Meet Basic Pitch: Spotify’s Open Source Audio-to-MIDI Converter

Introducing Basic Pitch, Spotify’s free open source tool for converting audio into MIDI. Basic Pitch uses machine learning to transcribe the musical notes in a recording. Drop a recording of almost any instrument, including your voice, then get back a MIDI version, just like that. Unlike similar ML models, Basic Pitch is not only versatile and accurate, but also fast and computationally lightweight. It was built for artists and producers who want an easy way to turn their recorded ideas into MIDI, a standard for representing notes used in digital music production.
Basic Pitch is not your average MIDI converter
For the past 40 years, musicians have been using computers to compose, produce, and perform music, everywhere from bedrooms to concert halls. Most of this computer-based music uses a digital standard called MIDI (pronounced “MID-ee”). MIDI acts like sheet music for computers — it describes what notes are played and when — in a format that’s easy to edit. Did a note sound weird in that chord you played? Change it with a click.
While MIDI is used by nearly all modern musicians, creating compositions from scratch with MIDI can be a challenge. Usually, musicians have to produce MIDI notes using some sort of computer interface, like a MIDI keyboard, or by typing the notes into their software by hand. This is because live performances on real instruments are typically difficult for a computer to interpret: once a performance has been recorded, the individual notes that were played are tricky to separate and identify.
This is a real problem for musicians who primarily sing their ideas, but aren’t familiar with piano keyboards or complex music software. For other musicians, having to compose on a MIDI keyboard or manually assembling an entire MIDI score note by note, mouse click by mouse click, can be creatively constraining and tedious.
Mighty, speedy, and more expressive MIDI
To solve this problem, researchers at Spotify’s Audio Intelligence Lab teamed up with our friends at Soundtrap to build Basic Pitch — a machine learning model that turns a variety of instrumental performances into MIDI.
While other note-detection systems have existed for years, Basic Pitch offers a number of advantages:
Polyphonic + instrument-agnostic: Unlike most other note-detection algorithms, Basic Pitch can track multiple notes at a time and across various instruments, including piano, guitar, and ocarina. Many systems limit users to only monophonic output (one note at a time, like a single vocal melody), or are built for only one kind of instrument.
Pitch bend detection: Instruments, like guitar or the human voice, allow for more expressiveness through pitch bending: vibrato, glissando, bends, slides, etc. However, this valuable information is often lost when turning audio into MIDI. Basic Pitch supports this right out of the box.
Speed: Basic Pitch is light on resources, and is able to run faster than real time on most modern computers (Bittner et al. 2022).
By combining these properties, Basic Pitch lets you take input from a variety of instruments and easily turn it into MIDI output, with a high degree of nuance and accuracy. The MIDI output can then be imported into a digital audio workstation for further adjustments.

Comparing nuance and accuracy using a guitar example. Top: Human-Created MIDI. Bottom: The output of Basic Pitch.
Basic Pitch gives musicians and audio producers access to the power and flexibility of MIDI, whether they own specialized MIDI gear or not. So now they can capture their ideas whenever inspiration strikes and get a head start on their compositions using the instrument of their choice, whether that’s guitar, flugelhorn, or their own voice.
Easy peasy! Well…
Does better always have to mean bigger?
To build Basic Pitch, we trained a neural network to predict MIDI note events given audio input. In general, it’s hard to make systems that are both accurate and efficient. Usually in ML, to make things more accurate, the easiest way is to add more data and make our models bigger.
When we look around at popular ML models today, we see a tendency toward computationally extreme solutions. Think OpenAI’s Jukebox with its billions of parameters, or DALL-E and its 12 billion parameters, or Meta’s OPT-175B, a 175-billion-parameter large language model. Large models with targeted use cases can have very good results: using a dataset with tons of piano audio will be effective at recognizing piano input.
But we wanted a model that could work with input from a variety of instruments and polyphonic recordings to create a tool that’s useful for piano virtuosos as well as shower crooners. Did that automatically mean building a mega model? Or, could we build a model that did more (recognize notes played by a much wider range of instruments), but that was also lighter, and just as accurate, as a heavier, more power-hungry solution?
That was the challenge we set for ourselves. But to accomplish that, we would have to address a number of transcription problems specific to music.
Music, musicians, and machine learning
Since we set out to build this tool for musicians, not just researchers, we knew speed was important. No matter how impressive your ML model, no one enjoys waiting around for the results, especially if they’re in the middle of doing something creative. Inspiration doesn’t like progress bars.
Reducing the model size would help with speed. But the goal of creating a fast, light, and accurate ML model presented a few challenges that are specific to music audio:
When music is polyphonic, lots of the sounds overlap in both time and frequency. For example, if a piano plays C3 and C4 at the same time, the notes share a lot of similar harmonic frequency content. This makes it hard to “untangle”.
It’s not always easy to know when to group pitches into a single note, or when to break them into multiple notes. In the example clip below?, listen to the way the singer scoops around different notes in “sooooong” and “aboooout”, etc. How many notes are there in the word “song”? Two, three…five-ish? Depending on who you are, you might hear it differently.
It’s hard to make an ML system that transcribes any instrument well. There are some really good models out there for instruments like the piano. Even making a model that transcribes any type of piano well is difficult. (Think about all the different sound qualities of different piano recordings — a Steinway grand in a concert hall, an out-of-tune upright in a honky-tonk, etc.). It’s even harder to make a model that works well on any instrument, which ranges from a kazoo to a soprano opera singer.
So how did we do?
An ML model with a lightweight footprint
In the end, the model for Basic Pitch was made to be lightweight by using a combination of tricks drawing on past research from Spotify’s Audio Intelligence Lab and other researchers, including:
Using a harmonic constant-Q transform as input (Bittner et al. 2017, Balhar 2018)
Jointly modeling the onsets, frames (Kelz et al. 2016, Hawthorne et al. 2018), and multipitch information (Bittner et al. 2017)
Just using fewer layers and fewer parameters!
In our experiments, the shallow architecture and the tricks above resulted in a lightweight model with a high level of accuracy.
Shallow architecture
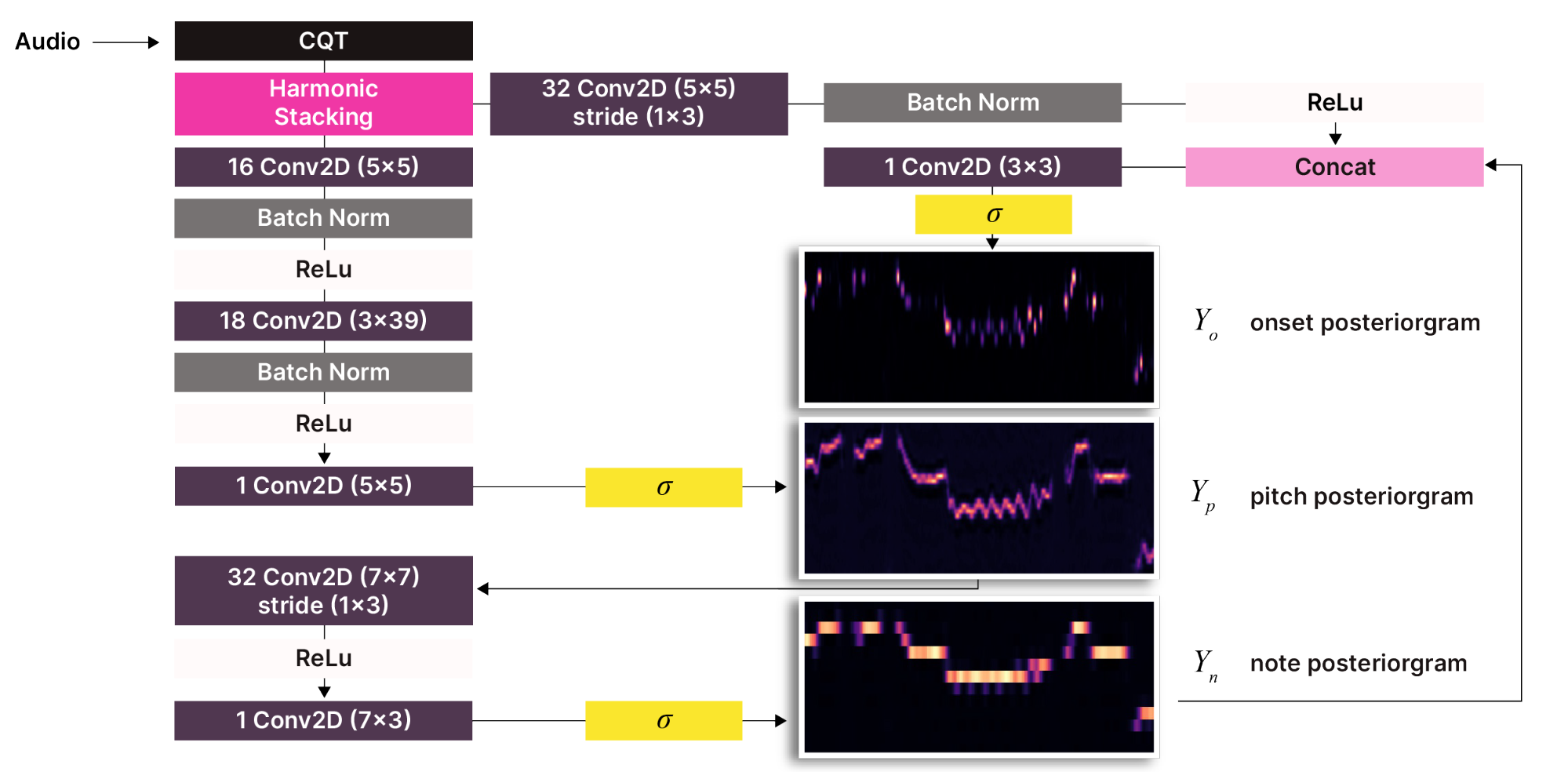
In order to allow for a small model, Basic Pitch was built with a harmonic stacking layer and three types of outputs: onsets, notes, and pitch bends.
Compared to other AI systems, which can require massive amounts of energy-intensive processing to run, Basic Pitch is positively svelte, at <20 MB peak memory and <17K parameters. (Yes: 17,000, not 17 billion!)
Greater versatility, comparable accuracy
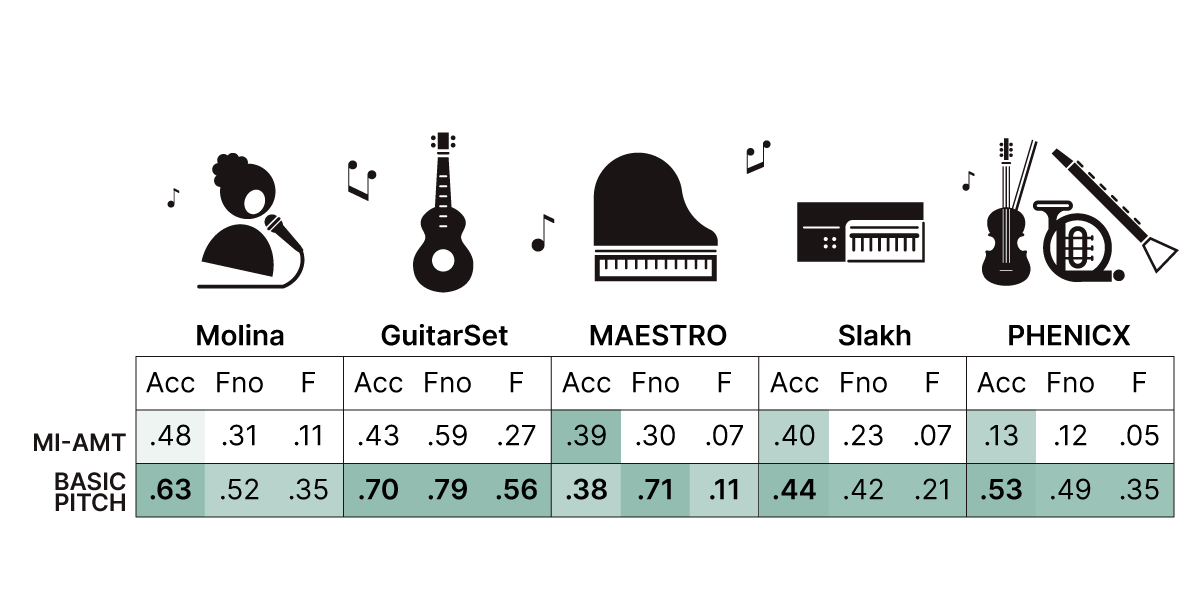
MI-AMT (baseline model) vs Basic Pitch: Accuracy scores for processing datasets of various instrument types. Datasets used for benchmarking only. For more details, see our ICASSP paper.
State-of-the-art systems are typically built for one specific instrument type, but Basic Pitch is both accurate and versatile. As seen in our experimental results above, Basic Pitch performed well at detecting notes from various instrument types, including vocal performances (the Molina dataset in the first column), which can be especially tricky to get right.
Try the demo at basicpitch.io
Basic Pitch is so simple, it even works in your web browser: head on over to basicpitch.io to try it out without downloading anything. For those interested in more details:
We’ve open sourced the Basic Pitch model on GitHub for the Pythonistas.
We presented a paper on our model at ICASSP 2022.
Check out a video of our ICASSP presentation.
Made for creators, shared with everyone
Originally, we set out to develop Basic Pitch exclusively for Soundtrap and its community of artists and audio producers. But we wanted to share it with even more creators, whether they were musicians, developers, or both. So we open sourced the model and made the tool available online for anyone to use.
Right now, Basic Pitch gives musicians a great starting point for transcriptions, instead of having to write all their musical ideas down manually from scratch or buying extra MIDI hardware. This library comes with a standard open source license and can be used for any purpose, including integrating it with other music production tools. We can also imagine how the model could be integrated into real-time systems — for example, allowing a live performance to be automatically accompanied by other MIDI instruments that “react” to what the performer is playing.
We also wanted to share our approach for building lightweight models so other ML researchers might be inspired to do the same. For certain use cases, the large, computationally heavy, and energy-hungry models make sense. Sometimes they’re the best and only solution. But we don’t think this should be the only approach — and certainly not the default one. If you go in thinking you can create a leaner ML model, you probably can (and should ?).
Now that Basic Pitch is out there for music creators, software engineers, and researchers to use, develop, and build upon, we can’t wait to see what everyone does with it. No matter how much we test a model in our experiments, there’s still nothing like seeing how it performs out in the wild, with real-world use cases. In this initial version of Basic Pitch, we expect to discover many areas for improvement, along with new possibilities for how it could be used.
Want to help us improve Basic Pitch or have an idea for building something great with it (like this free VST/AU plugin — built with the audio to MIDI capabilities of Basic Pitch — for your favorite DAW)? Let us know in the repo!
Basic Pitch was built by:
Rachel Bittner, Juanjo Bosch, Vincent Degroote, Brian Dombrowski, Simon Durand, Sebastian Ewert, Gabriel Meseguer Brocal, Nicola Montecchio, Adam Rackis, David Rubinstein, Ching Sung, Scott Sheffield, Peter Sobot, Daniel Stoller, Charae Tongg, and Jan Van Balen
References
Balhar, Jirí and Jan Hajič, Jr. “Melody Extraction Using a Harmonic Convolutional Neural Network.” (2018).
Bittner, Rachel, Juan José Bosch, David Rubinstein, Gabriel Meseguer-Brocal, and Sebastian Ewert. “A Lightweight Instrument-Agnostic Model for Polyphonic Note Transcription and Multipitch Estimation.” 47th International Conference on Acoustics, Speech and Signal Processing (May 2022).
Bittner, Rachel, Brian McFee, Justin Salamon, Peter Li, and Juan P. Bello. “Deep Salience Representations for f0 Estimation in Polyphonic Music.” 18th International Society for Music Information Retrieval Conference (October 2017).
Hawthorne, Curtis, Erich Elsen, Jialin Song, Adam Roberts, Ian Simon, Colin Raffel, Jesse Engel, Sageev Oore, and Douglas Eck. “Onsets and Frames: Dual-Objective Piano Transcription.” (2018).
Kelz, Rainer, Matthias Dorfer, Filip Korzeniowski, Sebastian Böck, Andreas Arzt, and Gerhard Widmer. “On the Potential of Simple Framewise Approaches to Piano Transcription.” (December 2016).
SHARE THIS ARTICLE