Incident Report: Spotify Outage on January 14, 2023

On January 14, between 00:15 UTC and 03:45 UTC, Spotify suffered an outage. The impact was small at first and increased over the course of an hour until most functionality (including playback) was not working. Spotify engineers were first notified of the problem at 00:40 UTC, and our incident response team was immediately assembled. Due to the nature of the incident, triage took longer than one would expect; our internal tooling was inaccessible. At 02:00 UTC, the root cause had been identified and mitigation was underway. Service was fully restored at 03:45 UTC.
What happened?
The issue was triggered by scheduled maintenance of our Git repository (GitHub Enterprise, or GHE), causing our internal DNS resolvers, which are a critical component in our internal DNS infrastructure, to fail. The resolvers pull configuration from multiple sources, GHE included. The dependency between this DNS component and our Git repository was well-known, and there are multiple safeguards in place to handle Git outages.
However, a change was introduced in the DNS component, which set off a new failure mode that resulted in invalid configurations being applied to the DNS resolvers. GHE going down didn’t cause the outage — it was only as GHE was brought back up from maintenance that the invalid configuration was then applied across the resolver fleet over the course of an hour. When a resolver got an invalid configuration, it entered a crashloop and was unable to serve responses to internal DNS queries.
As DNS failures ramped up, internal services and production traffic started failing. Since internal tooling (including employee VPN) was also impacted, the response teams had to come up with novel troubleshooting methods, which caused a longer triage time than one would expect.
Timeline
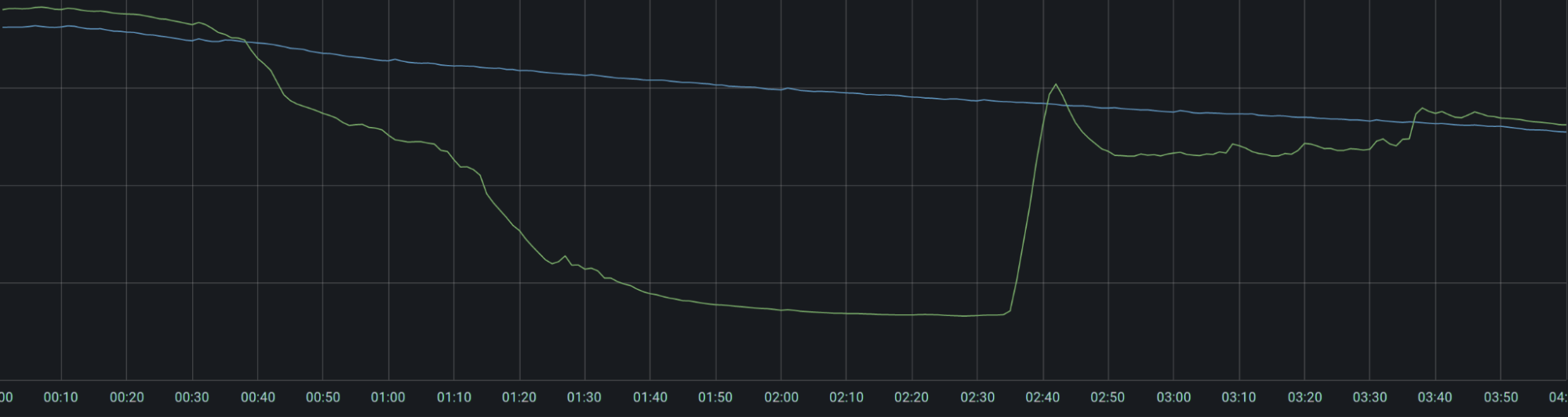
Traffic to a core service during the incident (green) and one week earlier (blue).
(All times are in UTC.)
00:15 UTC – DNS resolvers start to fail.
00:36 UTC – About 30% of DNS resolver fleet down, first signs of user impact.
00:40 UTC – Spotify platform engineers alerted by automatic monitoring.
01:15 UTC – 100% of our DNS resolver fleet down, severe impact.
02:00 UTC – Root cause identified.
02:15 UTC – Mitigation in place for internal tooling.
02:33 UTC – Mitigation in place for production traffic.
03:45 UTC – All core services recovered.
Where do we go from here?
We have fixed the bug that caused this outage.
We have made changes in multiple services and infrastructure that will improve resiliency against future DNS outages.
We plan to decommission the DNS component that failed, as part of an ongoing project aimed at removing complexity from our DNS infrastructure. We have increased the priority for this project.
SHARE THIS ARTICLE



