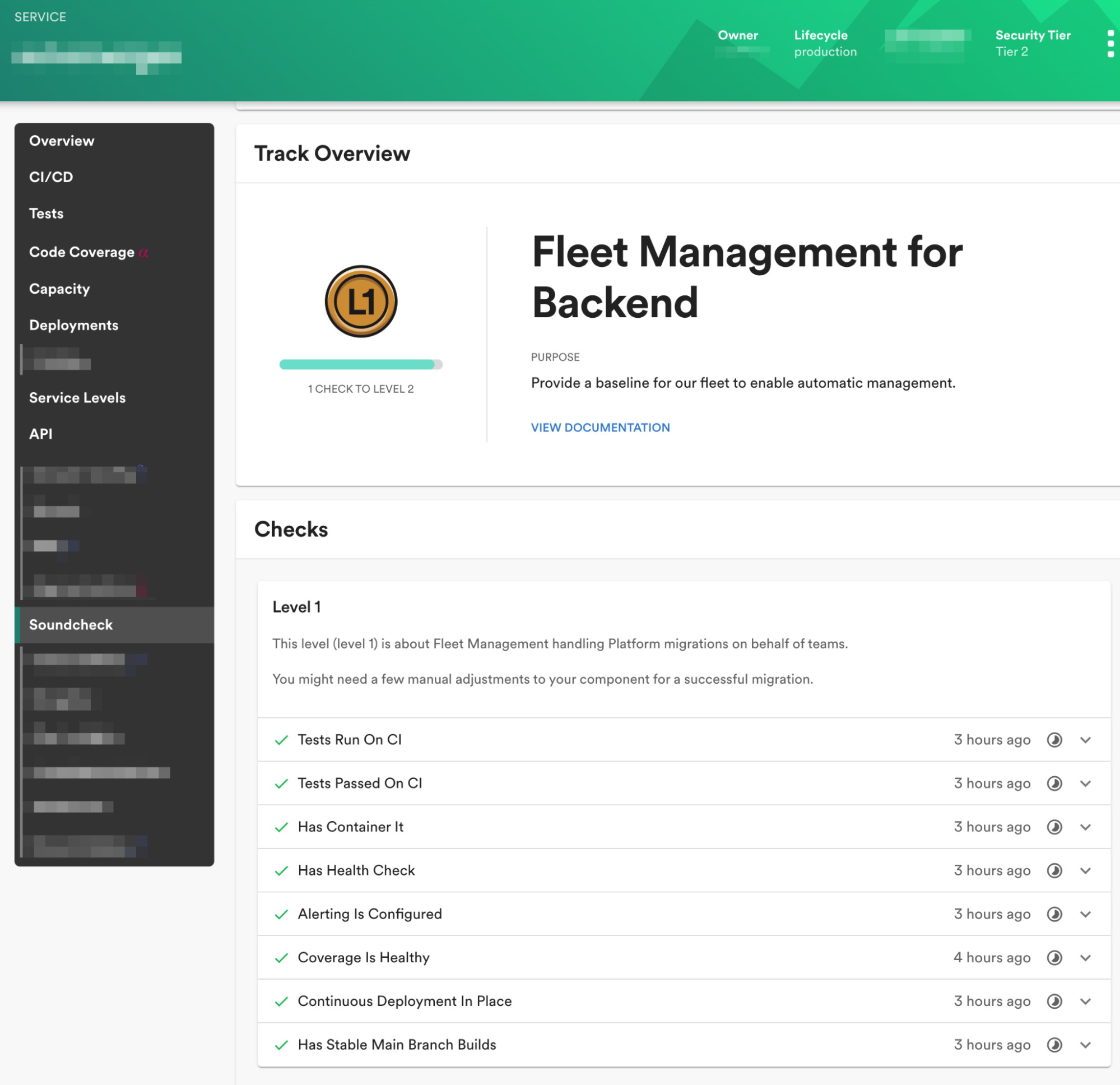
A view of the Fleet Management program for an example backend service on Backstage.
Introducing automerging as a concept to our development practices has acted both as a stick and a carrot — we can only automate code maintenance tasks for you if you have sufficient tests. Your code also needs to pass sufficient tests to avoid bad changes from being merged into your code. We’ve seen teams motivated to improve the Soundcheck scores of their components so that the platform and other teams can manage and automatically refactor more aspects of their code.
While most components have comprehensive pre-merge test suites which would catch any potential “bad” change and prevent it from being automerged, we don’t want to rely on pre-merge testing alone to catch problems in automated fleet-wide refactoring. Once an automatically generated pull request is automerged, we monitor the health of the affected component by consuming Pub/Sub events from our backend deployment and data pipeline execution systems, in a service we call Firewatch. Each pull request that is automerged is registered with Firewatch so that it can correlate failed backend service deployments or data pipeline executions with potential automerged changes into their repos. If Firewatch notices that too many automatically merged commits have failed backend deployments or pipeline executions associated with them, it alerts the owners of those automated changes so that they can investigate.
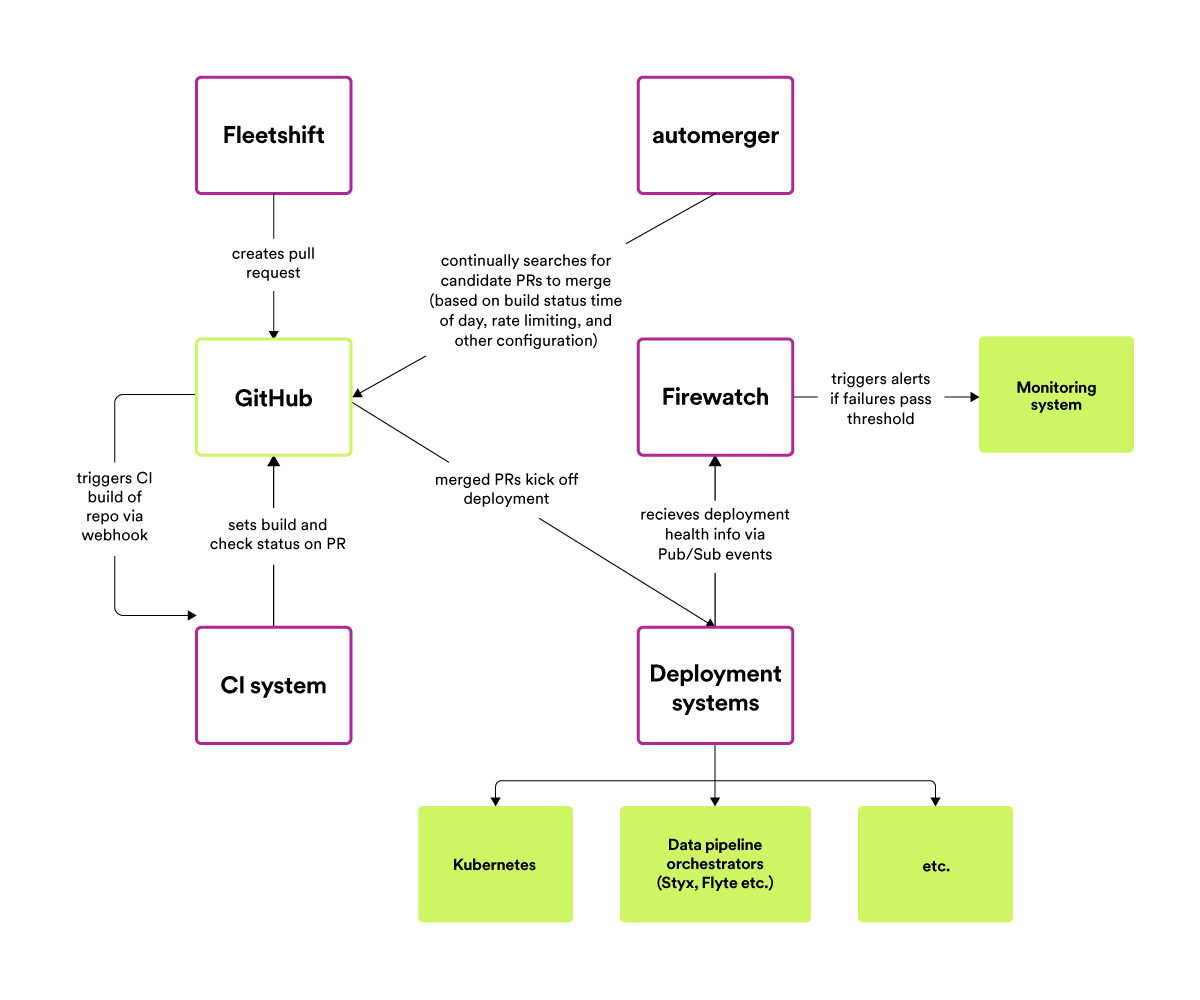
High-level architecture of the automerging process.
The initial rollout of automerging was done very slowly and was initially intended only for the Java BOM–updating shift. Backend components were divided into phases based on how critical they were, and automerging of the BOM updates was gradually enabled for one phase at a time. This allowed us to build confidence in the safety of the automerger and our ability to monitor the health of components post-merge, while at the same time increasing adoption and usage of the BOM to the 90%+ rate it is at today.
The initial slow rollout of merging changes without a human reviewing every single PR proved both the usefulness and safety of automerging as a concept, and today we use automerging for several dozen shifts every day, for both simple dependency bumps and more sophisticated refactorings.
During the initial rollout of automerging, a conscious decision was made to treat automerging as something you would have to opt out of if you did not want it, rather than something you need to opt into. We believe this decision helped to make automerging such a successful and widespread practice today, since it was treated as a default from the very beginning. When a team wants to opt-out a repo from automerging, we require them to document a reason and encourage them to set an expiration date on the opt-out so that they feel incentivized to fix whatever is causing them to not trust in the automation. Additionally, our most critical repos have another set of constraints and checks that they must pass before we can automerge any change to them. As a result of treating automerging as something that must be opted out of rather than into, only about 50 out of thousands of repos today are currently opting out. We often see teams that have added an opt-out come back and remove the opt-out before it expires, once they’ve fixed the underlying issue and are ready for automerging.
One lesson we’ve learned from introducing automerging for some types of automated changes: once people get over the initial fear of robots changing their code without their approval, their general attitude toward the topic has not been reluctance but wanting more. Far more teams and engineers than we expected ask why certain automated changes are not being automerged, and the change-consuming teams have been known to ask the change producers to enable automerging. We have found that most engineering teams do not want to be bothered to have to review and merge each and every PR to update a library to the latest patch release or bump the version of a Docker image used in a build — and they are happy for teams from whom they consume code to handle refactoring their code to use new versions of frameworks or APIs as needed.
Not all automated code changes sent by Fleetshift are configured to be automatically merged. Fleetshift is also used to send code changes as “recommendations” — for example, teams have used Fleetshift to recommend better storage classes for Google Cloud Storage buckets or to rightsize pods running in Kubernetes to use less CPU or memory resources. We’ve found that making a “recommendation” by presenting a team with a pull request significantly lowers the barrier to having the team act on that recommendation — all the owning team has to do is review the diff and press the merge button.
Testing fleet-wide refactorings before sending a pull request
Fleetshift has a “preview” mode for authors who are iterating on their initial version of their fleet-wide change, where prior to actually sending a pull request to anyone, the author can examine the diff and logs of their code transformation against all of the repos it will target.
We quickly found, though, that it is not enough to be able to see what code your refactoring will actually change once it runs. Authors also want to know if the tests of all the impacted repos will continue to pass, before actually sending a pull request to anyone.
To fulfill this need, we built another tool, Fleetsweep (you might notice a theme to the naming), that allows engineers to test their shift’s Docker image against a set of repos. A Fleetsweep job runs on the same Kubernetes-backed infrastructure as Fleetshift, allowing it to scale to requests targeting a large number of repos.
Instead of generating a pull request against the original repo, Fleetsweep creates a short-lived branch in the repo containing the automated change. Fleetsweep then triggers a build of that branch in our CI system and reports the aggregate results back to the change author, allowing them to inspect which repos would have failed tests within that automated refactoring and to inspect the build logs of each repo as well, if needed.
The existence of Fleetsweep allows engineers to test how well their change will work across the fleet before submitting it to Fleetshift and creating pull requests (which can create noise for other engineers). For example, it is a common practice with our Java BOM for authors to run a Fleetsweep for a potential library upgrade if there is any question of whether the new release contains any backward incompatible changes.
Enabling gradual rollouts of some fleet-wide changes
As we’ve extended fleet-wide refactoring and automated dependency management to more types of components, we’ve found that we cannot always have a high amount of confidence in pre-merge testing’s ability to catch problems for all types of changes. For example, many of our batch data pipelines are run on Google Dataflow, and while the test suites of individual components are often focused on testing the business logic of the data pipeline, it is much harder for each individual pipeline to reliably test the details of what happens when the pipeline runs in the cloud and how the dozens of runtime dependencies interact with each other.
Another challenge with batch data pipeline components in particular is that, unlike backend services, code changes are not immediately run after being merged. The typical batch data pipeline is executed once per hour or once per day, dramatically increasing the feedback loop between when a code change is merged and when the results of it can be observed. Lastly, a “bad” code change might not fail in a way that causes the component to crash or return errors — some bad changes might result in quiet corruption of data.
To combat this while still embracing the need to make it easy for engineers to refactor and update code across all components at once, we’ve modified the Fleetshift system over time to support “gradual” rollouts. An author can configure their shift so that the target repos are divided into a number of cohorts; the change that the shift makes (e.g., upgrade the X library to version Y) is only applied to each cohort once the change has been successfully applied to enough repos in the previous cohort.
To judge when a cohort of repos is healthy “enough” for a given version, Fleetshift consults the Firewatch system to find the maximum version for each cohort where a certain amount of repos in prior cohorts have had a percentage of successful deployments (or executions for batch data pipelines) higher than a configurable threshold.
The connection between Fleetshift and Firewatch creates a type of feedback loop in the automated system: the success (or failure) of an automated change (such as “update the foobar library to the latest release”) yesterday informs the decision to apply or not to apply that same update to additional repos today.
The gradual cohort-based rollout process is built on top of the monitoring data we already have in Firewatch.
In the batch data pipeline example mentioned earlier, we divide the set of repos into cohorts based on signals, such as how critical the data produced by the pipeline is (apply automated changes to the lower-value tiered components before higher-value tiers) and how good the pre-merge tests and post-merge monitoring of the component is. As another example, the daily BOM update shift divides backend repos so that the most critical system only receives the new version once it has been successfully deployed in a majority of other backend components.
Results
With the infrastructure and tools outlined above, fleet-wide refactoring at Spotify has come a long way in the past two years. In 2022, Fleetshift created more than 270,000 pull requests, with 77% of those PRs being automerged and 11% merged by a human (each of these stats is a 4–6x increase from 2021). The 241,000 merged pull requests created by teams using Fleetshift represent a total of 4.2 million lines of code changed. In surveys, more than 80% of engineers at Spotify said that Fleet Management has positively affected the quality of their code.
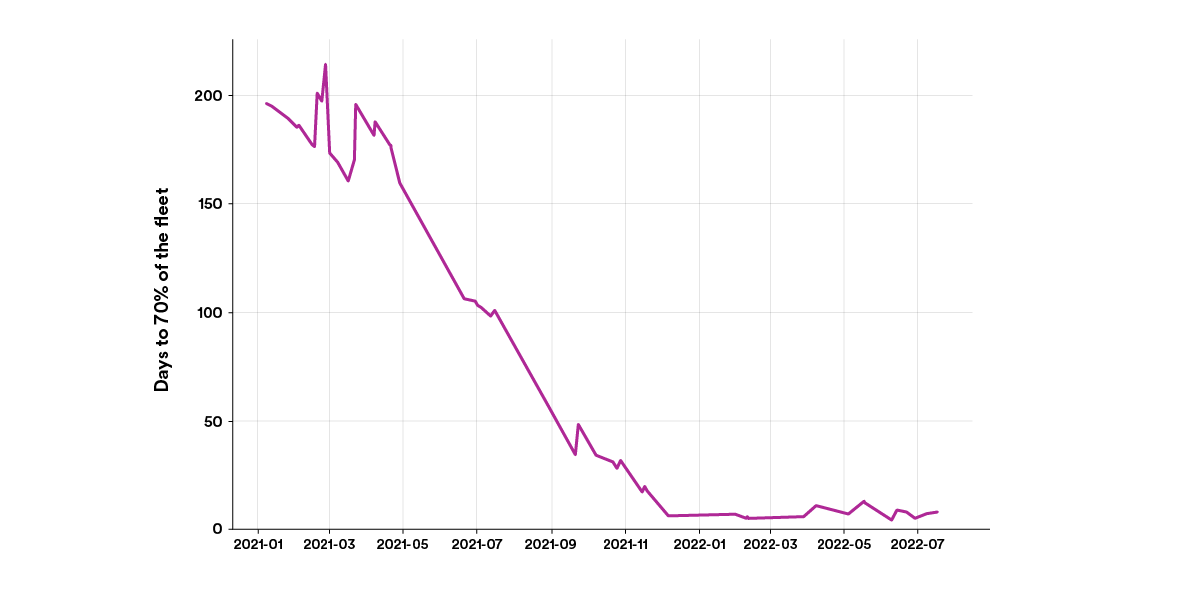
More importantly than the amount of code changed or pull requests generated is the measurable impact that these tools and new mindset have had on our ability to roll out changes across our fleet. As mentioned in the first post in this series, the amount of time taken for new releases of our internal backend service framework to be used in 70+% of deployed services has dropped from about 200 days to less than 7 days, as shown in the graph below.
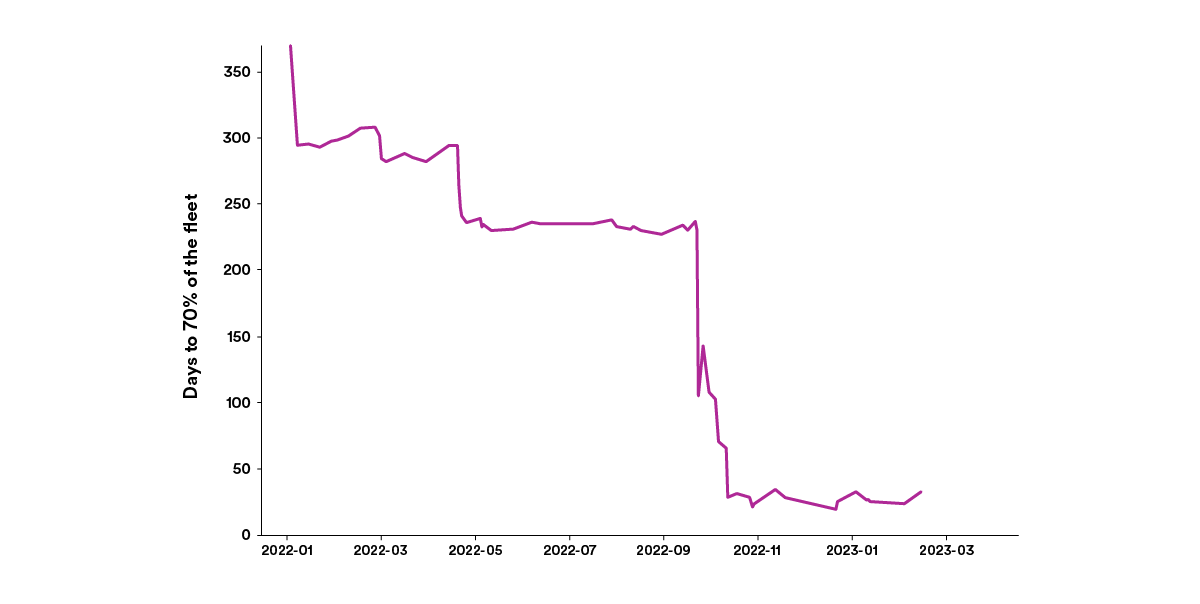
Similarly, the amount of time taken for new releases of Scio and our internal SBT plugin managing dependencies in batch data pipelines has dropped from around 300 days to about 30 days, as you can see below.
These examples are from two shifts of many — over the past 12 months, 49 distinct teams have used Fleetshift to send pull requests to other teams, with 27 teams sending PRs via Fleetshift over the past 30 days alone. In this time period, the median number of repos targeted by a shift is 46 repos and 22 shifts have changed code in a thousand or more repos.
Establishing Fleetshift as our standard tool for fleet-wide refactoring with a team maintaining it full-time has been an important part of getting teams to embrace the fleet-first mindset. There is no longer a need for teams to ask what tools they can use to change code outside of their control, and we see that teams planning for new releases or breaking changes are now actively planning for how to roll out that change with Fleetshift.
While we are pleased with the progress so far, we want to take fleet-wide refactoring a lot further in the future. We are always looking for ways to lower the learning curve for writing nontrivial code refactorings, to make it easier for teams to get started with Fleetshift and to allow teams to be more ambitious with API deprecations and code migrations. There is also a lot we can do to make it easier for shift authors to search for the code that needs refactoring — writing SQL to query code stored in BigQuery tables is not the most straightforward task. Lastly, while we typically have many repos containing one or a few components each, a significant portion of our codebase resides in monorepos, where many teams are working in the same repo (such as our client/mobile codebases) — a workflow that is not adequately supported by Fleetshift today.
This post is the last in our series on Fleet Management. We have many challenges remaining in our Fleet Management effort, so expect to hear more from us in the future. If you are interested in this work or are building something similar yourself, we’d love to hear from you – please get in touch.
Acknowledgments
The progress and tools discussed in this post were a result of hard work from a lot of people over the past few years. Many thanks to Andy Beane, Brian Lim, Carolina Almirola, Charlie Rudenstål, Dana Yang, Daniel Norberg, Daynesh Mangal, Diana Ring, Gianluca Brindisi, Henry Stanley, Hongxin Liang, Ilias Chatzidrosos, Jack Edmonds, Jonatan Dahl, Matt Brown, Meera Srinivasan, Niklas Gustavsson, Orcun Berkem, Sanjana Seetharam, Tommy Ulfsparre, and Yavor Paunov.
Apache Maven is a trademark of the Apache Software Foundation.
Docker is a registered trademark of Docker, Inc.
Kubernetes is a registered trademark of the Linux Foundation in the United States and other countries.
Google Cloud Bigtable and Dataflow are trademarks of Google LLC.
SHARE THIS ARTICLE



