December 8, 2015
ELS: latency based load balancer, part 1
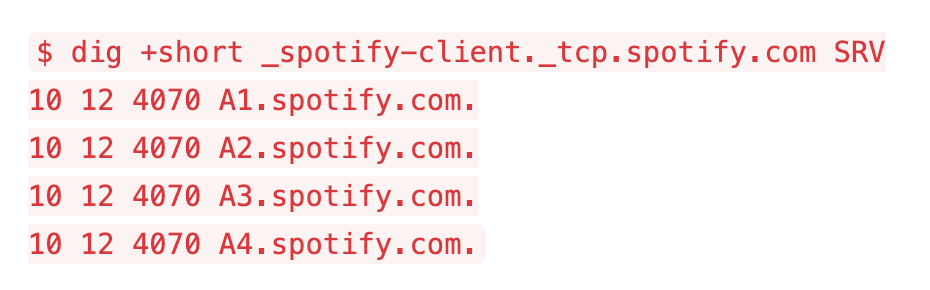
Load Balancing Most Spotify clients connect to our back-end via accesspoint which forwards client requests to other servers. In the picture below, the accesspoint has [...]
Published by Lukáš Poláček