Experimenting with Machine Learning to Target In-App Messaging
Messaging at Spotify
At Spotify, we use messaging to communicate with our listeners all over the world. Our Messaging team powers and creates delightful foreground and background communications across the Spotify experience, experimenting with and tailoring the perfect journey for each user across our platform. Today we are able to send messages through WhatsApp, SMS, email, push notifications, contextual in-line formats, and other in-app messaging formats, like modals and full-screen takeovers.
In-app messaging at Spotify
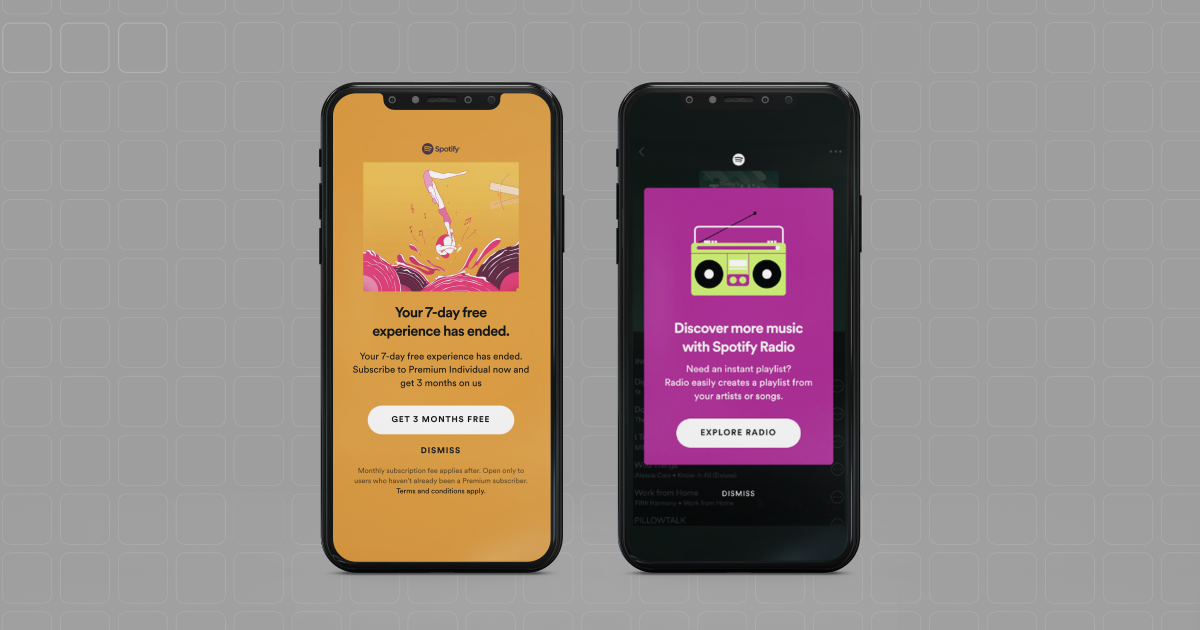
What we refer to as in-app messaging covers a range of different message formats, with the unifying trait that they all appear when the user is using the app. See below for some example in-app messages.
|
|


Figure 1: Two examples of in-app messages, showing different message formats.
This is possibly the most direct method we have for communicating with our users, which also means we need to be careful not to interrupt their listening experiences unnecessarily. We deliberately withhold in-app messaging for some users so that we can measure its overall effectiveness. These holdouts show that in-app messages have a mixed effect on user behavior when looking at the whole population, demonstrating that we would benefit from targeting users more selectively for in-app messaging.
We believed that we could use ML to decide in-app messaging eligibility and that by doing so we could improve user experience without harming business metrics. We discussed a number of possible solutions to this problem but decided to focus on uplift modeling, where we try to directly model the effect of in-app messaging on user behavior.
Heterogeneous treatment effect & uplift modeling
It’s clear that in-app messages have a different effect on different users, which is known as a heterogeneous treatment effect. We have some users that might enjoy Spotify Premium and would benefit from receiving a message prompting them to subscribe. We also have users that are happy with their current product offering, where messaging wouldn’t benefit either the user or Spotify. Our task, then, is to predict the effect of in-app messages on users. In particular, we wanted to understand the causal effectof sending in-app messages.

Figure 2: Users can react differently to our messaging.
The existing literature on causal inference is extensive, but in our case, such learning is relatively simple because we already have the randomly assigned holdout group discussed earlier. In the language of causal inference, we were able to use this holdout to measure the average treatment effect — i.e., the effect on user behavior averaged across the entire population of users.
Given our heterogeneous treatment effect, we want to target specifically those users that would benefit from in-app messages, meaning we need to be able to predict the conditional average treatment effect (CATE), given in equation form as:
CATE(x)=E[Y(1) - Y(0) | X=x]In this equation, Y(t) represents the outcome given treatment t and X represents the features used to identify different subgroups of users. The CATE is therefore the expected value of effect size conditioned on user features. As a machine learning (ML) problem, we want to train a model that approximates this function, which we can then use to decide which users to target for in-app messaging.
The tricky part here is that we cannot observe the CATE directly, because there is no way to both give and not give a user a treatment. Fortunately, we can use the same holdout data that we used for estimating the average treatment effect for training this model. We can observe user features, treatment assignment, and outcomes and use these to learn the uplift score using a so-called metalearner.
The two simplest forms of metalearner are the S-learner and the T-learner. In both formulations we have user features u and treatment values t. In the S-learner, we learn a model ŷ(u, t) and calculate the uplift as:
ŷ(u) = ŷ(u, 1) - ŷ(u, 0)This is contrasted with the T-learner, where we learn two models, ŷ0(u) and ŷ1(u), and calculate the uplift as:
ŷ(u) = ŷ1(u) - ŷ0(u)Our model
Our model takes inspiration from both the S-learner and the T-learner, as well as the multiheaded Dragonnet, in that we do not include the treatment as a feature for the model, but we also learn only one model. We have some shared part of the model, which is the same for both treatment and control, the output of which is fed into different prediction heads for each treatment.
This work is motivated by in-app messaging’s competing effects on different business metrics, so we care not only about two different treatments but also two different outcomes. We therefore end up with four different outputs from the model:

Figure 3: How we make eligibility decisions using our multiheaded model.
As Figure 3 above shows, for each user input, we calculate uplift for our two metrics of interest and then take a weighted average of these two outputs to produce a final uplift score, ŷ. If ŷ>0, then the user is considered eligible for in-app messaging. The value is chosen by hyperparameter tuning and some business logic.
For a given training example, we know the treatment chosen and therefore the expected outputs of exactly two of the heads. By conditioning the loss function on the action chosen, we can train a model on all four outputs simultaneously, with each example contributing to the update of exactly two heads as well as the common part of the model.
Offline evaluation
Before running an A/B test, we need to have a better idea of how the model performs. We could observe a decreasing loss on our held-out test set, but that wouldn’t inform us how the model would do on the task we actually want to use it for. In particular, we would like to know if using the model would have a significant impact on business metrics.
To understand our evaluation, it’s necessary first to understand some concepts related to contextual bandits. Without going into detail, in the bandit problem space we have an agent that chooses from available actions according to some policy in order to maximize some reward. A contextual bandit is essentially a model for selecting one out of a set of possible actions. In other words, a contextual bandit is a model that takes features and outputs an action or distribution over actions. It’s not much of a stretch to think about our model as a contextual bandit; deciding to allow messaging if the weighted average of uplift scores is above some threshold is a policy.
Using the same randomly collected holdout data used for training, we can use offline policy evaluation to evaluate a policy without running it on actual users. The three policies we care about are: send-to-all, send-to-none, and the uplift model. By doing this offline evaluation, we had at least some evidence that we would not be harming Spotify’s business by running this test on such an important channel of messaging.
Test and next steps
We A/B tested our model and saw a significant improvement in user retention, so we rolled out the model, and it has been in production since. The business value of the model is clear because of the sustained impact on user retention (as shown in the graph below); however, we think there is still more benefit to be gained from this work.

Figure 4: The effect of using our model on user retention over time.
We’ve seen in this blog post the application of principles from causal inference to target in-app messaging eligibility. We took inspiration from an existing uplift model architecture to do multi-task learning to balance different effects of in-app messaging on user behavior, and successfully rolled out this approach and are actively working on improving the model by allowing a more dynamic messaging diet, which we believe will bring greater value to both Spotify and our users.
SHARE THIS ARTICLE