Testing of Microservices

Why do we write tests?
Most people would say that we write tests to verify that things work as we expect them to.
While that is true, it’s not the whole truth. After all, that can be verified through manual tests as well.
So there has to be something more to it.
Anyone who has ever done manual testing knows that it’s slow, boring and error-prone. By writing automated tests we are trying to remove — or at the very least improve — on these pain points.
We want to move fast, with confidence that things work. That’s why tests should:
- Give us confidence that the code does what it should.
- Provide feedback that is fast, accurate, reliable and predictable.
- Make maintenance easier, something that is commonly overlooked when writing tests.
In a Microservices world, achieving all three of these becomes an art. Let’s first take a look at the traditional test strategy and where it fails us, so that we can move on to how to be successful in testing Microservices.
Traditional test strategy
Most people are familiar with the famous Testing Pyramid.
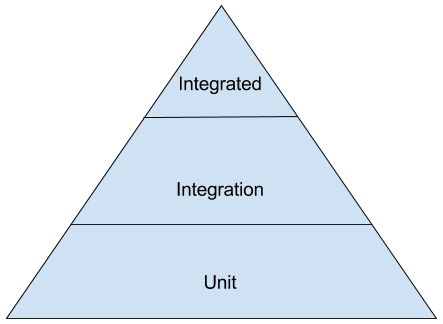
For a long time this was an extremely efficient way to organize tests. In a Microservices world, this is no longer the case, and we would argue that it can be actively harmful.
The biggest complexity in a Microservice is not within the service itself, but in how it interacts with others, and that deserves special attention.
Having too many unit tests in Microservices, which are small by definition, also restricts how we can change the code without also having to change the tests. By having to change the tests we lose some confidence that the code still does what it should and it has a negative impact on the speed we iterate at.
Microservices test strategy
A more fitting way of structuring our tests for Microservices would be the Testing Honeycomb.
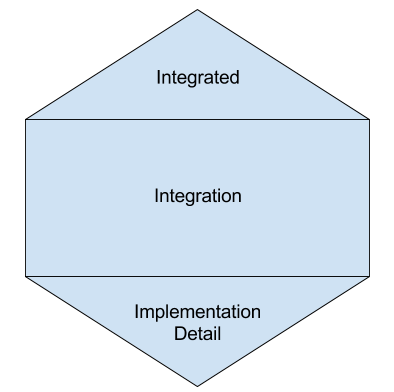
That means we should focus on Integration Tests, have a few Implementation Detail Tests and even fewer Integrated Tests (ideally none).
Integrated Tests
Using the very excellent presentation by J.B. Rainsberger — Integrated Tests Are A Scam, we define an Integrated Test as:
A test that will pass or fail based on the correctness of another system.
Some signs of having Integrated Tests are:
- We spin up other services in a local testing environment
- We test against other services in a shared testing environment
- Changes to your system breaks tests for other systems
This is a quite fragile way of testing and we recommend learning more directly from the source above.
Integration Tests
What we should aim for instead is Integration Tests, which verify the correctness of our service in a more isolated fashion while focusing on the interaction points and making them very explicit.
Let’s use some services we have at Spotify as real life examples.
We’ll start with a very simple service that only depends on a SQL database and provides a REST API to a client.

All tests in the project follow the exact same pattern. We spin up a database, populate it, start the service, and query the actual API in the tests. This service has no Implementation Detail tests at all, because we don’t need them.
Having Implementation Detail Tests there would just be in the way. Now we are able to refactor the internals without touching any tests. We could even replace the database from PostgreSQL to NoSQL without having to modify the actual test methods. The only thing that would need to change is the test setup.
The whole test suite ends up not having very many tests, and we are confident that they are accurate, relevant and enough.
The trade-off here is some loss of speed in test execution. The suite goes from milliseconds to a few seconds, but we strongly feel that the increased speed of coding and ease of maintenance more than makes up for it.
That was a very simple service, does it work for more complex services? We say yes.
Let’s take a look at a more complex service. It consumes events from several different sources, all with their own quirks. It then collates this data into the models it needs, and stores them in a database. On the other end, the service provides a REST API for a React application.
To give a better picture, the system diagram looks like this:

Since events can arrive in any order, and any subset of events should build a valid model, verifying all code paths in a white-box manner would be very hard.
Instead, we put messages on an in-memory pubsub topic, consume them, and verify that the output in the API looks correct.
Note: In the interest of brevity we have omitted some setting of variables.

The tests don’t get more complicated than that. They may have more or fewer messages published, but the structure remains. For adding new tests we just need to focus on messages and API fixtures. This is in line with our focus on the interaction points, as we emphasize and exercise well both input and output of the service.
The trade-off here is that we might lose some feedback accuracy when a test fails, as the assertion only tells the difference in the actual and expected values. To find the actual cause we see ourselves following the stacktraces coming from within the service. Again, in practice we feel the benefits outweigh this.
So, when to use Implementation Detail Tests?
We save Implementation Detail Tests for parts of the code that are naturally isolated and have an internal complexity of their own.
An example we have is parsing our CI Build log file to give meaningful feedback to the users so they don’t need to go through the logs and search for issues themselves. Needless to say, log parsing is complex. Using Implementation Detail Tests here saves us from having an Integration Test for every possible build issue. Instead we have one Integration Test covering a failing build that makes sure the correct error message field is present. The Implementation Detail Tests cover the different failure scenarios we look for in the log file, and ensure that we parse them as expected.
Final Thoughts
So how does this match with what we aim to achieve when writing tests?
- Give us confidence that the code does what it should.
- Since we use realistic fixtures as inputs and expected outputs, we know that no matter what the code looks like inside, it does what it should.
- Provide feedback that is fast, accurate, reliable and predictable.
- Like we’ve mentioned, this is probably where we fall a bit short. The feedback we get is fast enough, but when tests fail we sometimes find ourselves following the stacktraces from the service rather than only the assertion.
- Make maintenance easier, something that is commonly overlooked when writing tests.
- Since we test from the edges we can do maintenance and boy scout the code (leave it cleaner than you found it) with confidence that we don’t break it. And we go really fast.
As an added bonus, since we reuse the same fixtures for other services we increase confidence that we won’t accidentally break the contracts between them. They will also be the basis for when we take the leap to Consumer-driven Contract Based Testing (e.g. PACT), getting even more confident of not accidentally breaking contracts.
By the way, you may have noticed that what we’ve been treating the Microservice as an isolated Component, tested through its contracts. In that sense the Microservice has become our new Unit, which is why we have avoided the use of the term Unit Tests for Microservices in favour of Implementation Detail Tests.
Microservices take the old idea of isolated components and show us what the abstractions should be. It is time we take advantage of that and apply our testing to the correct points.
Happy Testing!
André Schaffer & Rickard Dybeck
Tags: Data




