Tech Migrations, the Spotify Way
Stuck in the long tail
In our experience, big technology upgrade efforts or migrations (as we fondly call them at Spotify) gear up with a lot of momentum in the beginning but tend to get stuck in the mud over time, eventually leading to a long tail of systems still left running on older versions. This is one of the ways fragmentation creeps into your tech infrastructure, like weeds sprouting in a garden — left unattended, forget about those flowers!
About a year and a half ago at Spotify, we started addressing this problem head on. In this post, we’ll share our approach, some insights we’ve gleaned, and where we’re going next.
More carrot, less stick
Before going too deep, we should acknowledge that a company’s engineering culture is going to play a big role in how this problem is perceived and how it’s handled. At Spotify we have three hundred or so engineering teams (or ‘squads’ as we call them) spread around the globe, and we tend to motivate ourselves more with carrots and less with sticks. We’ve seen a lot of success explaining, in creative ways, why a technology upgrade matters and how it helps our engineering community rather than doubling down on a mandate. That’s been our style, and a lot of what follows is going to reflect that desire to strike a balance between engineering autonomy and a healthy techscape.
Going back in time
Before we talk about what we did to make things better, we want to take you all the way back to the year 2017. At that point, each team in our infrastructure and developer tooling organization (called “Platform Mission”) would send emails to engineers across the company, saying something like, “MUST READ: COMPONENT WILL BE DEPRECATED”, often on a short deadline. Each team in Platform that was responsible for an internal tool or service might send a different email indicating that their customers need to migrate from one version to another or to an entirely different solution. Sound familiar?
As you can imagine, this created a lot of confusion. Our customers were overwhelmed by the sheer number of such emails, and trying to keep track of what to do proved to be a significant time sink. Additionally, these emails sometimes lacked helpful information such as technical documentation on what needed to be upgraded or migrated and how. We realized we needed to take a fresh look at the problem.
Adieu, long tail
After some experimentation, we landed on a three-part strategy to make migrations more efficient.
1. Ruthlessly prioritize
The first part was to ensure we had the right prioritization processes at the company (note: this is easier said than done when you work in an engineering culture that values a high degree of autonomy). A critical part of this process was putting together a single, company-wide migrations map with priorities that were negotiated with TAG, Spotify’s technical architecture group. The migrations map allows us to keep a contract with our customers: we estimate the cost of a migration before putting it on the map, identify who is impacted, and set deadlines (timelines are especially crucial).
All of this helps prevent our infrastructure org from overwhelming engineering teams with work that isn’t absolutely crucial, freeing up more time for squads to iterate on business features. Oh, and all those darn emails about migrations? They go away and get consolidated into streamlined communication. We have a page in Backstage, our homegrown and now open source developer portal, where engineers can see which migrations are scheduled for current and future quarters.
It’s important to mention that this work — aligning all of the 45+ infrastructure product managers and hundreds of engineers — took time and a lot of patience. But one of the most effective data points we leveraged to get folks to see the bigger picture was that many of the migrations or upgrades that should’ve taken weeks were taking months or longer. All because our customers, the teams needing to do the migrations, were overwhelmed or paralyzed with the amount of information being thrown at them.
2. Product-ify migrations
Within our Platform organization we are believers in building a strong product management function, and we’ve hired some exceptional PMs along the way who’ve helped to set our strategy and execute on that vision. We realized we needed to take the same product mindset with technology migrations. What this means in practice:
Accountability: Each migration is owned by a PM. He/she is responsible for the success of the migration and follows up on its progress. Yes, that’s right — we have product managers specifically focused on driving migrations, along with the more typical work of helping to drive the success of their product area.
Test first: We alpha and beta test with small groups before we go for primetime (and add an item to the migrations map). While this may seem unnecessary, in order to maintain trust with our customers, it’s important that they feel like the time and effort they spend on migrations won’t be wasted due to a faulty or half-baked product. We don’t always get it right — that’s the nature of software. But by containing the blast radius and iterating on internal services or tools before we set them free to our customers, we’ve been able to release higher quality internal products, which ultimately enables productivity and faster migrations across our ecosystem.
Train: We work with our internal Tech Learning function to develop any needed training programs (say, for example, if we’re migrating from one coding language or another or to a different service framework). While we don’t do this for every migration, we tend to provide this training for technologies that are newer to our knowledge base. This makes migrations feel less scary to engineers who have worked on the legacy systems or tools for years.
Lead with value: From the get-go we work with PMMs, our internal product marketing managers, on making sure we’re communicating the benefits of a migration from a productivity, cost, and scalability perspective. As an infrastructure and developer tooling team, it’s easy to assume that everyone has as much context about why a particular version of a language or tool is better than another. This is simply not true. By putting in extra effort to explain why a certain technology is worth investing the time to adopt — not only to engineers but also engineering managers and senior leadership — getting tech health-related activities on everyone’s sprints becomes that much easier.
KYC (Know your customers): PMs know their customers and different customers segments. Instead of a one-size-fits-all approach, PMs drive targeted plans to help teams wherever they are.
Gamify: In Backstage we have a plugin called Tech Insights, which allows engineers to see the progress of migrations. We break these down by tribes and squads, so teams can easily see where they’re at compared to everyone else. Below is a snapshot of a single tribe at Spotify with respect to current migrations:
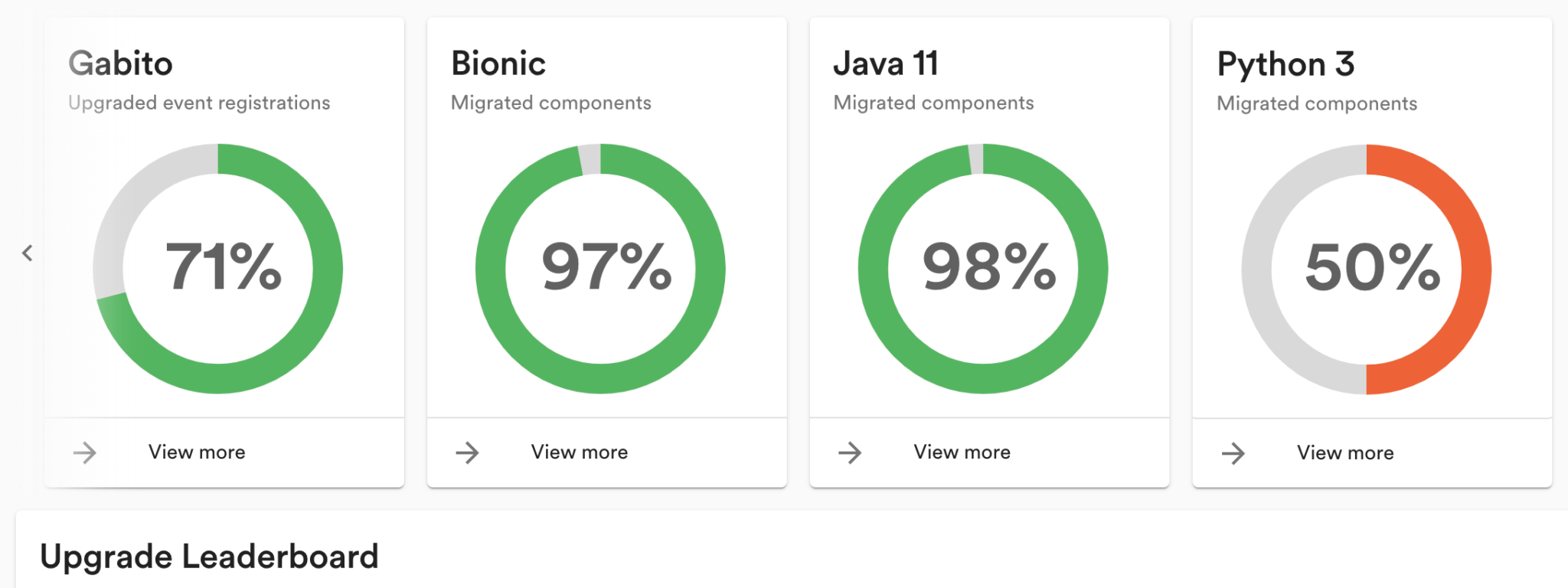
Lastly, and perhaps most importantly, we drive the migration until it’s 100% complete, as doing so means we can drive down the overall fragmentation in our techscape. Getting there might mean we need to give special attention to the long tail — working hands-on with the last remaining teams to get everyone over the finish line. This can get really tedious, but we believe it’s well worth the effort in the long run.
3. Automate, automate, and move up the stack!
The last part of our strategy is all about automation. Our goal is to automate as much as we can to make migrations from one tech stack to another a seamless experience. Sometimes we’re able to do this without teams needing to know that an underlying infrastructure component (for example, Puppet version) is changing across the fleet. Where we can’t make the experience fully seamless we send automated PRs for teams to review and merge.
Going forward
Our goal is to remove the need to expose our engineering teams to 99% of migrations. We aim to do this by providing more tools in our platform that are higher up the stack, where underlying infrastructure components aren’t directly exposed to our customers.
This has been a long journey and we’ve learned a lot along the way. We hope our failures and learnings will inspire you to remove some long standing tech debt. May you migrate in peace!
SHARE THIS ARTICLE



